python的内存管理机制
关于python的存储问题
(1)由于python中万物皆对象,所以python的存储问题是对象的存储问题,并且对于每个对象,python会分配一块内存空间去存储它
(2)对于整数和短小的字符等,python会执行缓存机制,即将这些对象进行缓存,不会为相同的对象分配多个内存空间
(3)容器对象,如列表、元组、字典等,存储的其他对象,仅仅是其他对象的引用,即地址,并不是这些对象本身
关于引用计数器
(1)一个对象会记录着引用自己的对象的个数,每增加一个引用,个数加一,每减少一个引用,个数减一
(2)查看引用对象个数的方法:导入sys模块,使用模块中的getrefcount(对象)方法,由于这里也是一个引用,故输出的结果多1
(3)增加引用个数的情况:1.对象被创建p = Person(),增加1;2.对象被引用p1 = p,增加1;3.对象被当作参数传入函数func(object),增加2,原因是函数中有两个属性在引用该对象;4.对象存储到容器对象中l = [p],增加1
(4)减少引用个数的情况:1.对象的别名被销毁del p,减少1;2.对象的别名被赋予其他对象,减少1;3.对象离开自己的作用域,如getrefcount(对象)方法,每次用完后,其对对象的那个引用就会被销毁,减少1;4.对象从容器对象中删除,或者容器对象被销毁,减少1
(5)引用计数器用法:
import sys
class Person(object):
pass
p = Person()
p1 = p
print(sys.getrefcount(p))
p2 = p1
print(sys.getrefcount(p))
p3 = p2
print(sys.getrefcount(p))
del p1
print(sys.getrefcount(p))
多一个引用,结果加1,销毁一个引用,结果减少1
(6)引用计数器机制:利用引用计数器方法,在检测到对象引用个数为0时,对普通的对象进行释放内存的机制
关于循环引用问题
(1)循环引用即对象之间进行相互引用,出现循环引用后,利用上述引用计数机制无法对循环引用中的对象进行释放空间,这就是循环引用问题
(2)循环引用形式:
class Person(object):
pass
class Dog(object):
pass
p = Person()
d = Dog()
p.pet = d
d.master = p
即对象p中的属性引用d,而对象d中属性同时来引用p,从而造成仅仅删除p和d对象,也无法释放其内存空间,因为他们依然在被引用。深入解释就是,循环引用后,p和d被引用个数为2,删除p和d对象后,两者被引用个数变为1,并不是0,而python只有在检查到一个对象的被引用个数为0时,才会自动释放其内存,所以这里无法释放p和d的内存空间
关于垃圾回收(底层层面--原理)
(1)垃圾回收的作用:从经过引用计数器机制后还没有被释放掉内存的对象中,找到循环引用对象,并释放掉其内存
(2)垃圾回收检测流程:
一.任何找到循环引用并释放内存:1.收集所有容器对象(循环引用只针对于容器对象,其他对象不会产生循环引用),使用双向链表(可以看作一个集合)对这些对象进行引用;2.针对每一个容器对象,使用变量gc_refs来记录当前对应的应用个数;3.对于每个容器对象,找到其正在引用的其他容器对象,并将这个被引用的容器对象引用计数减去1;4.经过步骤3后,检查所有容器对象的引用计数,若为0,则证明该容器对象是由于循环引用存活下来的,并对其进行销毁
二.如何提升查找循环引用过程的性能:由一可知,循环引用查找和销毁过程非常繁琐,要分别处理每一个容器对象,所以python考虑一种改善性能的做法,即分代回收。首先是一个假设--如果一个对象被检测了10次还没有被销毁,就减少对其的检测频率;基于这个假设,提出一套机制,即分代回收机制。
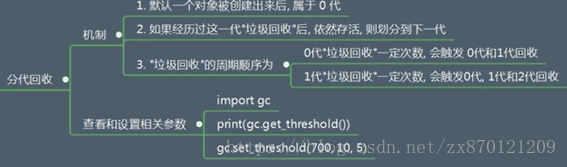
通过这个机制,循环引用处理过程就会得到很大的性能提升
关于垃圾回收时机(应用层面--重点)
(1)自动回收:
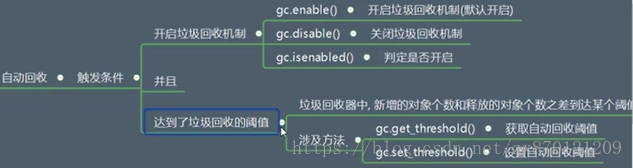
(2)手动回收:这里要使用gc模块中的collect()方法,使得执行这个方法时执行分代回收机制
import objgraph
import gc
import sys
class Person(object):
pass
class Dog(object):
pass
p = Person()
d = Dog()
p.pet = d
d.master = p
del p
del d
gc.collect()
print(objgraph.count("Person"))
print(objgraph.count("Dog"))
其中objgraph模块的count()方法是记录当前类产生的实例对象的个数
关于内存管理机制的总结(重点)
综上所述,python的内存管理机制就是引用计数器机制和垃圾回收机制的混合机制
单表查询
"""
增:
insert [into]
[数据库名.]表名[(字段1[, ..., 字段n])]
values
(数据1[, ..., 数据n])[, ..., (数据1[, ..., 数据n])];
