转载请注明出处:
https://www.cnblogs.com/darkknightzh/p/12592291.html
本文仅为本人的一点理解,如有不正确的地方,或者读者已经懂了,则不用浪费时间看本文了O(∩_∩)O
softmax loss定义如下:
$L=-frac{1}{m}sumlimits_{i=1}^{m}{log left( frac{{{e}^{W_{yi}^{T}{{x}_{i}}+{{b}_{yi}}}}}{sumlimits_{j=1}^{n}{{{e}^{W_{j}^{T}{{x}_{i}}+{{b}_{j}}}}}} ight)}$
其中$W$为分类层的权重,$x$为分类层的输入特征,$b$为分类层的偏置。
上式$frac{{{e}^{W_{yi}^{T}{{x}_{i}}+{{b}_{yi}}}}}{sumlimits_{j=1}^{n}{{{e}^{W_{j}^{T}{{x}_{i}}+{{b}_{j}}}}}}$为softmax,即当前样本分为第i类的概率。
论文中当分类层为2个类别时,可视化后的特征(即上面公式中的)如下,均为径向放射状分布(图片来自center loss的论文)。

特征径向放射状分布,原因如下图所示。假设${{w}_{1}}$和${{w}_{2}}$为分类层两个类别的权重向量。$x$为某个特征(图中对应${{x}_{1}}$和${{x}_{2}}$,指代优化前后的特征),且假定该特征对应类别为${{w}_{1}}$。由softmax loss的公式可见,若使得loss更小,需要当前样本正确分类的概率$frac{{{e}^{W_{yi}^{T}{{x}_{i}}+{{b}_{yi}}}}}{sumlimits_{j=1}^{n}{{{e}^{W_{j}^{T}{{x}_{i}}+{{b}_{j}}}}}}$更大,进一步需要${{e}^{W_{yi}^{T}{{x}_{i}}+{{b}_{yi}}}}$更大(或者说${{e}^{W_{yi}^{T}{{x}_{i}}+{{b}_{yi}}}}$增长的比${{e}^{W_{j}^{T}{{x}_{i}}+{{b}_{j}}}}|j e {{y}_{i}}$增长的更大)。
在忽略偏置$b$的情况下,由于$Wx ext{=}left| W ight|left| x ight|cos ( heta )$,即$W$模长和$x$模长和$W$及$x$的夹角的乘积。若假定$left| W ight|$不变,则有两种方式:
① 增大$left| x ight|$,导致特征模长越来越大。
② 增大$cos ( heta )$,即降低$W$及$x$的夹角$ heta $,因而导致$x$在$W$方向上径向分布。
综合起来,特征便呈现径向放射状分布。
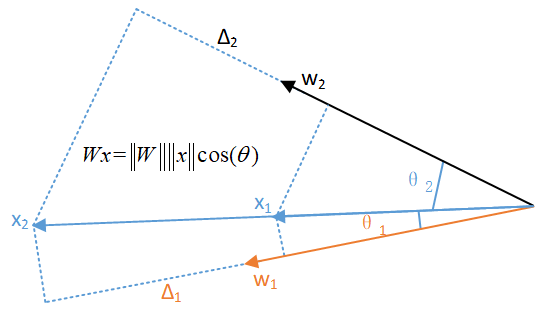
下面举一个简单的例子。假设${{x}_{1}}$在${{w}_{1}}$和${{w}_{2}}$上投影是0.4,0.3,${{x}_{2}}$投影是0.8,0.6,由于cos作为权重,导致最终在${{w}_{1}}$上增加的幅度大于在${{w}_{2}}$上增加的幅度,样本被分为第一类的概率增大(loss减小),因而下一时刻(即${{x}_{2}}$)会越来越呈现放射状(离原点越来越远,对应分类概率越来越大);另一方面,还需要分类正确,即$x$到${{w}_{1}}$的夹角${{ heta }_{1}}$小于$x$到${{w}_{2}}$的夹角${{ heta }_{2}}$,因而最终特征会沿着对应$W$的方向径向分布;综合起来,特征会呈现径向放射状分布。