一、列表
Python内置的一种数据类型是列表:list,它是一种有序的集合,可添加和删除其中的元素。
列表的创建:将用逗号分隔的不同数据项用方括号括起来即可
获取list元素的个数:len()
1 name = ['小白','小黑','小花','小灰'] #创建列表 2 print(name) 3 print(len(name))

1、列表方法及其基本操作
1.1 增
append():追加元素到列表末尾
insert():插入元素到列表指定位置
1 name = ['小白','小黑','小花','小灰'] #创建列表 2 3 #增 4 name.append('小黄') 5 print(name) 6 name.insert(0,'小绿') 7 print(name)

1.2 删
pop():删除列表末尾的元素,pop(i)删除指定位置的元素,i为索引位置
remove():移除列表中某个值的第一个匹配项
del 列表名[i]:删除指定位置的元素,i为索引位置
clear():清空列表中的元素
1 name = ['小白','小黑','小花','小黑','小灰'] #创建列表 2 3 #删 4 name.pop() #删除末尾元素 5 print(name) 6 name.pop(0) #删除第一个元素 7 print(name) 8 name.remove('小黑') #删除列表中值为小黑的第一个元素 9 print(name)

1 name = ['小白','小黑','小花','小灰'] #创建列表 2 3 #删 4 del name[-1] #删除指定位置的元素 5 print(name) 6 name.clear() #清空列表中的元素 7 print(name)
1.3 修改
使用索引标记为某个特定的的元素赋值
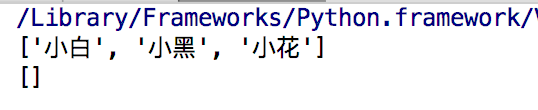
1 name = ['小白','小黑','小花','小灰'] #创建列表 2 3 #修改 4 name[3] = '小黄' 5 print(name) 6 name[4] = '小绿' #修改的时候如果指定的下标不存在,会报错

1.4 查
index():从列表中找出某个值第一个匹配项的索引位置
count():统计某个元素在列表里出现的次数
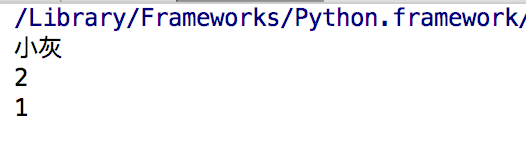
1 name = ['小白','小黑','小花','小灰'] #创建列表 2 3 #查 4 print(name[-1]) #取值 下标为-1的时候,就取最后一个元素 5 print(name.index('小花')) #获取元素的下标,如果找不到那个元素的话,会报错 6 print(name.count('小花')) #查看元素在list里面出现了多少次
1.5 反转
reverse():反转列表,会改变原列表的值
1 name = ['小白','小黑','小花','小灰'] #创建列表 2 3 #反转 4 name.reverse() #就是把这个list反转一下 5 print(name)

1.6 排序
sort():对列表进行排序;升序:列表名.sort();降序:列表名.sort(reverse=True)
1 nums = [9,2,34,12,34,457,2342] 2 # nums = ['b','f','e','z','g','h'] 3 nums.sort() #升序 4 print(nums) 5 nums.sort(reverse=True) #排序,降序 6 print(nums)

1.7 合并列表
cities = ['北京','上海'] cities2 = ['成都','深圳','广州'] #方法一: print(cities+cities2) #不会改变cities,和cities2的值 # 方法二: # cities.extend(cities2) #把cities2的元素加到cities中,改变了cities的值 # print(cities)
![]()