删:
delete from [数据库名.]表名 [条件];
改:
update [数据库名.]表名 set 字段1=值1[, ..., 字段n=值n] [条件];
查:
select [distinct] 字段1 [[as] 别名1],...,字段n [[as] 别名n] from [数据库名.]表名 [条件];
"""
# 条件:from、where、group by、having、distinct、order by、limit => 层层筛选后的结果
# 注:一条查询语句,可以拥有多种筛选条件,条件的顺序必须按照上方顺序进行逐步筛选,distinct稍有特殊(书写位置),条件的种类可以不全
# 可以缺失,但不能乱序
去重:distinct
mysql>:
create table t1(
id int,
x int,
y int
);
mysql>: insert into t1 values(1, 1, 1), (2, 1, 2), (3, 2, 2), (4, 2, 2);
mysql>: select distinct * from t1; # 全部数据
mysql>: select distinct x, y from t1; # 结果 1,1 1,2 2,2
mysql>: select distinct y from t1; # 结果 1 2
# 总结:distinct对参与查询的所有字段,整体去重(所查的全部字段的值都相同,才认为是重复数据)
数据准备
CREATE TABLE `emp` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL,
`gender` enum('男','女','未知') NULL DEFAULT '未知',
`age` int(0) NULL DEFAULT 0,
`salary` float NULL DEFAULT 0,
`area` varchar(20) NULL DEFAULT '中国',
`port` varchar(20) DEFAULT '未知',
`dep` varchar(20),
PRIMARY KEY (`id`)
);
INSERT INTO `emp` VALUES
(1, 'yangsir', '男', 42, 10.5, '上海', '浦东', '教职部'),
(2, 'engo', '男', 38, 9.4, '山东', '济南', '教学部'),
(3, 'jerry', '女', 30, 3.0, '江苏', '张家港', '教学部'),
(4, 'tank', '女', 28, 2.4, '广州', '广东', '教学部'),
(5, 'jiboy', '男', 28, 2.4, '江苏', '苏州', '教学部'),
(6, 'zero', '男', 18, 8.8, '中国', '黄浦', '咨询部'),
(7, 'owen', '男', 18, 8.8, '安徽', '宣城', '教学部'),
(8, 'jason', '男', 28, 9.8, '安徽', '巢湖', '教学部'),
(9, 'ying', '女', 36, 1.2, '安徽', '芜湖', '咨询部'),
(10, 'kevin', '男', 36, 5.8, '山东', '济南', '教学部'),
(11, 'monkey', '女', 28, 1.2, '山东', '青岛', '教职部'),
(12, 'san', '男', 30, 9.0, '上海', '浦东', '咨询部'),
(13, 'san1', '男', 30, 6.0, '上海', '浦东', '咨询部'),
(14, 'san2', '男', 30, 6.0, '上海', '浦西', '教学部'),
(15, 'ruakei', '女', 67, 2.501, '上海', '陆家嘴', '教学部');
常用函数
"""
拼接:concat() | concat_ws()
大小写:upper() | lower()
浮点型操作:ceil() | floor() | round()
整型:可以直接运算
"""
mysql>: select name,area,port from emp;
mysql>: select name as 姓名, concat(area,'-',port) 地址 from emp; # 上海-浦东
mysql>: select name as 姓名, concat_ws('-',area,port,dep) 信息 from emp; # 上海-浦东-教职部
mysql>: select upper(name) 姓名大写,lower(name) 姓名小写 from emp;
mysql>: select id,salary,ceil(salary)上薪资,floor(salary)下薪资,round(salary)入薪资 from emp;
mysql>: select name 姓名, age 旧年龄, age+1 新年龄 from emp;
条件:where
# 多条件协调操作导入:where 奇数 [group by 部门 having 平均薪资] order by [平均]薪资 limit 1
mysql>: select * from emp where id<5 limit 1; # 正常
