1、独立应用的形式
(上线、放在集群中运行)
1.1本地运行的方式
idea创建web项目添加scala和maven依赖。
配置pom文件:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>groupId</groupId> <artifactId>sparkCESHI</artifactId> <version>1.0-SNAPSHOT</version> <properties> <scala.version>2.11.8</scala.version> <spark.version>2.2.0</spark.version> <slf4j.version>1.7.16</slf4j.version> <log4j.version>1.2.17</log4j.version> </properties> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>jcl-over-slf4j</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>${slf4j.version}</version> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>${log4j.version}</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.10</version> <scope>provided</scope> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.0</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> </configuration> </plugin> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.0</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.1.1</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass></mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
编写代码:
package cn.itcast.spark.rdd import java.util; import org.apache.spark.{SparkConf,SparkContext} /** * @Author 带上我快跑 * @Data 2021/1/8 13:33 * @菩-萨-说-我-写-的-都-对@ */ object WordCount { def main(args: Array[String]): Unit = { //1、创建spark comtext val conf = new SparkConf().setMaster("local[6]").setAppName("word_count") val sc = new SparkContext(conf) //2、加载文件 //准备文件 //读取文件 val rdd1 = sc.textFile("dataset/wordcount.txt") //3、处理 //把整句话拆分为单个单词 val rdd2 = rdd1.flatMap(item => item.split(" ")) //吧每个单词指定一个词频 val rdd3 = rdd2.map( item => (item,1) ) //聚合 val rdd4=rdd3.reduceByKey((curr,agg) => curr + agg) //4、得到结果 val result = rdd4.collect() //打印结果 result.foreach(item => println(item)) } }
运行结果如下:

1.2提交运行的方式
修改源程序代码:
package cn.itcast.spark.rdd import org.apache.spark.{SparkConf, SparkContext} /** * @Author 带上我快跑 * @Data 2021/1/8 14:27 * @菩-萨-说-我-写-的-都-对@ */ object WordCount2 { def main(args: Array[String]): Unit = { //1、创建spark comtext val conf = new SparkConf().setAppName("word_count") val sc = new SparkContext(conf) //2、加载文件 //准备文件 //读取文件 val rdd1 = sc.textFile("hdfs://hadooplinux01:9000/data/wordcount.txt") //3、处理 //把整句话拆分为单个单词 val rdd2 = rdd1.flatMap(item => item.split(" ")) //吧每个单词指定一个词频 val rdd3 = rdd2.map( item => (item,1) ) //聚合 val rdd4=rdd3.reduceByKey((curr,agg) => curr + agg) //4、得到结果 val result = rdd4.collect() //打印结果 result.foreach(item => println(item)) } }
运行package:
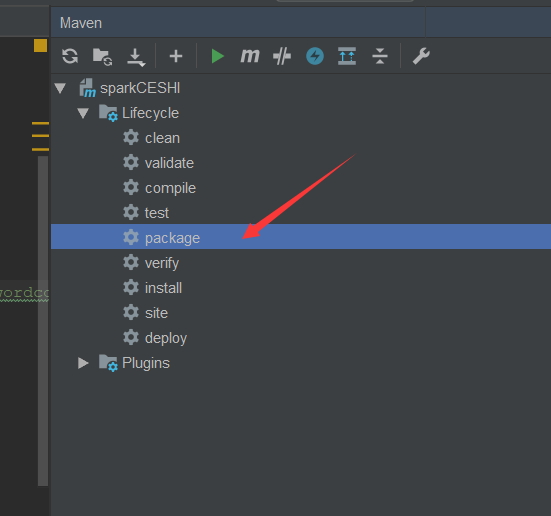
之后点击target:
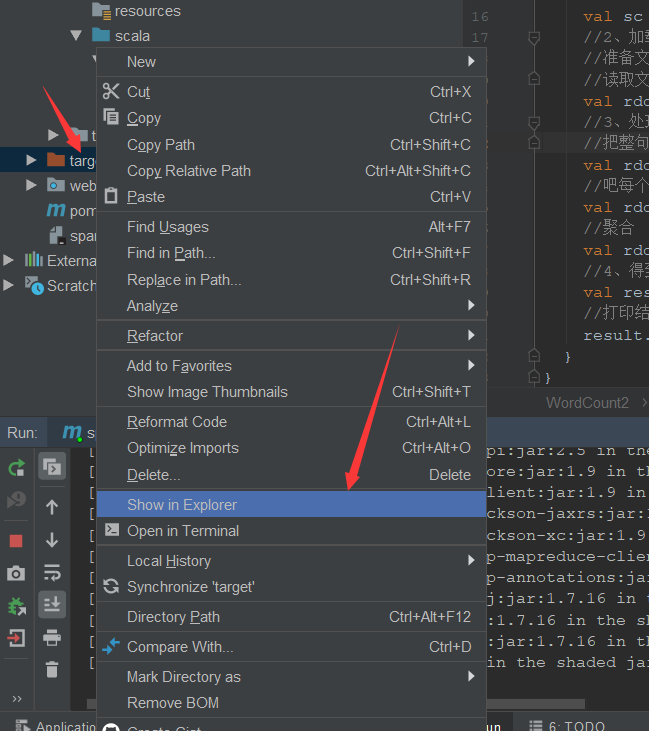
我们就操作这个最小的jar就ok 了:
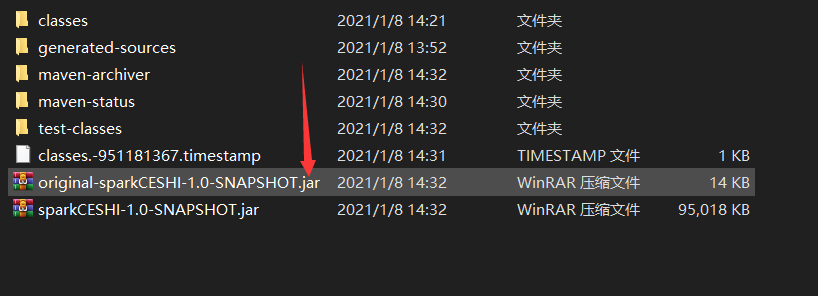
将他上传到虚拟机上。开启spark
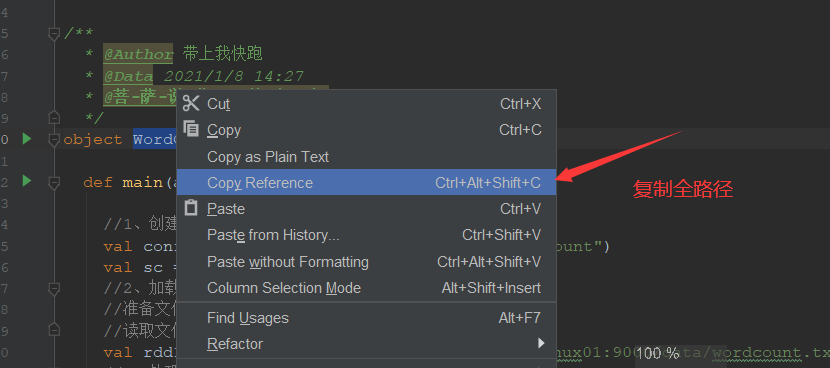
获取运行class的全路径。

执行此命令。进行spark-submi t
