初识python爬虫
什么是爬虫?
- 爬取网络数据的虫子(Python程序)
爬虫实质是什么呢?
- 模拟浏览器的工作原理,向服务器请求相应的数据
浏览器的工作原理
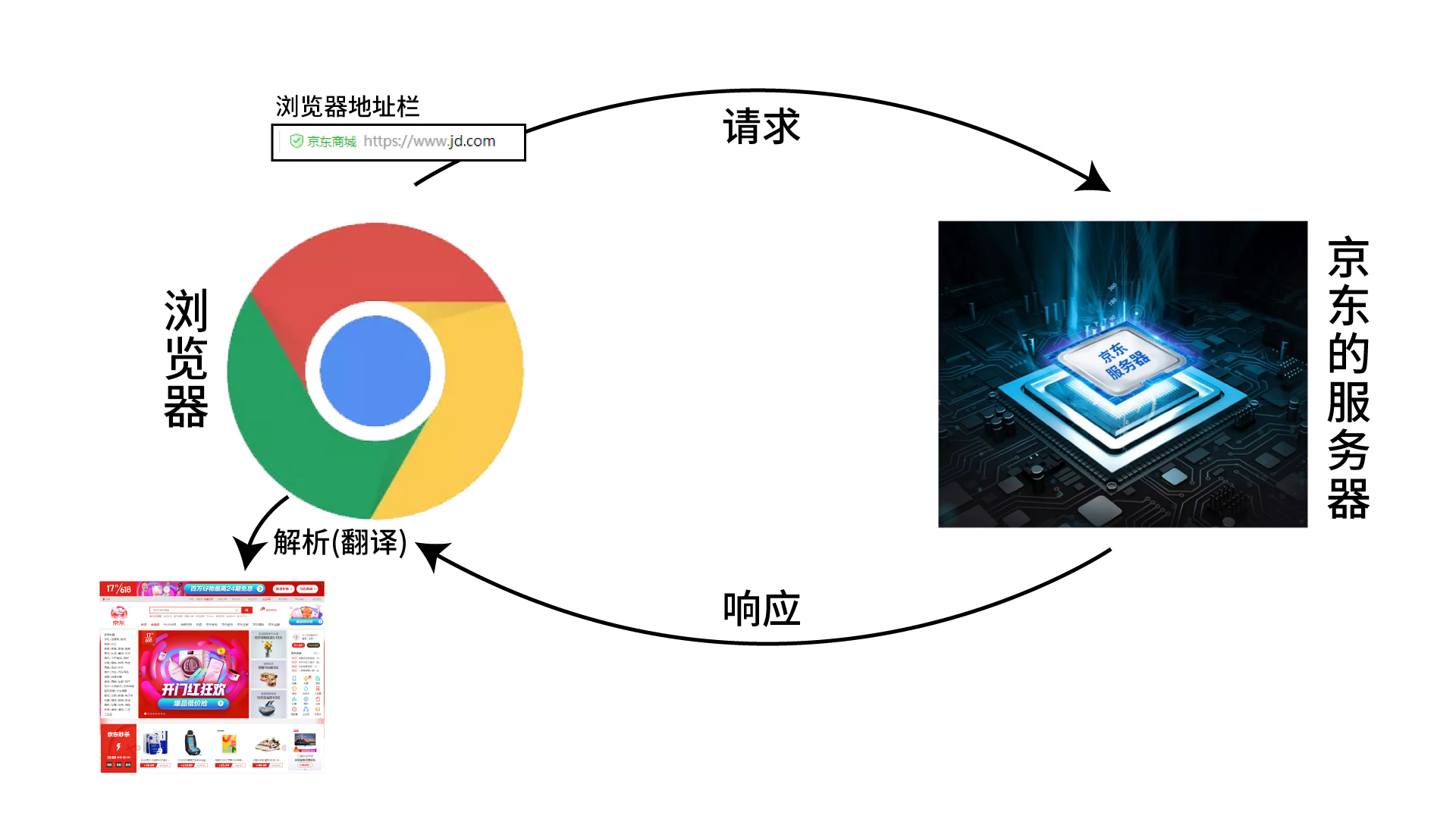
- 浏览器在这个过程中还起到了翻译数据的作用哦
爬虫的工作原理如下图:

梳理代码流程:
(1)引入Python工具包requests
(2)使用工具包中的get方法,向服务器发起请求
(3)打印输出请求回来的数据并解析(print语法)
import requests;
import json;
ajaxGet = requests.get('http://news.baidu.com/widget?id=LocalNews&ajax=json&channel=guonei&picn1=2&t=1622020128186');
list = json.loads(ajaxGet.text);
print(list['data']['LocalNews']['localNews']['rows']['pic']);
for itme in list['data']['LocalNews']['localNews']['rows']['pic']:
print(itme['url']);
(4)学会引入openpyxl工具包存储数据
(a)创建一个Excel表格
(b)创建一个sheet
(c)在sheet里面保存数据
(d)把表格保存在一个磁盘里
import openpyxl; import requests; import json; wk = openpyxl.Workbook(); sheet = wk.create_sheet(); url = 'http://news.baidu.com/widget?id=LocalNews&ajax=json&channel=guonei&picn1=2&t=1622020128186' resp = requests.get(url); json_data = json.loads(resp.text); data = json_data['data']['LocalNews']['localNews']['rows']['pic']; for item in data: imgUrl = item['imgUrl']; title = item['title']; sheet.append([ imgUrl, title ]); wk.save('data/李大山-2223222132131.xlsx')