mysql>: select * from emp limit 1 where id<5; # 异常,条件乱序
# 判断规则
"""
比较符合:> | < | >= | <= | = | !=
区间符合:between 开始 and 结束 | in(自定义容器)
逻辑符合:and | or | not
相似符合:like _|%
正则符合:regexp 正则语法
"""
mysql>: select * from emp where salary>5;
mysql>: select * from emp where id%2=0;
mysql>: select * from emp where salary between 6 and 9;
mysql>: select * from emp where id in(1, 3, 7, 20);
# _o 某o | __o 某某o | _o% 某o* (*是0~n个任意字符) | %o% *o*
mysql>: select * from emp where name like '%o%';
mysql>: select * from emp where name like '_o%';
mysql>: select * from emp where name like '___o%';
# sql只支持部分正则语法
mysql>: select * from emp where name regexp '.*d'; # 不支持d代表数字,认为d就是普通字符串
mysql>: select * from emp where name regexp '.*[0-9]'; # 支持[]语法
分组与筛选:group by | having
where与having
# 表象:在没有分组的情况下,where与having结果相同
# 重点:having可以对 聚合结果 进行筛选
mysql>: select * from emp where salary > 5;
mysql>: select * from emp having salary > 5;
mysql>: select * from emp where id in (5, 10, 15, 20);
mysql>: select * from emp having id in (5, 10, 15, 20);
聚合函数
"""
max():最大值
min():最小值
avg():平均值
sum():和
count():记数
group_concat():组内字段拼接,用来查看组内其他字段
"""
分组查询 group by
# 修改my.ini配置重启mysql服务
sql_mode=ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
# 在sql_mode没有 ONLY_FULL_GROUP_BY 限制下,可以执行,但结果没有意义
# 有 ONLY_FULL_GROUP_BY 限制,报错
mysql>: select * from emp group by dep;
# 分组后,表中数据考虑范围就不是 单条记录,因为每个分组都包含了多条记录,参照分组字段,对每个分组中的 多条记录 统一处理
# eg: 按部门分组,每个部门都有哪些人、最高的薪资、最低的薪资、平均薪资、组里一共有多少人
# 将多条数据统一处理,这种方式就叫 聚合
# 每个部门都有哪些人、最高的薪资、最低的薪资、平均薪资 都称之为 聚合结果 - 聚合函数操作的结果
# 注:参与分组的字段,也归于 聚合结果
mysql>:
select
dep 部门,
group_concat(name) 成员,
max(salary) 最高薪资,
min(salary) 最低薪资,
avg(salary) 平均薪资,
sum(salary) 总薪资,
count(gender) 人数
from emp group by dep;
mysql>: select
dep 部门,
max(age) 最高年龄
from emp group by dep;
# 总结:分组后,查询条件只能为 分组字段 和 聚合函数操作的聚合结果
分组后的having
mysql>:
select
dep 部门,
group_concat(name) 成员,
max(salary) 最高薪资,
min(salary) 最低薪资,
avg(salary) 平均薪资,
sum(salary) 总薪资,
count(gender) 人数
from emp group by dep;
# 最低薪资小于2
mysql>:
select
dep 部门,
group_concat(name) 成员,
max(salary) 最高薪资,
min(salary) 最低薪资,
avg(salary) 平均薪资,
sum(salary) 总薪资,
count(gender) 人数
from emp group by dep having min(salary)<2;
# having可以对 聚合结果 再进行筛选,where不可以
排序
排序规则
