一、问题描述
给定用户签到数据集,预测用户下次签到位置
二、数据准备
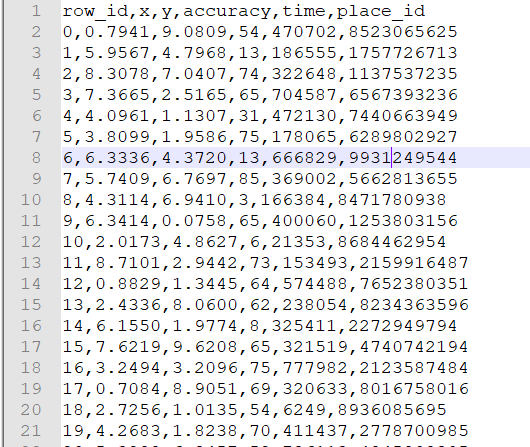
row_id:签到事件id
x,y:签到坐标
accuracy:准确度,定位精度
time:时间戳
place_id:签到的位置,预测目标值
三、实现代码
import pandas as pd from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier # 获取数据集 facebook = pd.read_csv("./pic/train.csv") # print(facebook.head()) # 基本数据处理 # 缩小数据范围 data = facebook.query("x>2.0&x<3.0&y>2.0&y<3.0") # 选择时间特征 time = pd.to_datetime(data["time"], unit="s") # print(time.head()) time = pd.DatetimeIndex(time) data["day"] = time.day data["hour"] = time.hour data["weekday"] = time.weekday # 去掉签到较少的地方 place_count = data.groupby("place_id").count() place_count = place_count[place_count["row_id"] > 3] data = data[data["place_id"].isin(place_count.index)] # 确定特征值和目标值 x = data[["x", "y", "accuracy", "day", "hour", "weekday"]] y = data["place_id"] # 分割数据集 x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22) # 特征工程--特征与处理(标准化) # 实例化一个转换器 transfer = StandardScaler() # 调用fit_transform x_train = transfer.fit_transform(x_train) x_test = transfer.fit_transform(x_test) # 机器学习 knn+cv # 实例化一个估计器 estimator = KNeighborsClassifier() # 网格校验 param_grid = {"n_neighbors": [1, 3, 5, 7]} estimator = GridSearchCV(estimator, param_grid=param_grid, cv=3) # 模型训练 estimator.fit(x_train, y_train) # 模型评估 score = estimator.score(x_test, y_test) print("最后预测的正确率为: ", score) y_predict = estimator.predict(x_test) print("最后的预测值是: ", y_predict) print("预测值和真实值的对比情况: ", y_predict == y_test) # 使用交叉验证后的评估方式 print("在交叉验证中最好的结果: ", estimator.best_score_) print("最好的模型参数: ", estimator.best_estimator_) print("每次交叉验证后的验证集准确率结果和训练集准确率结果: ", estimator.cv_results_)
四、运行结果
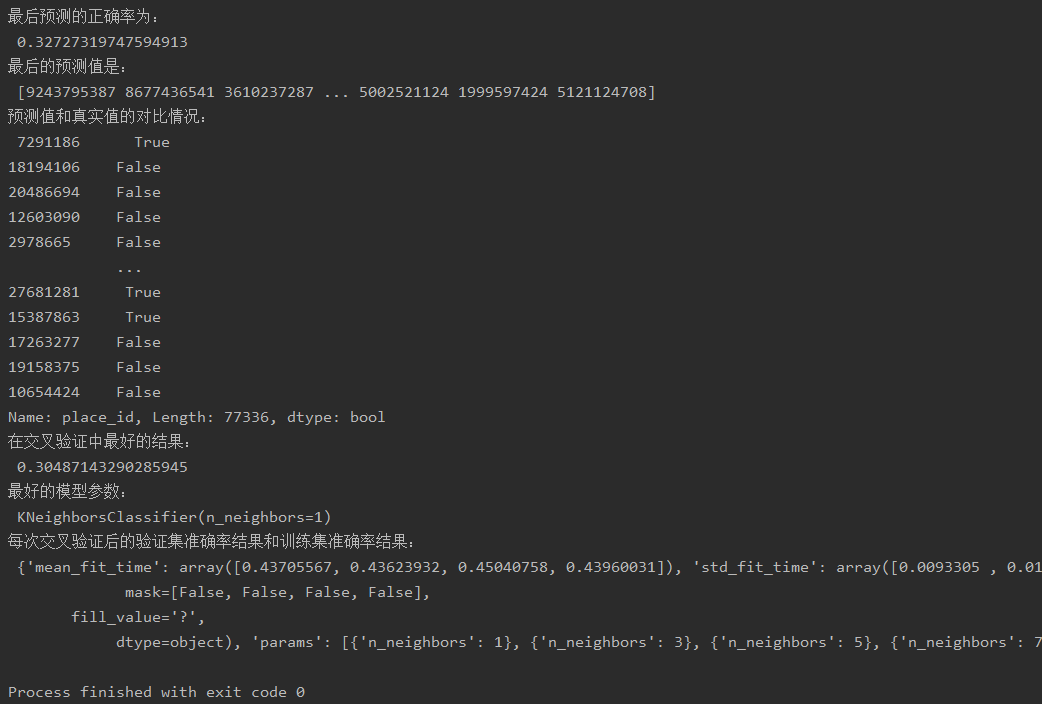
数据量太大如果全部跑的话最好用服务器去跑,这里从中截取了大概30w条数据,准确率偏低