新年伊始,NLP技术在2019年大放异彩,BERT,GPT-2,Mass,ElMo,ULMFit等预训练+精调的思维路线开辟了新的方向,也给我们这一块带来新的希望!
作为工程技术人员,我们首要就是要将更好的技术应用于产品,获取利润,那么可以在大佬的步伐下吃一波红利,指导应用开发。本人也比较懒,总结做的不是很好,就拿他山之石来说吧,希望能够给各位同行些许帮助。
信息来源:bert 时代与后时代的nlp,地址:http://www.360doc.com/content/19/0528/09/7673502_838692247.shtml(版本太多,姑且它了。感谢作者)
摘录里面重要的一节:
实践、观点、总结
实践与建议
虽然前面介绍的很多模型都能找到实现代码。但从可用性来说,对于NLU类型的问题,基本只需考虑ELMo,ULMFiT和BERT。而前两个没有中文的预训练模型,需要自己找数据做预训练。BERT有官方发布的中文预训练模型,很多深度学习框架也都有BERT的对应实现,而且BERT的效果一般是较好的。但BERT的问题是速度有点慢,使用12层的模型,对单个句子(30个字以内)的预测大概需要100~200毫秒。如果这个性能对你的应用没问题的话,建议直接用BERT。
对于分类问题,如果特定任务的标注数据量在几千到一两万,可以直接精调BERT,就算在CPU上跑几十个epoches也就一两天能完事,GPU上要快10倍以上。如果标注数据量过大或者觉得训练时间太长,可以使用特征抽取方式。先用BERT抽取出句子向量表达,后续的分类器只要读入这些向量即可。
我们目前在很多分类问题上测试了BERT的效果,确实比之前的模型都有提升,有些问题上提升很明显。下图给出了一些结果示例。
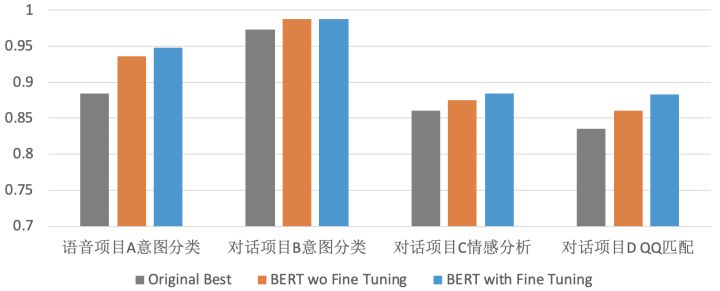
爱因互动作为企业对话机器人服务提供商,我们会处理很多的QA (Query Answer)和QQ (Query Question)匹配任务。比如在常用的检索机器人FAQBot中,用户的一个query来了,FAQBot首先从标准问答库中检索出一些候选问题/答案,然后排序或匹配模块再计算query跟每个候选问题/答案的匹配度,再按这些匹配度从高到低排序,top1的结果返回给用户。上图中给出了一个QQ 匹配的结果,原始模型的准确度为83.5%,BERT精调后的模型准确度提升到88.3%。
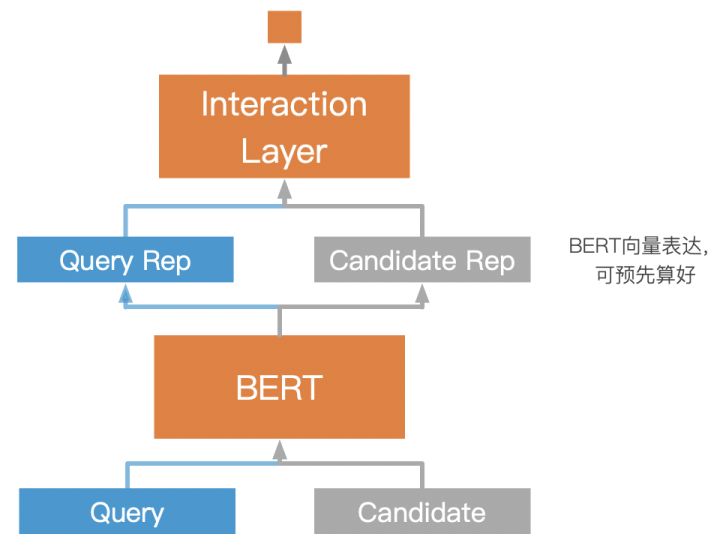
BERT当然可以直接用来计算两个句子的匹配度,只要把query和每个候选句子拼起来,然后走一遍BERT就能算出匹配度。这样做的问题是,如果有100个候选结果,就要算100次,就算把它们打包一起算,CPU上的时间开销在线上场景也是扛不住的。但如果使用Siamese结构,我们就可以把候选句子的BERT向量表达预先算好,然后线上只需要计算query的BERT向量表达,然后再计算query和候选句子向量的匹配度即可,这样时间消耗就可以控制在200ms以内了。
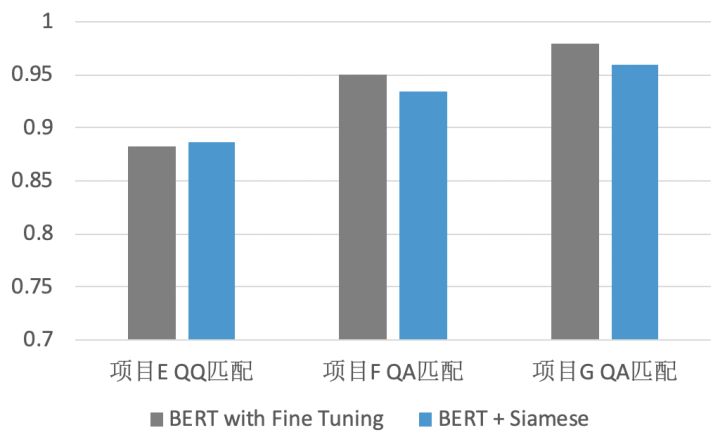
使用Siamese这种结构理论上会降低最终的匹配效果,之前也有相关工作验证过在一些问题上确实如此。我们目前在自己的三个数据上做了对比实验(见下图),发现在两个问题上效果确实略有下降,而在另一个问题上效果基本保持不变。我估计只要后续交互层设计的合理,Siamese结构不会比原始BERT精调差很多。
观点
按理ELMo的想法很简单,也没什么模型创新,为什么之前就没人做出来然后引爆无监督模型预训练方向?BERT的一作Jacob Devlin认为主要原因是之前使用的数据不够多,模型不够大。无监督预训练要获得好效果,付出的代价需要比有监督训练大到1000到10w倍才能获得好的效果。之前没人想到要把数据和模型规模提高这么多。