![]()
1.8 切片
切片可以获取多个元素,可理解为:从第几个元素开始,到第几个元素结束,获取他们之间的值;
切片格式:列表名:[1:10],如要获取name的第一个到第五个元素, 用name[0:6],切片不包含后面那个元素的值的,顾头不顾尾;
前面的下标为0时可省略写为:name[:6];
切片后面还可以写一个参数,叫做步长。即隔多少个元素取一次,默认不写时就是隔一个取一次。
切片操作也可以对字符串使用,和列表的用法一样,实例如下:
1 # 切片 2 # 切片是list取值的一种方式 3 nums = ['张三','李四','王某某','周大'] 4 # 0 1 2 3 5 6 print(nums[1:3]) #顾头不顾尾 7 print(nums[1:]) #如果从某个下标开始取,取到末尾结束,那么末尾的下标可以省略不写 8 print(nums[:2]) #如果是从头开始取,取到后面某个下标结束,那么开头的下标可以不写 9 print(nums[:]) #取所有的

1 lis = list(range(1,21)) 2 print(lis) 3 print(lis[::2]) #步长,隔几个取一次 4 print(lis[::-2]) #步长,隔几个取一次 5 # #如果步长是正数的话,从左往右边开始取值 6 # ##如果步长是负数的话,从右边往左边开始取值 7 8 print(lis[::-1]) #反转list 9 print(lis) 10 print(lis[1::-1]) 11 12 lis.reverse() #改变了原来list的值 13 new_list = lis[::-1] #产生了新的一个list,不会改变原来list的值 14 print(new_list) 15 print(lis)

1.9 多维数组
1 #多维数组 2 n = [1,2,3] #1维数组 3 n2= [ [1,2,3] ,['haha'] ] #二维数组 4 my = [[1,2,3,4,5,6],['name','age','sex','哈哈',['小明','小黑','小白']],890] #3维数组 5 print(my[1][4][0]) 6 my[1][4].append('小紫') 7 my[1][2]='性别' 8 print(my) 9 print( len(my) ) #看变量的元素个数,长度

