有类型转换:
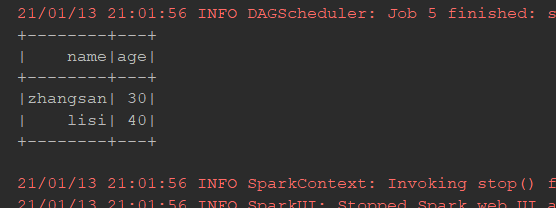
map:
@Test def trans(): Unit = { // 3. flatMap val ds1 = Seq("hello spark", "hello hadoop").toDS ds1.flatMap( item => item.split(" ") ).show() // 4. map val ds2 = Seq(Person("zhangsan", 15), Person("lisi", 20)).toDS() ds2.map(person => Person(person.name, person.age * 2)).show() // 5. mapPartitions ds2.mapPartitions( // iter 不能大到每个 Executor 的内存放不下, 不然就会 OOM // 对每个元素进行转换, 后生成一个新的集合 iter => { val result = iter.map(person => Person(person.name, person.age * 2)) result } ).show() }


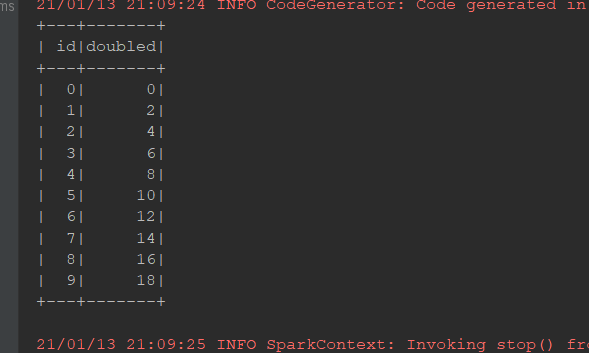
transform:
@Test def trans1(): Unit = { val ds = spark.range(10)//生成0-9的十个数字 ds.transform(dataset => dataset.withColumn("doubled", 'id * 2)) .show() }
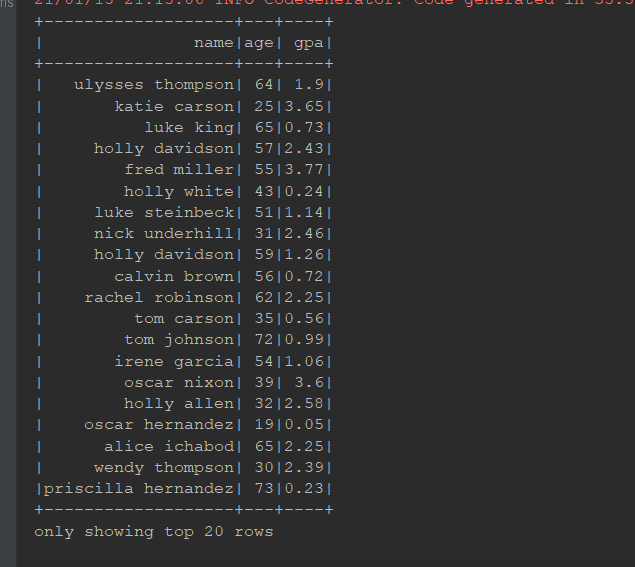
as:
@Test def as(): Unit = { // 1. 读取 val schema = StructType( Seq( StructField("name", StringType), StructField("age", IntegerType), StructField("gpa", FloatType) ) ) val df: DataFrame = spark.read .schema(schema) .option("delimiter", " ") .csv("dataset/studenttab10k") // 2. 转换 // 本质上: Dataset[Row].as[Student] => Dataset[Student] // Dataset[(String, int, float)].as[Student] => Dataset[Student] val ds: Dataset[Student] = df.as[Student] // 3. 输出 ds.show() }
filiter:
@Test def filter(): Unit = { val ds = Seq(Person("zhangsan", 15), Person("lisi", 20)).toDS() ds.filter( person => person.age > 15 ).show() }
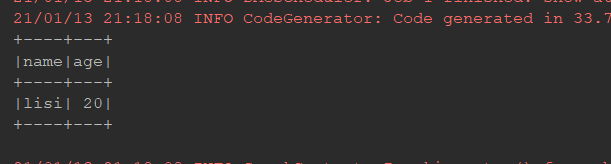
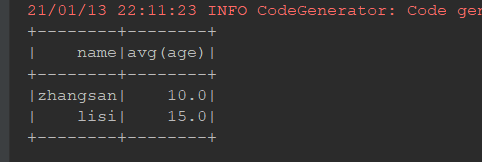
groupbykey:
@Test def groupByKey(): Unit = { val ds = Seq(Person("zhangsan", 15), Person("zhangsan", 16), Person("lisi", 20)).toDS() // select count(*) from person group by name val grouped: KeyValueGroupedDataset[String, Person] = ds.groupByKey(person => person.name)//指定其key的数值就好 val result: Dataset[(String, Long)] = grouped.count() result.show() }
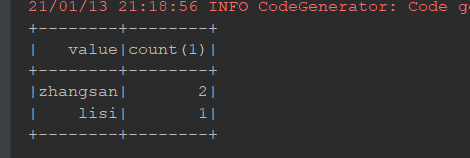
split:
@Test def split(): Unit = { val ds = spark.range(15) // randomSplit, 切多少份, 权重多少 val datasets: Array[Dataset[lang.Long]] = ds.randomSplit(Array(5, 2, 3))//给你五个你两个给你三个 datasets.foreach(_.show()) // sample ds.sample(withReplacement = false, fraction = 0.4).show() }

