目 录
1. 回归方程
2. 回归分析的主要内容
3. 回归模型的一般形式
4. 回归分析与相关分析
1. 回归方程
回归分析是处理变量x与y之间的关系的一种统计方法和技术。所研究的变量之间的关系:即当给定x的值,y的值不能确定,只能通过一定的概率分布来描述。于是,称给定x时y的条件数学期望 f(x) = E(y | x) 为随机变量y对x的回归函数,或称为随机变量y对x的均值回归函数。该式从平均意义上刻画了变量x与y之间的统计规律。
在实际问题中,把x称为自变量,y称为因变量。如果要由x预测y,就要利用x,y的观测值,即样本观测值 (x1, y1), (x2, y2), (x3, y3), ... , (xn, yn) 来建立一个模型,当给定x值后,就代入此模型中算出y一个值,这个值就称为y的预测值。如何建立这个模型,这需要从样本观测值 (xi, yi) 出发,观察 (xi, yi)在坐标系上的分布情况,若样本点基本上分布在一条直线的周围,因而要确定y与x的关系,可考虑用一个线性函数来描述:y = α + βx。函数中α,β尚不知道,这就需要根据样本数据去进行估计。
当由样本数据估计出α,β的值后,以估计值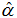 ,
,![]() 分别代替式 y = α + βx 中的α,β,得方程
分别代替式 y = α + βx 中的α,β,得方程 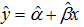 ,这样的方程就称为回归方程。这是因为因变量y与自变量x的关系呈线性关系,故称式为y对x的线性回归方程。又因为的建立依赖于观察或试验累积的样本数据,所以又称为经验回归方程,相对的称为y = α + βx为理论回归方程。理论回归方程是设想把所研究问题的总体中每一个体的 (x, y) 值都测量了,利用全部结果所建立的的回归方程y = α + βx,这在实际中办不到的。 理论回归方程中的α是y = α + βx所画的直线在y轴上的截距,β为直线的斜率,分别称为回归常数和回归系数。而方程中的系数,
,这样的方程就称为回归方程。这是因为因变量y与自变量x的关系呈线性关系,故称式为y对x的线性回归方程。又因为的建立依赖于观察或试验累积的样本数据,所以又称为经验回归方程,相对的称为y = α + βx为理论回归方程。理论回归方程是设想把所研究问题的总体中每一个体的 (x, y) 值都测量了,利用全部结果所建立的的回归方程y = α + βx,这在实际中办不到的。 理论回归方程中的α是y = α + βx所画的直线在y轴上的截距,β为直线的斜率,分别称为回归常数和回归系数。而方程中的系数,![]() 被称为经验回归常数和经验回归系数。
被称为经验回归常数和经验回归系数。
2. 回归分析的主要内容
回归分析研究的主要对象是客观事物变量间的关系,它是建立在对客观事物进行大量试验和观察的基础上,用来寻找隐藏在那些看上去是不确定的现象中的统计规律性的统计方法。回归分析是通过建立统计模型研究变量间相互关系的密切程度、结构状态、模型预测的一种有力工具。
如果从19世纪初(1809年)Gauss提出最小二乘法算起,回归分析的历史已有二百年,从经典的回归分析方法到近代的回归分析方法,它们所研究的内容已非常丰富。如果按研究的方法来划分,回归分析研究的范围大致如下:

3. 回归模型的一般形式
若变量x1, x2, x3, ..., xp与y之间是相关关系,常意味着每当x1, x2, x3, ..., xp取值确定后,y便有相应的概率分布与之对应。随机变量y与相关变量x1, x2, x3, ..., xp之间的概率模型为 y=f(x1, x2, x3, ..., xp)+ε,其中随机变量y称为被解释变量(因变量),x1, x2, x3, ..., xp称为解释变量(自变量)。f(x1, x2, x3, ..., xp)为一般变量x1, x2, x3, ..., xp的确定性关系,ε为随机误差。正是因为随机误差项ε的引入,才将变量之间的关系描述为一个随机方程,可以借助随机数学方法研究y与x1, x2, x3, ..., xp的关系。随机误差主要包括下列因素的影响:
