一、简介
1968年,Cover和Hart最早提出了K-近邻算法。
以下引用自百度百科:
K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。
该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
假设两个样本为m(m1,m2,m3),n(n1,n2,n3),则距离公式为
\begin{align}\notag \sqrt{(m1-n1)^{2}+(m2-n2)^{2}+(m3-n3)^{2}} \end{align}
主要思想: - 物以类聚,人以群分 - 少数服从多数二、优缺点
1. 优点
- 简单,易于理解、实现
- 无需估计参数
- 无需训练
2. 缺点
- 计算量大,内存开销大
- 必须指定K值,K值选择不当会影响精度
- 当样本数量不平衡时, 即一种样本容量很大, 而其他几种容量很小时, 当输入一个新样本时, 该样本的近邻中容量大的样本占多数, 会产生误差。
三、API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, algorithm='auto')
n_neighbors:使用的邻居数,整形,可选,默认为5
algorithm:用于计算最近邻居的算法,可选,{'auto', 'ball_tree', 'kd_tree', 'brute'}
ball_tree:使用BallTreekd_tree:使用KDTreebrute:使用暴力算法auto:根据传递给fit方法的值来决定最合适的算法。
四、简单示例
数据选择scikit-learn提供的鸢尾花数据集。
from sklearn.datasets import load_iris
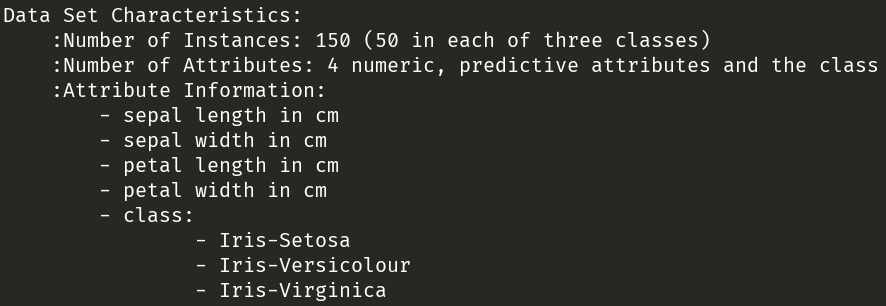
从上图可以看出,鸢尾花数据集由150个样本组成。
包含三种鸢尾花,分别为山鸢尾(Iris-Setosa)、变色鸢尾(Iris-Versicolour)和维吉尼亚鸢尾(Iris-Virginica),每种鸢尾花包含50个样本。
每个样本包含4个特征,分别为萼片长度(sepal length)、萼片宽度(sepal width)、花瓣长度(petal length)和花瓣宽度(petal width)。



下面附上代码:
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 实例化数据集
li = load_iris()
# 分割数据集到训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(li.data,li.target,test_size=0.25)
# 将数据进行标准化
stds = StandardScaler()
x_train = stds.fit_transform(x_train)
x_test = stds.transform(x_test)
# KNN算法进行预测
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train,y_train)
# 得出准确率
print("准确率为:",knn.score(x_test,y_test))
程序输出结果如下图,由于分割训练集和测试集是随机分割,所以每次准确率不一样。

不管前方的路有多苦,只要走的方向正确,不管多么崎岖不平,都比站在原地更接近幸福。 ——《千与千寻》