一、流程分析

二、代码部分
1 package wc 2 3 import org.apache.spark.rdd.RDD 4 import org.apache.spark.{SparkConf, SparkContext} 5 6 object Spark_WordCount { 7 8 def main(args: Array[String]): Unit = { 9 //建立和spark框架的连接 10 val sparConf = new SparkConf().setMaster("local").setAppName("WordCount") 11 val sc = new SparkContext(sparConf) 12 13 //执行业务操作 14 //1.读取文件,获取一行一行的数据 15 //hello world 16 val lines:RDD[String] = sc.textFile("datas") 17 18 //2.将一行一行的数据进行拆分,形成一个一个的单词(分词) 19 //扁平化:将整体拆分成个体的操作 20 //"hello world"=>hello,world 21 val words: RDD[String] = lines.flatMap(_.split(" ")) 22 23 //3.将数据根据单词进行分组,便于统计 24 //(hello,hello,hello),(world,world) 25 val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word => word) 26 27 //4.对分组后的数据进行转换 28 //(hello,hello,hello),(world,world)=>(hello,3),(world,2) 29 val wordToCount = wordGroup.map{ 30 case (word,list)=>{ 31 (word,list.size) 32 } 33 } 34 35 //5.将转换结果采集到控制台打印出来 36 val array: Array[(String, Int)] = wordToCount.collect() 37 array.foreach(println) 38 //关闭连接 39 sc.stop() 40 } 41 }
三、运行结果

-------------------------------------------------------------------------------------分割线----------------------------------------------------------------------------------------------
另一种方式:
一、流程变化
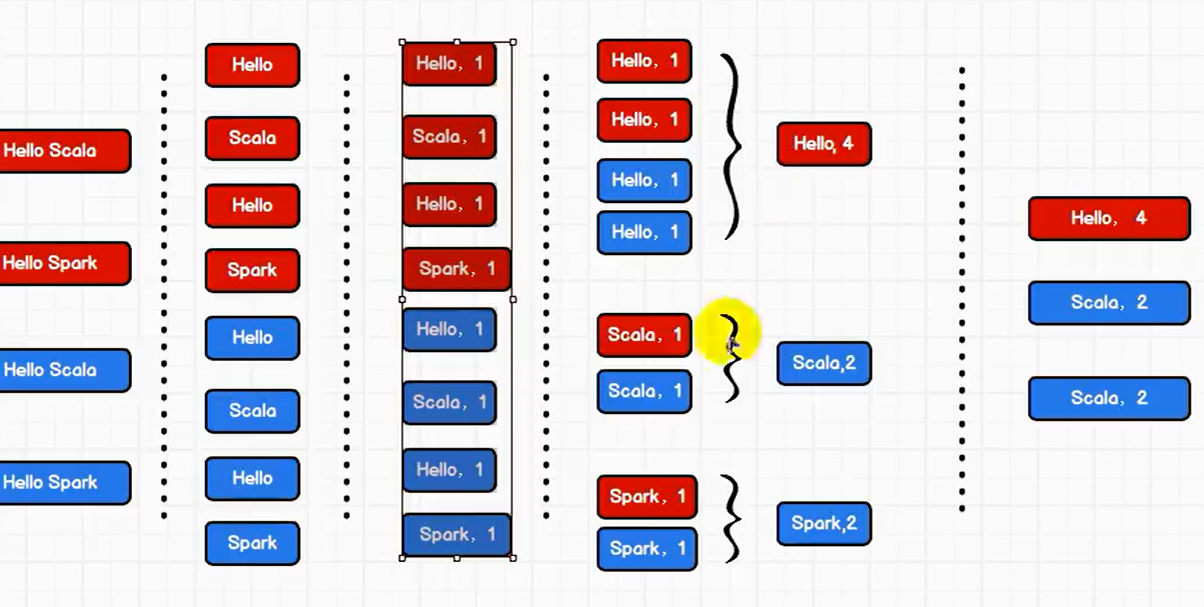
二、代码
1 package wc 2 3 import org.apache.spark.rdd.RDD 4 import org.apache.spark.{SparkConf, SparkContext} 5 6 object Spark_WordCount02 { 7 8 def main(args: Array[String]): Unit = { 9 10 val sparConf = new SparkConf().setMaster("local").setAppName("WordCount") 11 val sc = new SparkContext(sparConf) 12 13 val lines:RDD[String] = sc.textFile("datas") 14 15 val words: RDD[String] = lines.flatMap(_.split(" ")) 16 17 val wordToOne: RDD[(String, Int)] = words.map( 18 word => (word, 1) 19 ) 20 21 val wordGroup: RDD[(String, Iterable[(String, Int)])] = wordToOne.groupBy( 22 t => t._1 23 ) 24 25 val wordToCount: RDD[(String, Int)] = wordGroup.map { 26 case (word, list) => { 27 list.reduce( 28 (t1, t2) => { 29 (t1._1, t1._2 + t2._2) 30 } 31 ) 32 } 33 } 34 //5.将转换结果采集到控制台打印出来 35 val array: Array[(String, Int)] = wordToCount.collect() 36 array.foreach(println) 37 //关闭连接 38 sc.stop() 39 } 40 }
-------------------------------------------------------------------------------------分割线----------------------------------------------------------------------------------------------
spark提供了更多的功能,可以将分组和聚合用一个方法来实现
1 package wc 2 3 import org.apache.spark.rdd.RDD 4 import org.apache.spark.{SparkConf, SparkContext} 5 6 object Spark_WordCount03 { 7 8 def main(args: Array[String]): Unit = { 9 10 val sparConf = new SparkConf().setMaster("local").setAppName("WordCount") 11 val sc = new SparkContext(sparConf) 12 13 val lines:RDD[String] = sc.textFile("datas") 14 15 val words: RDD[String] = lines.flatMap(_.split(" ")) 16 17 val wordToOne: RDD[(String, Int)] = words.map( 18 word => (word, 1) 19 ) 20 21 //spark提供了更多的功能,可以将分组和聚合用一个方法来实现 22 //reduceByKey:对相同的key的数据,可以对value进行reduce整合 23 val wordToCount=wordToOne.reduceByKey(_+_) 24 25 val array: Array[(String, Int)] = wordToCount.collect() 26 array.foreach(println) 27 //关闭连接 28 sc.stop() 29 } 30 }
-------------------------------------------------------------------------------------分割线--------------------------------------------------------------------------------------------------------
cmd中运行wordCount
sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