(1)由于人们认识的局限或时间、费用、数据质量等制约未引入回归模型但又对回归被解释变量y有影响的因素;
(2)样本数据的采集过程中变量观测值的观测误差的影响;
(3)理论模型设定误差的影响;
(4)其他随机因素的影响。
模型 y=f(x1, x2, x3, ..., xp)+ε 清楚的表达了变量x1, x2, x3, ..., xp与随机变量y的相关关系,它由两部分组成:一部分是确定性函数关系,由回归函数f(x1, x2, x3, ..., xp)给出;另一部分是随机误差项 ε。由此可见模型准确地表达了相关关系那种既有联系又不确定的特点。
当概率模型中的回归函数为线性函数时,既有 y=β0+β1x1+β1x2+...+βpxp+ε ,其中β0, β1, β2, ..., βp为未知参数,常称为回归系数。
如果(xi1, xi2, ..., xip; yi), i = 1, 2, ..., n是式 y=β0+β1x1+β1x2+...+βpxp+ε 中变量(x1, x2, ..., xp; y)的一组观测值,则线性回归模型可表示为
yi = β0+β1xi1+β2xi2+...+βpxip+εi , i = 1, 2, ..., n.
为了估计模型参数的需要,古典线性回归模型通常应满足以下几个基本假设:
(1)解释变量x是非随机变量,观测值x1, x2, ..., xp是常数;
(2)等方差及不相关的假定条件为
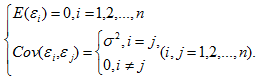
这个条件称为Gauss-Markov条件。在此条件下,便可得到关于回归系数的最小二乘估计及σ2估计的一些重要性质,如回归系数的最小二乘估计是回归系数的最小方差线性无偏估计等;
(3)正太分布的假定条件为
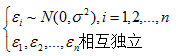
在此条件下便可得到关于回归系数的最小二乘估计及σ2估计的进一步结果,如它们分别是回归系数及σ2的最小方差无偏估计等,并且可以做回归的显著性检验及区间估计;
(4)为了便于数学上的处理,还要求 n > p,即样本容量的个数要多于解释变量的个数。
在整个回归分析中,线性回归的数学模型最为重要。一方面是因为线性回归的应用最广泛;另一方面是只有在回归模型为线性的假定下,才能得到比较深入和一般的结果;再就是有许多非线性的回归模型可以通过适当的转化变为线性回归问题进行处理。
对线性回归模型通常要研究的问题有:
(1)如何根据样本(xi1, xi2, ..., xip ; yi),i = 1, 2, ..., n求出β0, β1, β2, ..., βp及方差σ2的估计;
(2)对回归方程及回归系数的种种假设进行检验;
(3)如何根据回归方程进行预测和控制,以及如何进行实际问题的结构分析。
4. 回归分析与相关分析
回归分析和相关分析都是研究变量之间的不确定关系的方式。应用中,两种分析方法相互结合和渗透,但它们研究的侧重点和应用面不同。它们的差别主要有以下几点:
(1)回归分析着重寻求变量之间近似的函数关系。相关分析着重寻求一些数量性的指标,以刻画有关变量之间关系深浅的程度;
(2)在回归分析中,变量y称为因变量,处在被解释的特殊地位。在相关分析中,变量y与变量x处于平等的地位,即研究变量y与变量x的密切程度与研究变量x与变量y的密切程度是一样的;
(3)相关分析中所涉及的变量y与x全是随机变量。而回归分析中,因变量y是随机变量,自变量x可以是随机变量,也可以是非随机的确定变量。通常的回归模型中,总是假定x是非随机的固定变量;
(4)相关分析的研究主要是为刻画两类变量间线性相关的密切程度。而回归分析不仅可以揭示变量x对变量y的影响大小,还可以由回归方程进行预测和控制。
由于回归分析与相关分析的研究侧重不同,使得它们的研究方法也大不相同。