# order by 主排序字段 [asc|desc], 次排序字段1 [asc|desc], ...次排序字段n [asc|desc]
未分组状态下
mysql>: select * from emp;
# 按年龄升序
mysql>: select * from emp order by age asc;
# 按薪资降序
mysql>: select * from emp order by salary desc;
# 按薪资降序,如果相同,再按年龄降序
mysql>: select * from emp order by salary desc, age desc;
# 按龄降序,如果相同,再按薪资降序
mysql>: select * from emp order by age desc, salary desc;
分组状态下
mysql>:
select
dep 部门,
group_concat(name) 成员,
max(salary) 最高薪资,
min(salary) 最低薪资,
avg(salary) 平均薪资,
sum(salary) 总薪资,
count(gender) 人数
from emp group by dep;
# 最高薪资降序
mysql:
select
dep 部门,
group_concat(name) 成员,
max(salary) 最高薪资,
min(salary) 最低薪资,
avg(salary) 平均薪资,
sum(salary) 总薪资,
count(gender) 人数
from emp group by dep
order by 最高薪资 desc;
限制 limit
# 语法:limit 条数 | limit 偏移量,条数
mysql>: select name, salary from emp where salary<8 order by salary desc limit 1;
mysql>: select * from emp limit 5,3; # 先偏移5条满足条件的记录,再查询3条
连表查询
连接
# 连接:将有联系的多张表通过关联(有联系就行,不一定是外键)字段,进行连接,形参一张大表
# 连表查询:在大表的基础上进行查询,就称之为连表查询
# 将表与表建立连接的方式有四种:内连接、左连接、右连接、全连接
一对多数据准备
mysql>: create database db3;
mysql>: use db3;
mysql>:
create table dep(
id int primary key auto_increment,
name varchar(16),
work varchar(16)
);
create table emp1(
id int primary key auto_increment,
name varchar(16),
salary float,
dep_id int
);
insert into dep values(1, '市场部', '销售'), (2, '教学部', '授课'), (3, '管理部', '开车');
insert into emp1(name, salary, dep_id) values('egon', 3.0, 2),('yanghuhu', 2.0, 2),('sanjiang', 10.0, 1),('owen', 88888.0, 2),('liujie', 8.0, 1),('yingjie', 1.2, 0);
笛卡尔积
# 笛卡尔积: 集合 X{a, b} * Y{o, p, q} => Z{{a, o}, {a, p}, {a, q}, {b, o}, {b, p}, {b, q}}
mysql>: select * from emp, dep;
# 总结:是两张表 记录的所有排列组合,数据没有利用价值
内连接
# 关键字:inner join on
# 语法:from A表 inner join B表 on A表.关联字段=B表.关联字段
mysql>:
select
emp.id,emp.name,salary,dep.name,work
from emp inner join dep on emp.dep_id = dep.id
order by emp.id;
# 总结:只保留两个表有关联的数据
左连接
# 关键字:left join on
# 语法:from 左表 left join 右表 on 左表.关联字段=右表.关联字段
mysql>:
select
emp.id,emp.name,salary,dep.name,work
from emp left join dep on emp.dep_id = dep.id
order by emp.id;
# 总结:保留左表的全部数据,右表有对应数据直接连表显示,没有对应关系空填充
右连接
# 关键字:right join on
# 语法:from A表 right join B表 on A表.关联字段=B表关联字段
mysql>:
select
emp.id,emp.name,salary,dep.name,work
from emp right join dep on emp.dep_id = dep.id
order by emp.id;
# 总结:保留右表的全部数据,左表有对应数据直接连表显示,没有对应关系空填充
左右可以相互转化
