一、RDD概念
1、RDD在哪里:

2、RDD是什么:
是一个容错的, 并行的数据结构, 可以让用户显式地将数据存储到磁盘和内存中, 并能控制数据的分区.RDD 作为数据结构, 本质上是一个只读的分区记录集合. 一个 RDD 可以包含多个分区, 每个分区就是一个 DataSet 片段.RDD 之间可以相互依赖, 如果 RDD 的每个分区最多只能被一个子 RDD 的一个分区使用,则称之为窄依赖, 若被多个子 RDD 的分区依赖,则称之为宽依赖. 不同的操作依据其特性, 可能会产生不同的依赖. 例如 map 操作会产生窄依赖, 而 join 操作则产生宽依赖.
3、RDD的特点:
RDD 是一个编程模型
RDD 允许用户显式的指定数据存放在内存或者磁盘RDD 是分布式的,
用户可以控制 RDD 的分区RDD 提供了丰富的操作RDD 提供了 map, flatMap, filter 等操作符,
用以实现 Monad 模式RDD 提供了 reduceByKey, groupByKey 等操作符,
用以操作 Key-Value 型数据RDD 提供了 max, min, mean 等操作符, 用以操作数字型的数据
RDD 是混合型的编程模型, 可以支持迭代计算, 关系查询, MapReduce, 流计算
RDD 是只读的
RDD 之间有依赖关系, 根据执行操作的操作符的不同, 依赖关系可以分为宽依赖和窄依赖

4、补充:
RDD的分区:
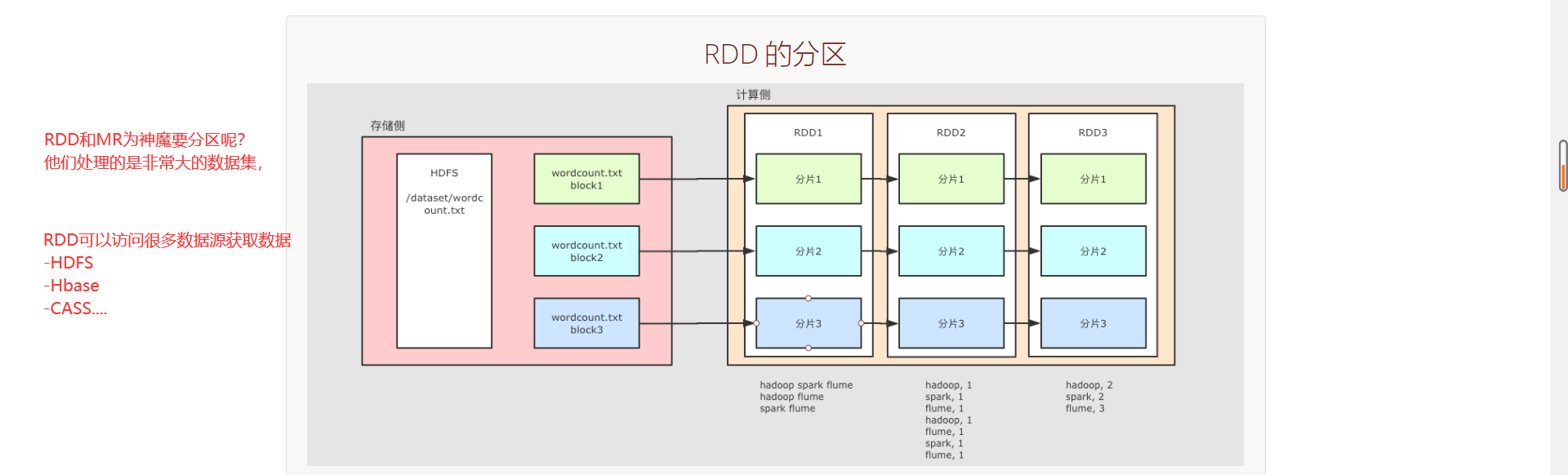
整个 WordCount 案例的程序从结构上可以用上图表示, 分为两个大部分
存储
文件如果存放在 HDFS 上, 是分块的, 类似上图所示, 这个 wordcount.txt 分了三块
计算
Spark 不止可以读取 HDFS, Spark 还可以读取很多其它的数据集, Spark 可以从数据集中创建出 RDD
例如上图中, 使用了一个 RDD 表示 HDFS 上的某一个文件, 这个文件在 HDFS 中是分三块, 那么 RDD 在读取的时候就也有三个分区, 每个 RDD 的分区对应了一个 HDFS 的分块
后续 RDD 在计算的时候, 可以更改分区, 也可以保持三个分区, 每个分区之间有依赖关系, 例如说 RDD2 的分区一依赖了 RDD1 的分区一
RDD 之所以要设计为有分区的, 是因为要进行分布式计算, 每个不同的分区可以在不同的线程, 或者进程, 甚至节点中, 从而做到并行计算

