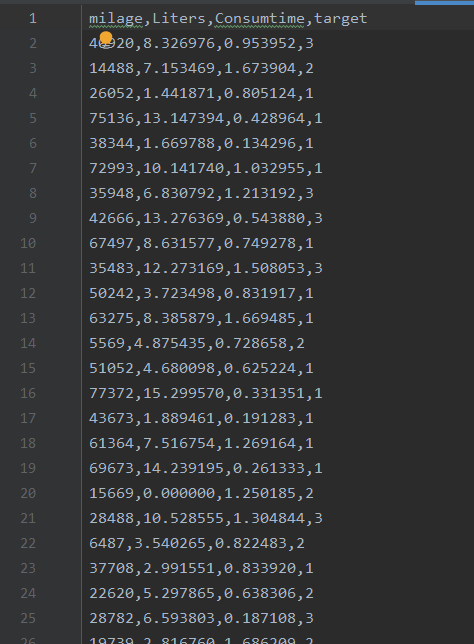
一、数据准备
二、任务目的
根据前三列数据预测最后一列的target数据
三、实现代码
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier # 获取数据 iris = load_iris() # 数据基本处理 x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2,) # 特征工程-特征预处理 transfer = StandardScaler() x_train = transfer.fit_transform(x_train) x_test = transfer.fit_transform(x_test) # 机器学*-KNN # 实例化一个估计器 estimator = KNeighborsClassifier(n_neighbors=5) # 模型训练 estimator.fit(x_train, y_train) # 模型评估 y_per = estimator.predict(x_test) print("预测值是: ", y_per) print("预测值和真实值的对比是: ", y_per == y_test) # 准确率计算 score = estimator.score(x_test, y_test) print("准确率为: ", score)
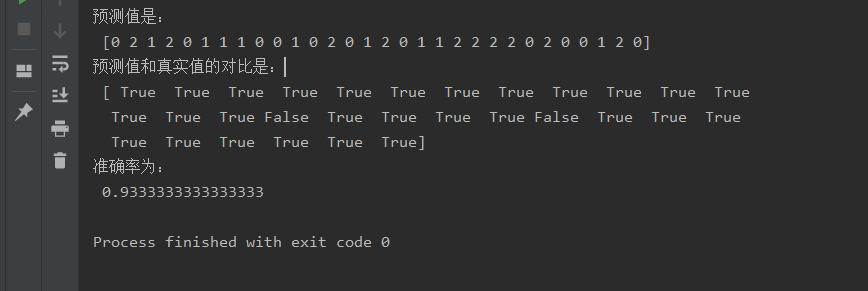
四、运行结果