mysql>:
select
emp.id,emp.name,salary,dep.name,work
from emp right join dep on emp.dep_id = dep.id
order by emp.id;
mysql>:
select
emp.id,emp.name,salary,dep.name,work
from dep left join emp on emp.dep_id = dep.id
order by emp.id;
# 总结:更换一下左右表的位置,相对应更换左右连接关键字,结果相同
全连接
mysql>:
select
emp.id,emp.name,salary,dep.name,work
from emp left join dep on emp.dep_id = dep.id
union
select
emp.id,emp.name,salary,dep.name,work
from emp right join dep on emp.dep_id = dep.id
order by id;
# 总结:左表右表数据都被保留,彼此有对应关系正常显示,彼此没有对应关系均空填充对方
一对一与一对多情况一致
# 创建一对一 作者与作者详情 表
create table author(
id int,
name varchar(64),
detail_id int
);
create table author_detail(
id int,
phone varchar(11)
);
# 填充数据
insert into author values(1, 'Bob', 1), (2, 'Tom', 2), (3, 'ruakei', 0);
insert into author_detail values(1, '13344556677'), (2, '14466779988'), (3, '12344332255');
# 内连
select author.id,name,phone from author join author_detail on author.detail_id = author_detail.id order by author.id;
# 全连
select author.id,name,phone from author left join author_detail on author.detail_id = author_detail.id
union
select author.id,name,phone from author right join author_detail on author.detail_id = author_detail.id
order by id;
多对多:两表两表建立连接
# 在一对一基础上,建立 作者与书 的多对多关系关系
# 利用之前的作者表
create table author(
id int,
name varchar(64),
detail_id int
);
insert into author values(1, 'Bob', 1), (2, 'Tom', 2), (3, 'ruakei', 0);
# 创建新的书表
create table book(
id int,
name varchar(64),
price decimal(5,2)
);
insert into book values(1, 'python', 3.66), (2, 'Linux', 2.66), (3, 'Go', 4.66);
# 创建 作者与书 的关系表
create table author_book(
id int,
author_id int,
book_id int
);
# 数据:author-book:1-1,2 2-2,3 3-1,3
insert into author_book values(1,1,1),(2,1,2),(3,2,2),(4,2,3),(5,3,1),(6,3,3);
# 将有关联的表一一建立连接,查询所以自己所需字段
select book.name, book.price, author.name, author_detail.phone from book
join author_book on book.id = author_book.book_id
join author on author_book.author_id = author.id
left join author_detail on author.detail_id = author_detail.id;
nginx
1、什么是Nginx
Nginx是一个高性能的HTTP和反向代理服务器,及电子邮件代理服务器,同时也是一个非常高效的反向代理、负载平衡。
2、为什么要用Nginx
跨平台、配置简单,非阻塞、高并发连接:处理2-3万并发连接数,官方监测能支持5万并发,
内存消耗小:开启10个nginx才占150M内存 ,nginx处理静态文件好,耗费内存少,
内置的健康检查功能:如果有一个服务器宕机,会做一个健康检查,再发送的请求就不会发送到宕机的服务器了。重新将请求提交到其他的节点上。
