最近工程中用到JPA,头一次接触,踩了不少坑。刚好复习到JDBC,发现JPA用起来真是很简单。就对比一下这两者的区别
总结:JDBC是更接近数据库SQL的抽象,使用时依然使用的是SQL。优点是靠近底层,效率高。缺点:使用起来太繁琐。JPA是基于ORM的一套规范,是更高层次对对象的抽象,使用对象来进行增删改查,这就大大降低了使用的繁琐度。但是JPA的实现依然是依赖于JDBC。
1. JDBC
1.1 示意图
1.2 访问数据库流程
1.3 代码示例
2.JPA
2.1 来源
2.2 示意图
2.3 代码示例
1. JDBC
一组标准API接口,由各个数据库厂商提供实现类,这些实现类就是驱动程序。
1.1 示意图
借用https://www.cnblogs.com/yunche/p/10279324.html的图,JDBC是从各个数据库的SQL中抽象出的一套使用SQL的标准,抽象级别是在SQL层面。

1.2 访问数据库流程
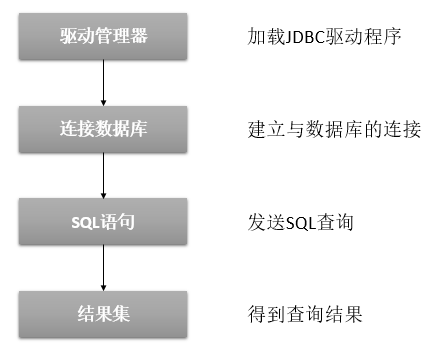
1.3 代码示例
package demo; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.Statement; public class ConnMySql { public static void main(String[] args) throws Exception { // 1.加载驱动,使用反射 Class.forName("com.mysql.jdbc.Driver"); // 2.使用DriverManager获取数据库连接, // 其中返回的Connection就代表了java程序和数据库的连接 // 不同数据库的URL写法需要查驱动文档,用户名、密码由DBA分配 Connection conn = DriverManager.getConnection( "jdbc:mysql://127.0.0.1:3306/select_test", "root", "0"); // 3.使用Connection来创建一个Statemnet对象 Statement stmt = conn.createStatement(); // 4.执行SQL语句 /* * Statement有三种执行sql语句的方法: * 1. execute可执行任何SQL语句。--返回一个boolean值, * 如果执行后第一个结果是ResultSet,则返回true,否则返回false * 2. executeQuery 执行Select语句 --返回查询到的结果集 * 3. executeUpdate 用于执行DML语句。 --返回一个整数代表被SQL语句影响的记录条数 */ ResultSet rs = stmt.executeQuery("select s.* , teacher_name from student_table s," + "teacher_table t where t.teacher_id = s.java_teacher"); // ResultSet有系列的getXxx(列索引 | 列名),用于获取记录指针指向行、特定列的值 // 不断地使用next将记录指针下移一行,如果依然指向有效行,则指针指向行的记录 while(rs.next()){ System.out.println(rs.getInt(1) + " " + rs.getString(2) + " " + rs.getString(3) + " " + rs.getString(4)); } // 关闭数据库资源 if(rs != null){ rs.close(); } if(stmt != null){ stmt.close(); } if(conn != null){ conn.close(); } } } // end ConnMySql
需要数据库数据:
drop database if exists select_test; create database select_test; use select_test; -- 为了保证从表参照的主表存在,通常应该先建主表 create table teacher_table ( -- auto_increment: 实际上代表所有数据库的自动编号策略,通常用作数据表的逻辑主键 teacher_id int auto_increment, teacher_name varchar(255), primary key(teacher_id) ); create table student_table ( -- 为本表建立主键约束 student_id int auto_increment primary key, student_name varchar(255), -- 指定java_teacher参照到teacher_table的teacher_id java_teacher int, foreign key(java_teacher) references teacher_table(teacher_id) ); insert into teacher_table values (null, 'Yeeku'); insert into teacher_table values (null, 'Sharfly'); insert into teacher_table values (null, 'Martine'); insert into student_table values (null, '张三', 1); insert into student_table values (null, '张三', 1); insert into student_table values (null, '李四', 1); insert into student_table values (null, '王五', 2); insert into student_table values (null, '_王五', 2); insert into student_table values (null, null, 2); insert into student_table values (null, '赵六', null);
上面代码需要使用MySQL数据库驱动,该驱动为:JAR:mysql-connector-java-3.1.10-bin.jar
输出:
|
结果: 1 张三 1 Yeeku 2 张三 1 Yeeku 3 李四 1 Yeeku 4 王五 2 Sharfly 5 _王五 2 Sharfly 6 null 2 Sharfly |
2.JPA
2.1 来源
由于JDBC依然需要使用SQL进行增删改查,需要自己做Java对象和数据库表的转换,工作量太大,因此出现很多对象关系映射(ORM)的框架,比如Hibernate。直接通过操作对象来操作数据库,编程的复杂度降低了。
当出现很多的ORM框架时,每个框架下操作数据库的方式、接口存在差异,当项目中框架迁移时就会出现很多问题,所以需要一套规范来同一,即JPA。
2.2 示意图
依然借用https://www.cnblogs.com/yunche/p/10279324.html的图示,JPA的抽象层次较高,是基于ORM的抽象。
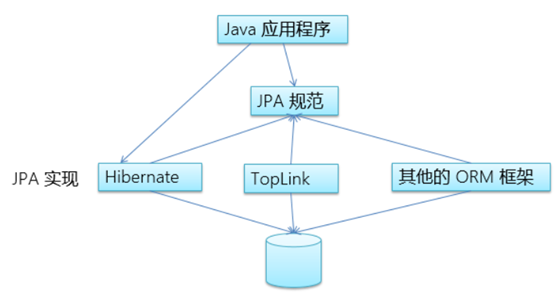
2.3 代码示例
只需要定义一个接口,通过函数的方式返回查询的对象,避免了直接使用SQL。
public interface PersonRepository extends JpaRepository<PersonEntity, String> { PersonEntity findByFirstName(String firstName); // 直接返回String类型的list是错误的,因为JPA基于对象的抽象,返回的依然是PersonEntity对象 List<String> getFirstNameList(); }
PersonEntity:
** * 对应person表 */ @Entity @Table(name = "person") public class PersonEntity { @Id private int personId; private String firstName; private String lastName; public PersonEntity(){ super(); } public PersonEntity(String firstName, String lastName) { super(); this.firstName = firstName; this.lastName = lastName; } public PersonEntity(int personId, String firstName, String lastName) { this.personId = personId; this.firstName = firstName; this.lastName = lastName; } public int getPersonId() { return personId; } public void setPersonId(int personID) { this.personId = personID; } public String getFirstName() { return firstName; } public void setFirstName(String firstName) { this.firstName = firstName; } public String getLastName() { return lastName; } public void setLastName(String lastName) { this.lastName = lastName; } }