为了让预训练的模型能对多种下游任务都有帮助,也即预训练模型要足够通用,模型就不能仅仅只学到带背景的词表示这个信息,还需要学到很多其他信息。而预测被mask的词,就可能要求模型学到很多信息,句法的,语义的等等。所以,相对于只解决某个下游特定任务,预训练模型要通用的话,就要大很多。目前发现只要使用更多(数量更多、质量更好、覆盖面更广)的无监督数据训练更大的模型,最终效果就会更优。目前还不知道这个趋势的极限在什么量级。
BERT虽然对NLU的各类任务都提升很大,但目前依旧存在很多待验证的问题。比如如何更高效地进行预训练和线上预测使用,如何融合更长的背景和结构化知识,如何在多模态场景下使用,在BERT之后追加各种任务相关的模块是否能带来额外收益等等。这些机会我在第一部分已经讲到,就不再赘述了。
总结和一点感(敢)想
最后,简单总结一下。
无监督预训练技术已经在NLP中得到了广泛验证。BERT成功应用于各种NLU类型的任务,但无法直接用于NLG类型的任务。微软最近的工作MASS把BERT推广到NLG类型任务,而UNILM既适用于NLU也适用于NLG任务,效果还比BERT好一点点。
相信未来NLP的很多工作都会围绕以下这个流程的优化展开:
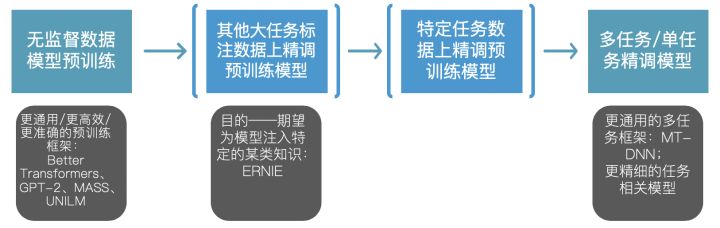
在这个过程中,我们还收获了诸多副产品:
相对于biLSTM,Transformers在知识抽取和存储上效果更好,潜力还可发掘。它们之间的具体比较,推荐俊林老师的“放弃幻想,全面拥抱Transformer:自然语言处理三大特征抽取器(CNN/RNN/TF)比较”,里面介绍的很清楚。
目前无监督模型预训练常用以下几种目标函数:
一般的LM。基于token的交叉熵。
Masked LM。相比于一般的LM,masked LM能够使用双向tokens,且在模型训练和预测时的数据使用方式更接近,降低了它们之间的gap。
Consecutive masked LM。Mask时不仅随机mask部分离散的token,还随机mask一些连续的tokens,如bi-grams、tri-grams等。这种consecutive mask机制是否能带来普遍效果提升,还待验证。
Next Sentence Prediction。预测连续的两个句子是否有前后关系。
精调阶段,除了任务相关的目标函数,还可以考虑把LM作为辅助目标加到目标函数中。加入LM辅助目标能降低模型对已学到知识的遗忘速度,提升模型收敛速度,有些时候还能提升模型的精度。精调阶段,学习率建议使用linear warmup and linear decay机制,降低模型对已学到知识的遗忘速度。如果要精调效果,可以考虑ULMFiT中引入的gradual unfreezing和discriminative fine-tuning:机制。
使用数量更多、质量更好、覆盖面更广的无监督数据训练更大的模型,最终效果就会更优。目前还不知道这个趋势的极限在什么地方。
最后说一点自己的感想。
NLP中有一部分工作是在做人类知识或人类常识的结构化表示。有了结构化表示后,使用时再想办法把这些表示注入到特定的使用场景中。比如知识图谱的目标就是用结构化的语义网络来表达人类的所有知识。这种结构化表示理论上真的靠谱吗?人类的知识真的能完全用结构化信息清晰表示出来吗?显然是不能,我想这点其实很多人都知道,只是在之前的技术水平下,也没有其他的方法能做的更好。所以这是个折中的临时方案。
无监督预训练技术的成功,说明语言的很多知识其实是可以以非结构化的方式被模型学习到并存储在模型中的,只是目前整个过程我们并不理解,还是黑盒。相信以后很多其他方面的知识也能找到类似的非结构化方案。所以我估计知识图谱这类折中方案会逐渐被替代掉。当然,这只是我个人的理解或者疑惑,仅供他人参考。