节省宽带:支持GZIP压缩,可以添加浏览器本地缓存
稳定性高:宕机的概率非常小
接收用户请求是异步的:浏览器将请求发送到nginx服务器,它先将用户请求全部接收下来,再一次性发送给后端web服务器,极大减轻了web服务器的压力,一边接收web服务器的返回数据,一边发送给浏览器客户端, 网络依赖性比较低,只要ping通就可以负载均衡,可以有多台nginx服务器 使用dns做负载均衡,事件驱动:通信机制采用epoll模型(nio2 异步非阻塞)
3、为什么Nginx性能这么高
得益于它的事件处理机制:异步非阻塞事件处理机制:运用了epoll模型,提供了一个队列,排队解决
4、Nginx是如何处理一个请求的
首先,nginx在启动时,会解析配置文件,得到需要监听的端口与ip地址,然后在nginx的master进程里面先初始化好这个监控的socket,再进行listen,然后再fork出多个子进程出来, 子进程会竞争accept新的连接。此时,客户端就可以向nginx发起连接了。当客户端与nginx进行三次握手,与nginx建立好一个连接后,此时,某一个子进程会accept成功,然后创建nginx对连接的封装,即ngx_connection_t结构体,接着,根据事件调用相应的事件处理模块,如http模块与客户端进行数据的交换。最后,nginx或客户端来主动关掉连接,到此,一个连接就寿终正寝了
5、正向代理
一个位于客户端和原始服务器之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端才能使用正向代理
正向代理总结就一句话:代理端代理的是客户端
6、反向代理
反向代理是指以代理服务器来接受internet上的连接请求,然后将请求,发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器
反向代理总结就一句话:代理端代理的是服务端++++
7、动态资源、静态资源分离
动态资源、静态资源分离是让动态网站里的动态网页根据一定规则把不变的资源和经常变的资源区分开来,动静资源做好了拆分以后,我们就可以根据静态资源的特点将其做缓存操作,这就是网站静态化处理的核心思路,动态资源、静态资源分离简单的概括是:动态文件与静态文件的分离
8、为什么要做动、静分离
在我们的软件开发中,有些请求是需要后台处理的(如:.jsp,.do等等),有些请求是不需要经过后台处理的(如:css、html、jpg、js等等文件),这些不需要经过后台处理的文件称为静态文件,因此我们后台处理忽略静态文件。这会有人又说那我后台忽略静态文件不就完了吗,当然这是可以的,但是这样后台的请求次数就明显增多了。在我们对资源的响应速度有要求的时候,我们应该使用这种动静分离的策略去解决,动、静分离将网站静态资源(HTML,JavaScript,CSS,img等文件)与后台应用分开部署,提高用户访问静态代码的速度,降低对后台应用访问,这里我们将静态资源放到nginx中,动态资源转发到tomcat服务器中
9、负载均衡
负载均衡即是代理服务器将接收的请求均衡的分发到各服务器中,负载均衡主要解决网络拥塞问题,提高服务器响应速度,服务就近提供,达到更好的访问质量,减少后台服务器大并发压力
爬虫
看不见的反爬措施
一是加header头部信息:
什么是header头?
以火狐浏览器为例,右键—查看元素—进入网络界面,然后输入https://www.baidu.com进入百度主页:
红框内的部分就是该次请求的header头,服务器可以根据header头判断该次请求是由哪种浏览器(User-Agent)发起、访问的目标链接是从哪个网页跳转过来的(Referer)以及服务器地址(Host)。
1.加User-Agent值:
如果不加header头,部分网站服务器判断不到用户的访问来源,所以会返回一个404错误来告知你是一个爬虫,拒绝访问,解决办法如下:
这样服务器就会把用户当做浏览器了。建议每次爬虫都把User-Agnet头加上,起码是对人家网站的尊重
2.加Referer值
这类反爬网站也很常见,例如美团,仅仅加User-Agnet还是返回错误信息,这时就要把Referer值也加到头部信息中:
这样就会返回正常网页了。
3.加Host值
根据同源地址判断用户是否为爬虫,解决办法为:
4.加Accept值
之前遇到过这种网站,我加了一圈header头部信息才成功,最后发现是需要加Accept值,这类反爬措施的解决办法为:
关于header头的反爬,建议在加上User-Agent失败之后,就把所有头部信息加上,最后用排除法选出到底是哪个值。
二是限制IP的请求数量:
这种就更常见了,大部分网站都有此类反爬措施,也就是说网站服务器会根据某个ip在特定时间内的访问频率来判断是否为爬虫,然后把你把你拉进“黑名单”,素质好的给你返回403或者出来个验证码,素质不好的会给你返回两句脏话。此种情况有两种解决办法:
①降低爬虫请求速率,但是会降低效率;
②添加代理ip,代理ip又分为付费的和不要钱的,前者比较稳定,后者经常断线。
添加格式为:
三是Ajax动态请求加载:
这类一般是动态网页,无法直接找到数据接口,以某易新闻网站为例:
我想爬取该网页内的新闻图片,发现它的网页url一直不变,但是下拉网页的时候会一直加载图片,那么我们该怎么办呢?
