先介绍YOLO[转]:
第一个颠覆ross的RCNN系列,提出region-free,把检测任务直接转换为回归来做,第一次做到精度可以,且实时性很好。
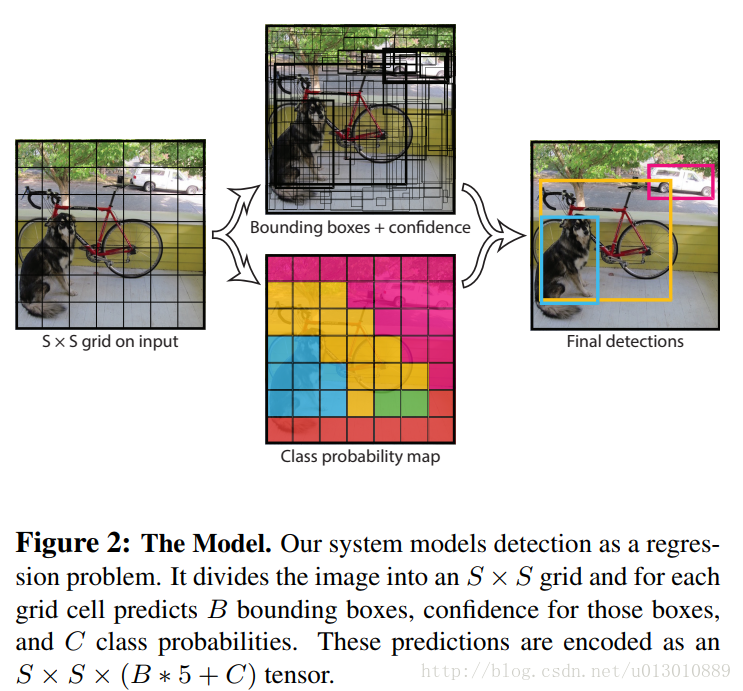
1. 直接将原图划分为SxS个grid cell,如果有物体的中心落到这个格子里那么这个格子的gt就是这个物体。
2. 每个格子被指定的gt需要对应B个bounding box(下面简称为bbox)去回归,也就是说每个格子对应的B个bbox的gt是一样的。
3. 每个bbox预测5个值: x, y, w, h, 置信度。(x, y)是bbox的中心在对应格子里的相对位置,范围[0,1]。(w, h)是bbox相对于全图的的长宽,范围[0,1]。x, y, w, h的4个gt值可以算出来。confidence = P(object)* iou, 它的gt值是这样指定的: 若bbox对应格子包含物体,则P(object) = 1,否则P(object) = 0。它和ssd及rcnn系列在这里有个很不同的地方,它是直接回归bbox的位置,而ssd及rcnn系列是回归的是default box/anchor的偏移量,它没有default box/anchor这个东西。
4. 每个格子也会预测属于各个类别的置信度,也就是每个格子对应的B个box是共享这个值的,这B个box只能属于一类的,所以和第一步呼应它们的gt都是一样的。
5. inference阶段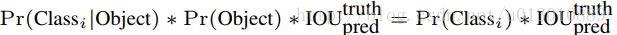


YOLO使用均方和误差作为loss函数来优化模型参数,即网络输出的S*S*(B*5 + C)维向量与真实图像的对应S*S*(B*5 + C)维向量的均方和误差。如下式所示。其中,coordError、iouError和classError分别代表预测数据与标定数据之间的坐标误差、IOU误差和分类误差。
每个格子的 loss=coordError + iouError + classError
YOLO对上式loss的计算进行了如下修正。
- 位置相关误差(坐标、IOU)与分类误差对网络loss的贡献值是不同的,因此YOLO在计算loss时,使用λcoord =5修正coordError。
- 在计算IOU误差时,包含物体的格子与不包含物体的格子,二者的IOU误差对网络loss的贡献值是不同的。若采用相同的权值,那么不包含物体的格子的confidence值近似为0,变相放大了包含物体的格子的confidence误差在计算网络参数梯度时的影响。为解决这个问题,YOLO 使用λnoobj =0.5修正iouError。(注此处的‘包含’是指存在一个物体,它的中心坐标落入到格子内)。
- 对于相等的误差值,大物体误差对检测的影响应小于小物体误差对检测的影响。这是因为,相同的位置偏差占大物体的比例远小于同等偏差占小物体的比例。YOLO将物体大小的信息项(w和h)进行求平方根来改进这个问题。(注:这个方法并不能完全解决这个问题)。
YOLO的loss

进一步理解YOLO
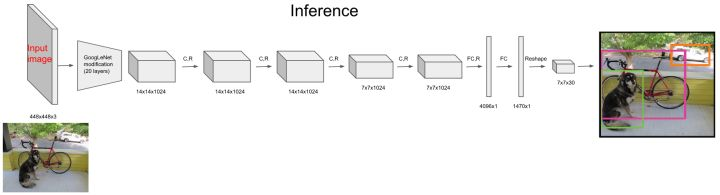
- 在YOLO网络中,首先通过一组CNN提取feature maps
- 然后通过最后一个全连接FC层生成SxSx(5*B+C)=7x7x(5*2+20)=1470长的向量
- 再把1470向量reshape成SxSx(5*B+C)=7x7x30形状的多维矩阵
- 通过解析多维矩阵获得Detection bounding box + Confidence
- 最后对Detection bounding box + Confidence进行Non maximum suppression获得输出
在设置好网络,并进行初始化后,通过forward就可以获得我们需要的SxSx(5*B+C)矩阵,只不过其中数值并不是我们想要的。当经过上述YOLO Loss下的负反馈训练后,显然就可以获得我们SxSx(5*B+C)矩阵,再经过解析+NMS就可以获得输出框了。
从本质上说,Faster RCNN通过对Anchors的判别和修正获得检测框;而YOLO通过强行回归获得检测框。
3.3 passthrough操作
修改后的网络最终在13 * 13的特征图上进行预测,虽然这足以胜任大尺度物体的检测,如果用上细粒度特征可能对小尺度的物体检测有帮助。Faser R-CNN和SSD都在不同层次的特征图上产生proposal以获得多尺度的适应性。
YOLOv2使用了一种不同的方法,简单添加一个 passthrough layer,把浅层特征图(分辨率为26 * 26)连接到深层特征图。passthrough layer把高低分辨率的特征图concat,叠加相邻特征到不同通道