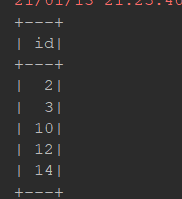
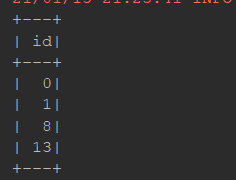

orderBy:
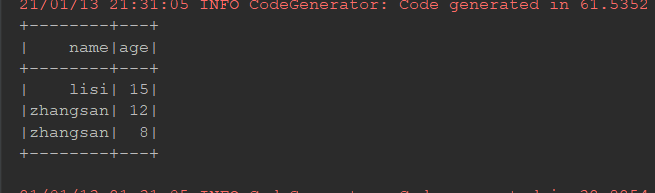
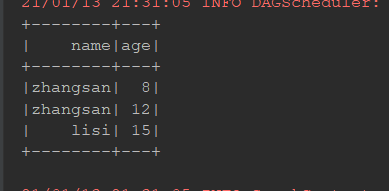
@Test def sort(): Unit = { val ds = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS() ds.orderBy('age.desc).show() // select * from ... order by ... asc(desc是降序asc是升序) ds.sort('age.asc).show() }
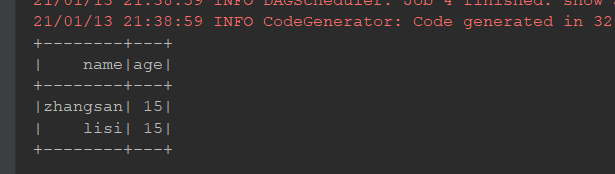
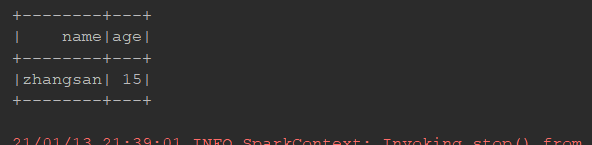
去重:
@Test
def dropDuplicates(): Unit = {
val ds = spark.createDataset(Seq(Person("zhangsan", 15), Person("zhangsan", 15), Person("lisi", 15)))
ds.distinct().show()//默认去重使用
ds.dropDuplicates("age").show()//指定去重使用
}
集合操作:
@Test def collection(): Unit = { val ds1 = spark.range(1, 10) val ds2 = spark.range(5, 15) // 差集 ds1.except(ds2).show() // 交集 ds1.intersect(ds2).show() // 并集 ds1.union(ds2).show() // limit ds1.limit(3).show() }

无类型转换:
选择:
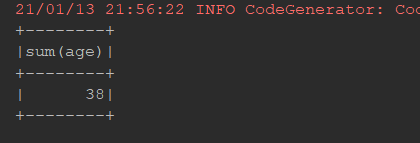
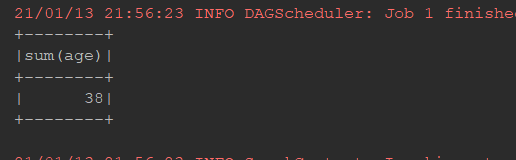
@Test def select(): Unit = { val ds = Seq(Person("zhangsan", 12), Person("lisi", 18), Person("zhangsan", 8)).toDS // select * from ... // from ... select ... // 在 Dataset 中, select 可以在任何位置调用 // select count(*) ds.select('name).show() ds.selectExpr("sum(age)").show() import org.apache.spark.sql.functions._ ds.select(expr("sum(age)")).show() }

列操作:
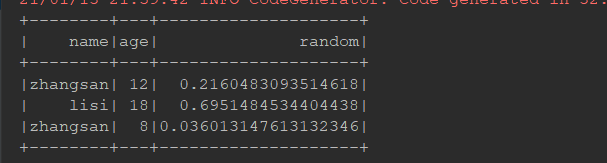
@Test def column(): Unit = { val ds = Seq(Person("zhangsan", 12), Person("lisi", 18), Person("zhangsan", 8)).toDS import org.apache.spark.sql.functions._ // select rand() from ... // 如果想使用函数功能 // 1. 使用 functions.xx // 2. 使用表达式, 可以使用 expr("...") 随时随地编写表达式 ds.withColumn("random", expr("rand()")).show() ds.withColumn("name_new", 'name).show() ds.withColumn("name_jok", 'name === "").show()//显示比较的结果 ds.withColumnRenamed("name", "new_name").show() }


groupby:
@Test def groupBy(): Unit = { val ds = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS() // 为什么 GroupByKey 是有类型的, 最主要的原因是因为 groupByKey 所生成的对象中的算子是有类型的 // ds.groupByKey( item => item.name ).mapValues() // 为什么 GroupBy 是无类型的, 因为 groupBy 所生成的对象中的算子是无类型的, 针对列进行处理的 import org.apache.spark.sql.functions._ ds.groupBy('name).agg(mean("age")).show() }