首先按照开头方式打开流量分析工具
点击左上角“垃圾桶”图标清空缓存,然后下拉新闻网页:
会出现一大堆东西,但是不用慌,我们可以根据类型去寻找,一般图片信息肯定实在html、js或json格式的文件中,一个一个点进去看看,很快就找到了结果:
结果中把callback去掉之后就是个json文件,它的url为:
红线处为变量,02代表第2页,这样就找到图片接口啦。
看的见的反扒措施
一是登录才有数据,比如某查查:
这种一般有三种解决办法,一是requests模拟登录,但是会有参数加密的问题和验证码的问题,有点难;二是selenium模拟登录,要解决验证码的问题;三是手动登录后获取cookie,在requests中加入cookie,这种方法比较简单,但是受cookie有效期的限制,要经常更换cookie。
关于验证码的问题,我很头大,因为验证码实在是种类太多了,而且还很变态,例如下图:
我用眼都很难瞅出来,程序就更难说了,索性直接用打码网站,价格不贵,准确率又低。
二是限制网页返回数据条数:
例如微博评论,最多只能返回50页的评论数据,这种反扒措施暂时没有好的解决办法,除非能找到特殊接口。
三是多次验证:
例如12306网站,用requests实现自动抢票时,浏览器会和服务器进行多次交互验证,有的验证虽然不返回任何数据,但是还必须要有,否则下一个url的请求就会出错。
四是网站数据加密:
也就是说网站服务器返回的数据经过某种加密算法进行加密,这个时候你就要学习前端知识了,因为加密方式一般都隐藏在JavaScript代码中,如果你学会这一技能,基本可以应聘爬虫工程师的岗位了。
五是APP数据:
没有网页数据,例如二手交易平台某鱼
爬这类数据一般有两种方法:一是边爬边处理,即用appium模拟点击滑动手机界面,然后用mitmdump在后端监测并保存数据,这种方法比较简单;二是做逆向分析,这个过程是很难的,目前这部分知识小编也正在学习中,希望有机会能和大家一起交流。
以上都是我在爬虫实践中遇到的一些反爬措施,希望能对大家的爬虫学习之路起到抛砖引玉的作用。
Docker
docker images 查看镜像
docker search 镜像名称 搜索镜像
docker pull 镜像名称 拉取镜像
docker rmi 镜像ID 删除镜像
docker rmi `docker images -q` 删除所有镜像
docker ps 查看正在运行的容器
docker ps –a 查看所有的容器
容器操作:镜像运行,容器启动,就是一个个操作系统
创建容器:
第一种
docker run -it --name=mycentos centos:centos7 /bin/bash
exit 退出容器,容器也就停止了
第二种
docker run -di --name=mycentos2 centos:centos7 不进入容器 内部
docker exec -it mycentos2 /bin/bash 进入到容器内容
exit退出,容器不停止
docker stop id号或者名字 容器停止
docker start id号或者名字 启动容器
web相关技术栈
前端
bootstrap
Bootstrap是一个非常好的入门选择,教程示例非常丰富,颜值也还过得去。
栅格布局自带响应式,常用的颜色都有类可以直接调用。
Font Awesome
图标字体库和CSS框架,毕竟只有图标字体和CSS,所以一般配合其他的样式框架使用。
jQuery
jQuery 是一个 JavaScript 库。
jQuery 极大地简化了 JavaScript 编程。
jQuery 很容易学习。
直接操作DOM
vue
elementui
web框架
django
http协议
全称:超文本传输协议
1.四大特性
1.基于TCP/IP之上作用于应用层
2.基于请求响应
3.无状态 每次连接一次只处理一个请求,
不保存用户状态 不利于保持连接 所以才有cookie session的产生...