二、元祖
元组和列表的区别:元组的值不能改变,一旦创建,就不能再改变了;只能读,无法增删改
元组的定义方式:用小括号();
元祖方法:元组只有两个方法,count和index;
1 #定义元组 2 cities = ("beijing","shanghai") #一旦定义好,就不能再变了 3 #cities[0] = "tianjing" #元组的值不可修改,这样写会报错
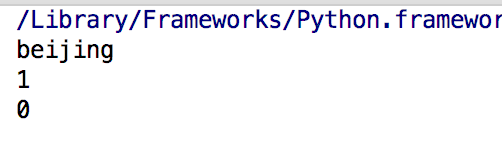
1 #元素操作及方法,只能查不能增删改 2 print(cities[0]) 3 print(cities.count("beijing")) 4 print(cities.index("beijing"))
三、字典
字典:dict,全称是dictionary,其他语言中也称为map,它具有极快的查找速度;
字典是一种key-value的数据类型。比如:要存每个人的信息,每个人的编号为key,value就是每个人的信息,这样一个字典就能存所有人的信息了。
字典的定义:使用{},大括号;每个值用“,”隔开,key和value使用“:”分隔。
1 #定义字典 2 info = { 3 'name':'哈哈', 4 'age':18, 5 'sex':'不知道', 6 'addr':'天通苑', 7 'qq':19823423, 8 'email':'shenyang@qq.com' 9 }
字典的特性:
1)字典是无序的;它没有下标,用key来当索引,所以是无序的
2)字典的key必须是唯一的:因为它是通过key来进行索引的,所以key不能重复
字典的增删改查方法:
增加:
1 #定义字典 2 info = { 3 'name':'张三', 4 'age':18, 5 'sex':'男', 6 'addr':'天通苑', 7 'qq':19823423, 8 'email':'zhangsan@qq.com' 9 } 10 11 #增加:两种方式 12 info['class'] = '1班' 13 info.setdefault('house','一环') 14 print(info)
![]()
修改:
1 info['age'] = 38 #修改 2 print(info) 3 info.setdefault('age',49) #setdefault这种方式,如果key已经存在,不管它,如果key不存在的话,就新增。 4 print(info)
![]()
删除:
1 #删除 2 info.pop('sex') #pop():#标准的删除方法,key不存在时会报错 3 del info['sex'] #del key不存在时会报错 4 print(info) 5 6 info.clear() #清空字典 7 info.popitem() #随机删除一个key
查询:
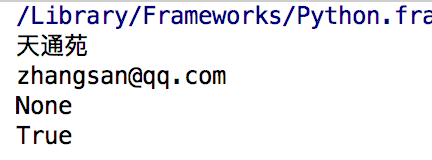
1 #取值、查询 2 print(info['addr']) 3 # print(info['add']) #传入不存key时报错 4 5 print(info.get('email')) 6 print(info.get('eeee')) #传入不存在key时,返回None 7 # print(info.get('eee','ceshi') )#key不存在时,返回后面指定的值 8 9 print('email' in info) #判断email是否在这个字典中,返回True或者False
查询所有的key,value:
1 print(info.values()) 2 print(info.keys())
![]()
把一个字典加入到另一字典中:
1 yaoyuan = {'age':19,'name':'李四'} 2 info.update(yaoyuan) #把一个字典加入到另外一个字典里面 3 print(info)
![]()
循环字典:
1 for infos in info: #循环时默认打印字典的key 2 print(infos) 3 4 #循环取k,v 5 for k,v in info.items(): 6 print(k,v)
四、字符串
字符串:它可以存任意类型的字符串,比如名字,一句话等等
字符串常用方法:
1 name = 'apple' 2 print(name.capitalize()) #把字符串首字母大写 3 print(name.center(50,'-')) #把字符串居中的 4 print(name.index('p'))#返回匹配到的第一个元素的位置,找不到下标的时候会报错 5 print(name.isalnum()) #只能有英文、数字 6 print(name.isalpha()) #判断是否只为英文的,汉字也可以
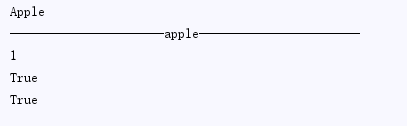
1 print(name.count('p')) #查询xx出现的次数 2 print(name.endswith('.jpg'))#判断字符串是否以xx结尾 3 print(name.startswith('ap'))#判断字符串是否以xx开头 4 print(name.upper()) #全转化为大写 5 print(name.lower()) #全转化为小写 6 print(name.find('p')) #它找不到元素的时候,不会报错,会返回-1

1 name = ' apple ' 2 print(name.isdigit()) #判断是否为纯数字 3 print(name.isspace()) #判断是否全都是空格 4 print(name.strip())#去掉字符串两边的东西,默认是去调两边的空格和换行符的 5 print(name.lstrip())#只去掉左边的 6 print(name.rstrip())#只去掉右边的 7 print(name.replace('le','haha')) #替换字符串,把前面的替换成后面的

1 num ='88' 2 print(num.zfill(4)) #在字符串前面补0,数字代表补0后字符串的总位数 3 4 names = 'dt,wx,xin,wang' 5 print(names.split(',')) #1、分割字符串,2、把字符串变成一个list 3、默认是以空格和换行符分割的 6 7 stus = ['hh','dd','ww','haha'] 8 print('.'.join(stus)) #1、是吧list变成字符串的 2、以某个字符串连接

1 import string 2 print(string.ascii_letters) #返回所有的大写+小写字母 3 print(string.ascii_lowercase) #返回所有的小写字母 4 print(string.ascii_uppercase) #返回所有的大写字母 5 print(string.digits) #返回所有的数字 6 print(string.punctuation) #所有的特殊字符

备注:字符串的值定义好之后也不能被修改
#字符串定义好了之后,也不能修改 s = 'abcEFGabc' # s[0]='h' #不能修改,这样修改会报错:TypeError: 'str' object does not support item assignment new_s = s.replace('abc','') #原来的值不会被修改,这种方法会重新返回一个新的值 print("s=",s) #s= abcEFGabc print("new_s=",new_s) #new_s= EFG