这个方法把26 * 26 * 512的特征图叠加成13 * 13 * 2048的特征图,与原生的深层特征图相连接(即:加深channel的conv1与conv3 concat后作为conv4的输入)。
YOLOv2的检测器使用的就是经过扩展后的的特征图,它可以使用细粒度(浅层)特征,使得模型的性能获得了1%的提升。
regorg layer分析:这里ReorgLayer层就是将26∗26∗512的张量中26∗26切割成4个13∗13,然后连接起来,使得原来的512通道变成了2048。
1 #darknet.py 2 self.reorg = ReorgLayer(stride=2) # stride*stride times the channels of conv1s
1 #reorg_layer.py 2 def forward(self, x): 3 stride = self.stride 4 5 bsize, c, h, w = x.size() 6 out_w, out_h, out_c = int(w / stride), int(h / stride), c * (stride * stride) 7 out = torch.FloatTensor(bsize, out_c, out_h, out_w) 8 9 if x.is_cuda: 10 out = out.cuda() 11 reorg_layer.reorg_cuda(x, out_w, out_h, out_c, bsize, stride, 0, out) 12 else: 13 reorg_layer.reorg_cpu(x, out_w, out_h, out_c, bsize, stride, 0, out) 14 15 return out
1 //reorg_cpu.c 2 int reorg_cpu(THFloatTensor *x_tensor, int w, int h, int c, int batch, int stride, int forward, THFloatTensor *out_tensor) 3 { 4 // Grab the tensor 5 float * x = THFloatTensor_data(x_tensor); 6 float * out = THFloatTensor_data(out_tensor); 7 8 // https://github.com/pjreddie/darknet/blob/master/src/blas.c 9 int b,i,j,k; 10 int out_c = c/(stride*stride); 11 12 for(b = 0; b < batch; ++b){ 13 //batch_size 14 for(k = 0; k < c; ++k){ 15 //channel 16 for(j = 0; j < h; ++j){ 17 //height 18 for(i = 0; i < w; ++i){ 19 //width 20 int in_index = i + w*(j + h*(k + c*b)); 21 int c2 = k % out_c; 22 int offset = k / out_c; 23 int w2 = i*stride + offset % stride; 24 int h2 = j*stride + offset / stride; 25 int out_index = w2 + w*stride*(h2 + h*stride*(c2 + out_c*b)); 26 if(forward) out[out_index] = x[in_index]; // 压缩channel 27 else out[in_index] = x[out_index]; // 扩展channel 28 } 29 } 30 } 31 } 32 33 return 1; 34 }
图片有错误,待改,输入的1,3点分布在输出的第1个feature map上,输入的2,4点分布在输出的第2个feature map上,idx2后面+w2
下图从右到左为forward计算方向,从左到右为backward求导方向

3.4 目标函数计算