二、RDD代码
1、SparkCore的入口SparkContext
SparkContext 是 spark-core 的入口组件, 是一个 Spark 程序的入口, 在 Spark 0.x 版本就已经存在 SparkContext 了, 是一个元老级的 API
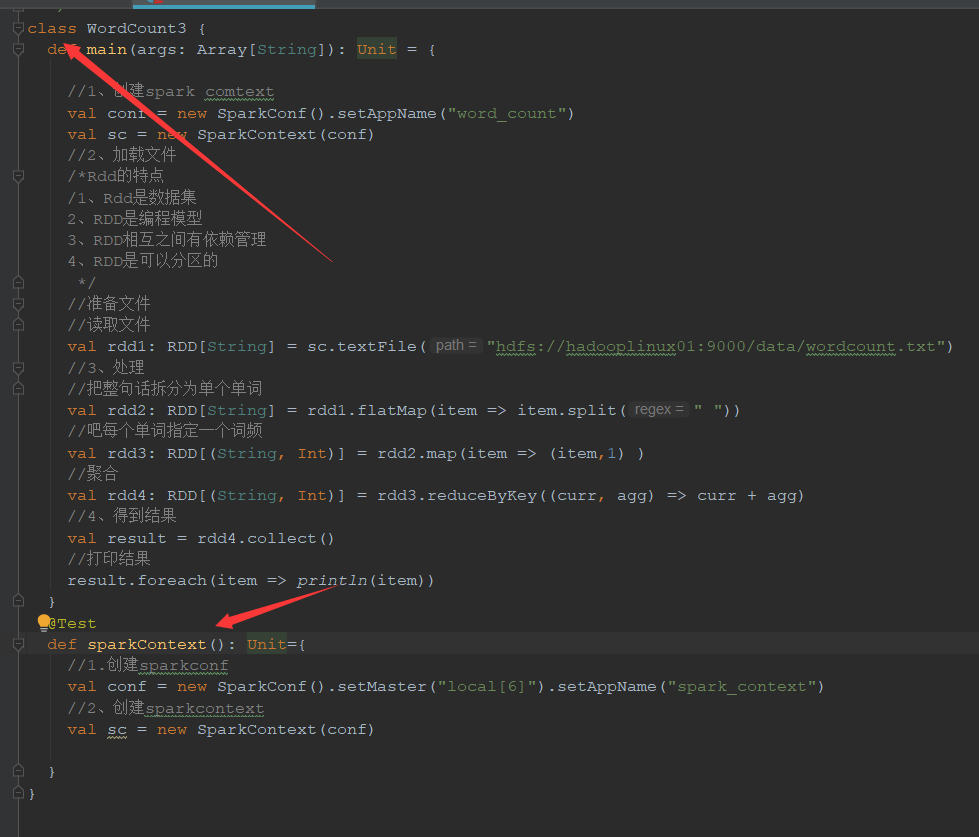
package cn.itcast.spark.rdd import junit.framework.Test import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.rdd.RDD /** * @Author 带上我快跑 * @Data 2021/1/8 19:00 * @菩-萨-说-我-写-的-都-对@ */ class WordCount3 { def main(args: Array[String]): Unit = { //1、创建spark comtext val conf = new SparkConf().setAppName("word_count") val sc = new SparkContext(conf) //2、加载文件 /*Rdd的特点 /1、Rdd是数据集 2、RDD是编程模型 3、RDD相互之间有依赖管理 4、RDD是可以分区的 */ //准备文件 //读取文件 val rdd1: RDD[String] = sc.textFile("hdfs://hadooplinux01:9000/data/wordcount.txt") //3、处理 //把整句话拆分为单个单词 val rdd2: RDD[String] = rdd1.flatMap(item => item.split(" ")) //吧每个单词指定一个词频 val rdd3: RDD[(String, Int)] = rdd2.map(item => (item,1) ) //聚合 val rdd4: RDD[(String, Int)] = rdd3.reduceByKey((curr, agg) => curr + agg) //4、得到结果 val result = rdd4.collect() //打印结果 result.foreach(item => println(item)) } @Test def sparkContext(): Unit={ //1.创建sparkconf val conf = new SparkConf().setMaster("local[6]").setAppName("spark_context") //2、创建sparkcontext val sc = new SparkContext(conf) } }
2、RDD的创建方式:(RDD弹性分布式数据集)
2.1通过本地集合创建RDD

2.2通过外部数组创建RDD

2.3通过RDD衍生出RDD

-
source是通过读取 HDFS 中的文件所创建的 -
words是通过source调用算子map生成的新 RDD

