参考:http://www.cnblogs.com/joemsu/p/7724623.html
数据结构
jdk1.8:数组、链表/红黑树(jdk1.7的是数组+链表)
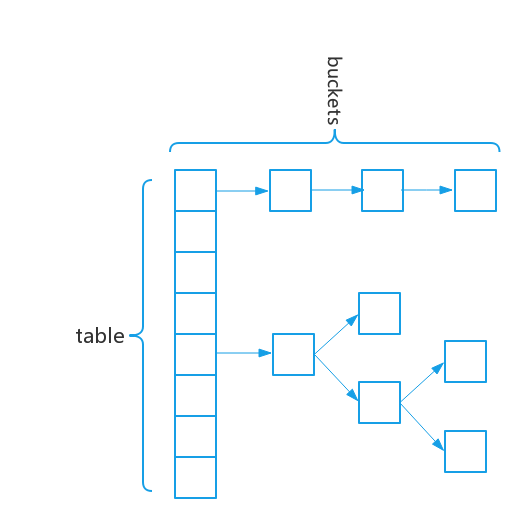
节点数据类型:
Node<K,V>(hash,key,value,next)
static class Node<K,V> implements Map.Entry<K,V> {
// key & value 的 hash值
final int hash;
final K key;
V value;
//指向下一个节点
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
参数
/默认初始化map的容量:16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//map的最大容量:2^30
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认的填充因子:0.75,能较好的平衡时间与空间的消耗
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//将链表(桶)转化成红黑树的临界值
static final int TREEIFY_THRESHOLD = 8;
//将红黑树转成链表(桶)的临界值
static final int UNTREEIFY_THRESHOLD = 6;
//转变成树的table的最小容量,小于该值则不会进行树化
static final int MIN_TREEIFY_CAPACITY = 64;
//上图所示的数组,长度总是2的幂次
transient Node<K,V>[] table;
//map中的键值对集合
transient Set<Map.Entry<K,V>> entrySet;
//map中键值对的数量
transient int size;
//用于统计map修改次数的计数器,用于fail-fast抛出ConcurrentModificationException
transient int modCount;
//大于该阈值,则重新进行扩容,threshold = capacity(table.length) * load factor
int threshold;
//填充因子
final float loadFactor;
重要方法
get
根据key的hashCode计算在数组里的下标,然后再判断该位置是否符合条件,否则根据链表/红黑树的方法继续找
计算下标的方法:
下标 = (n-1) & hash
hash = (h = key.hashCode()) & h>>>16
判断两个key是否相同:
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
先判断hash,如果hash不同一定不同;如果hash相同,则利用equals判断是否相同
put
先检查容量(扩容resize)。
根据hashCode计算桶在数组里的位置,
插入该处的链表/树
resize
两倍容量。如果容量已达最大值,则设置容量为int_max。
扩容之后要重新计算index,每个桶里的节点都要重新计算位置,计算位置的方法是hash & (n-1)。
扩容之后由于newCap-1比oldCap-1多了一个高位(例如8-1=7=111,而4-1=3=11),因此节点的新位置取决于多出来的一个高位bit,如果该位是0,则还是原位置;否则应该是原位置+旧容量
扩容的过程对整个数组和桶进行了遍历,耗费性能,所以最好在创建HashMap的时候指定容量,否则在第一次put的时候会进行一次扩容(因为table==null)
HashMap与HashTable的区别
- 线程安全性:Hash Table线程安全,HashMap线程不安全
- null键值的支持:HashMap最多有一个null键,null值不做约束;HashTable不接受null键值
- 初始容量及扩容:HashTable初始容量11,扩容2n+1;HashMap初始容量16,扩容2n(即容量时钟2的幂)
- 数据结构:jdk8以后HashMap加入了红黑树提高链表过长时的查询速度,HashTable没有