4.无连接:
长连接 websocket(HTTP协议的大补丁):没有数据传也要保持tcp连接
Websocket 的最大特点是,服务器可以主动向客户端推送消息,客户端也可以主动向服务器发送消息,
2.数据格式
请求格式
请求首行(请求方式,协议版本。。。)
请求头(一大堆k:v键值对)
请求体(真正的数据 发post请求的时候才有 如果是get请求不会有)
响应格式
响应首行
响应头
响应体
restful api
2.1 数据的安全保障
url链接一般都采用https协议进行传输
注:采用https协议,可以提高数据交互过程中的安全性
回到顶部
2.2 接口特征表现
用api关键字标识接口url:
https://api.baidu.com
https://www.baidu.com/api
注:看到api字眼,就代表该请求url链接是完成前后台数据交互的
回到顶部
2.3 多数据版本共存
在url链接中标识数据版本
https://api.baidu.com/v1
https://api.baidu.com/v2
注:url链接中的v1、v2就是不同数据版本的体现(只有在一种数据资源有多版本情况下)
回到顶部
2.4 数据即是资源
接口一般都是完成前后台数据的交互,交互的数据我们称之为资源
https://api.baidu.com/users
https://api.baidu.com/books
https://api.baidu.com/book
注:一般提倡用资源的复数形式,在url链接中奖励不要出现操作资源的动词,错误示范:https://api.baidu.com/delete-user
特殊的接口可以出现动词,因为这些接口一般没有一个明确的资源,或是动词就是接口的核心含义
https://api.baidu.com/place/search
https://api.baidu.com/login
回到顶部
2.5 资源操作由请求方式决定
操作资源一般都会涉及到增删改查,我们提供请求方式来标识增删改查动作
https://api.baidu.com/books - get请求:获取所有书
https://api.baidu.com/books/1 - get请求:获取主键为1的书
https://api.baidu.com/books - post请求:新增一本书书
https://api.baidu.com/books/1 - put请求:整体修改主键为1的书
https://api.baidu.com/books/1 - patch请求:局部修改主键为1的书
https://api.baidu.com/books/1 - delete请求:删除主键为1的书
3.响应状态码
回到顶部
3.1 正常响应
响应状态码2xx
200:常规请求
201:创建成功
回到顶部
3.2 重定向响应
响应状态码3xx
301:永久重定向
302:暂时重定向
回到顶部
3.3 客户端异常
响应状态码4xx
403:请求无权限
404:请求路径不存在
405:请求方法不存在
回到顶部
3.4 服务器异常
响应状态码5xx
500:服务器异常
4.响应结果
回到顶部
4.1 响应数据要有状态码、状态信息以及数据本身
{
"status": 0,
"msg": "ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"location":{
"lat":31.415354,
"lng":121.357339
},
"address":"月罗路2380号",
"province":"上海市",
"city":"上海市",
"area":"宝山区",
"street_id":"339ed41ae1d6dc320a5cb37c",
"telephone":"(021)56761006",
"detail":1,
"uid":"339ed41ae1d6dc320a5cb37c"
}
...
]
}
回到顶部
4.2 需要url请求的资源需要访问资源的请求链接
{
"status": 0,
"msg": "ok",
"results":[
{
"name":"肯德基(罗餐厅)",
"img": "https://image.baidu.com/kfc/001.png"
}
...
]
}