1、MapReduce任务提交和切片源码
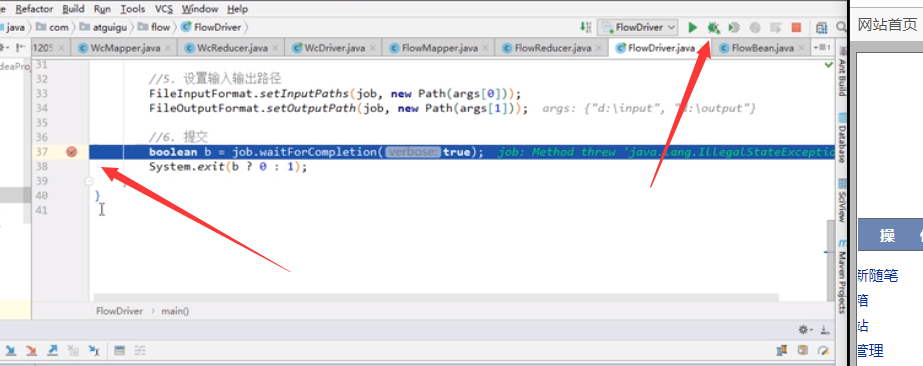
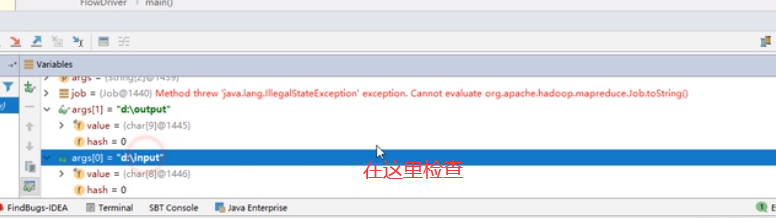
debug能力(怎样使用):

2、各种inputFormat以及自定inputFormat 自定义inputFormat代码实现

之后就是自定义的inputformat
无论HDFS还是MapReduce,在处理小文件时效率都非常低,但又难免面临处理大量小文件的场景,此时,就需要有相应解决方案。可以自定义InputFormat实现小文件的合并。
1.需求
将多个小文件合并成一个SequenceFile文件(SequenceFile文件是Hadoop用来存储二进制形式的key-value对的文件格式),SequenceFile里面存储着多个文件,存储的形式为文件路径+名称为key,文件内容为value。
原文件:



源代码如下:
package inputformat;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import java.io.IOException;
public class TextInputFormat extends FileInputFormat<Text, BytesWritable> {
//保证文件不被切片
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return super.isSplitable(context, filename);
}
public RecordReader<Text, BytesWritable> createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
return new WholeFileRecordReader();
}
}
package inputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import javax.xml.soap.Text;
import java.io.IOException;
public class WcDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job =Job.getInstance(new Configuration());
job.setJarByClass(WcDriver.class);
job. setMapOutputKeyClass(Text.class);
job. setMapOutputValueClass (BytesWritable.class);
job. setOutputKeyClass(Text .class);
job. setOutputValueClass ( BytesWritable.class);
job. setInputFormatClass (TextInputFormat.class);
FileInputFormat. setInputPaths(job, new Path("d:\input" ));
FileOutputFormat. setOutputPath(job, new Path("d:\loutput"));
boolean b=job.waitForCompletion(true);
System.exit(b?0:1);
}
}
package inputformat;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
//自定义RR,处理一个文件,把文件直接都成kv值
public class WholeFileRecordReader extends RecordReader<Text, BytesWritable>{
private boolean notRead=true;
private Text key=new Text();
private BytesWritable value=new BytesWritable();
private FSDataInputStream inputStream;
private FileSplit fs;
//进行初始化
public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
//四局属于套路。转换切片类型为文件切片
fs=(FileSplit)inputSplit;
//通过切片获取路径
Path path=fs.getPath();
//通过路径获取文件系统
FileSystem fileSystem=path.getFileSystem(taskAttemptContext.getConfiguration());
//开流
inputStream=fileSystem.open(path);
}
//尝试读取下一组kv值如果读到了返回true反之亦然
public boolean nextKeyValue() throws IOException, InterruptedException {
if(notRead)
{
//具体读文件的过程
//首先是读key
key.set(fs.getPath().toString());
//读value
byte[] buf=new byte[(int)fs.getLength()];
inputStream.read(buf);
value.set(buf,0,buf.length);
notRead=false;
return true;
}
else
{
return false;
}
}
//获取当前读到的key
public Text getCurrentKey() throws IOException, InterruptedException {
return key;
}
//获取当前读到的value
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return value;
}
//读取其进度
public float getProgress() throws IOException, InterruptedException {
return notRead?0:1;
}
//关闭资源
public void close() throws IOException {
IOUtils.closeStream(inputStream);
}
}