1 #darknet.py 2 def loss(self): 3 #可以看出,损失值也是基于预测框bbox,预测的iou,分类三个不同的误差和 4 return self.bbox_loss + self.iou_loss + self.cls_loss 5 6 def forward(self, im_data, gt_boxes=None, gt_classes=None, dontcare=None): 7 conv1s = self.conv1s(im_data) 8 conv2 = self.conv2(conv1s) 9 conv3 = self.conv3(conv2) 10 conv1s_reorg = self.reorg(conv1s) 11 cat_1_3 = torch.cat([conv1s_reorg, conv3], 1) 12 conv4 = self.conv4(cat_1_3) 13 conv5 = self.conv5(conv4) # batch_size, out_channels, h, w 14 …… 15 …… 16 # tx, ty, tw, th, to -> sig(tx), sig(ty), exp(tw), exp(th), sig(to) 17 '''预测tx ty''' 18 xy_pred = F.sigmoid(conv5_reshaped[:, :, :, 0:2]) 19 '''预测tw th ''' 20 wh_pred = torch.exp(conv5_reshaped[:, :, :, 2:4]) 21 bbox_pred = torch.cat([xy_pred, wh_pred], 3) 22 '''预测置信度to ''' 23 iou_pred = F.sigmoid(conv5_reshaped[:, :, :, 4:5]) 24 '''预测分类class ''' 25 score_pred = conv5_reshaped[:, :, :, 5:].contiguous() 26 prob_pred = F.softmax(score_pred.view(-1, score_pred.size()[-1])).view_as(score_pred) 27 28 # for training 29 if self.training: 30 bbox_pred_np = bbox_pred.data.cpu().numpy() 31 iou_pred_np = iou_pred.data.cpu().numpy() 32 _boxes, _ious, _classes, _box_mask, _iou_mask, _class_mask = self._build_target( 33 bbox_pred_np, gt_boxes, gt_classes, dontcare, iou_pred_np) 34 _boxes = net_utils.np_to_variable(_boxes) 35 _ious = net_utils.np_to_variable(_ious) 36 _classes = net_utils.np_to_variable(_classes) 37 box_mask = net_utils.np_to_variable(_box_mask, dtype=torch.FloatTensor) 38 iou_mask = net_utils.np_to_variable(_iou_mask, dtype=torch.FloatTensor) 39 class_mask = net_utils.np_to_variable(_class_mask, dtype=torch.FloatTensor) 40 41 num_boxes = sum((len(boxes) for boxes in gt_boxes)) 42 43 # _boxes[:, :, :, 2:4] = torch.log(_boxes[:, :, :, 2:4]) 44 box_mask = box_mask.expand_as(_boxes) 45 #计算预测的平均bbox损失值 46 self.bbox_loss = nn.MSELoss(size_average=False)(bbox_pred * box_mask, _boxes * box_mask) / num_boxes 47 #计算预测的平均iou损失值 48 self.iou_loss = nn.MSELoss(size_average=False)(iou_pred * iou_mask, _ious * iou_mask) / num_boxes 49 #计算预测的平均分类损失值 50 class_mask = class_mask.expand_as(prob_pred) 51 self.cls_loss = nn.MSELoss(size_average=False)(prob_pred * class_mask, _classes * class_mask) / num_boxes 52 53 return bbox_pred, iou_pred, prob_pred
参考自:仙守
YOLO部分: