2020-03-23 13:48:52 更新:
最近看到部分文章阅读量竟然变高了,有点惶恐,希望自己不会误人子弟。这篇文章是非常浅显的 http 协议的一小部分,如果要全面了解 http / 1.1 协议,请移步:RFC 7231
它是http 1.1 标准规范档案,里面讲述十分详细。(我记得火狐开发者社区也有)
比如 http1.1 Accept-Encoding 字段中描述了如何压缩 body 进行传输,这点很重要,我最初自己写http客户端的时候还不知道,于是从服务器获得的 html 内容都是乱码,其实这是因为服务端将 body 部分使用 br 、gzip、deflate 等方法进行了编码。并且对其压缩算法也有较详细的描述,简单来说都是基于哈夫曼树的改进和优化(详见 RFC 1951 DEFLATE、RFC 1951 GZIP)
对各种响应状态码的解释、缓存控制、Session等。
最后,大家有没有真正的意识到一点呢,其实计算机越学越发现,基本上就是在学习前人与计算机定下的规则呀~,无论哪一个方面(硬件、语言、算法、软件、图片等),然后终将有一天,我们也开始制定一些规则,让别人参与进来。所以对各种协议、文档存储格式等有一定深入了解是非常重要的一件事。
以下为原文:
先推荐一篇很不错的文章:https://imququ.com/post/four-ways-to-post-data-in-http.html
说一下,如果是自己编写底层,那么要注意了,不能只有提交数据的类型,还必须要有数据内容的长度,大体这样写即可:
method << "POST / HTTP1/1 "; headers << "Content-Length: 32 "; headers << "Content-Type: application/x-www-form-urlencoded; charset=UTF-8 "; ... body << "test=1&type=json&time=1513242234";
请求头部分结束的后面就是请求主体(body),发送的body内容是key-value对应的url source,如果带有中文或其他非英文语种,类似这样:
type=1&message=%E5%8A%A9%E6%89%8B&plat=1&jsonp=jsonp
需按url编码格式编码。注意不用在字符串尾部加" "。
实际上这种类型的提交参数实现了通过接口对服务器后台的数据库进行CRUD操作。
我之前仅仅只是会用python的requests库,没怎么了解底层,现在自己用C++写爬虫才知道,人家已经帮我们做好了这些事,十分便利,同时也看到了她的强大之处。
下面用C++测试B站的add接口(发表评论)为例:
#include <iostream>
#include <sstream>
#include "libhttp.hpp"
using http::Request;
using std::string;
using std::stringstream;
int main()
{
Request r;
string url = "https://api.bilibili.com/x/v2/reply/add";
stringstream headers;
headers << "Contention: keep-alive
";
headers << "Content-Length: 102
";
headers << "Content-Type: application/x-www-form-urlencoded; charset=UTF-8
";
headers << "Cookie: xxx
";
headers << "Host: api.bilibili.com
";
headers << "Referer: https://www.bilibili.com/bangumi/play/ep85276
";
headers << "User-agent: xxx
";
string data = "oid=4492528&type=1&message=%E5%8A%A9%E6%89%8B&plat=1&jsonp=jsonp&csrf=14211ebe19f7a1500e3a4d910c9d4b44";
// decode: "oid=4492528&type=1&message=助手&plat=1&jsonp=jsonp&csrf=14211ebe19f7a1500e3a4d910c9d4b44";
r.post(url, "", headers.str(), data, "");
return 0;
}
运行结果:

到B站上看看:

测试成功,这里测试环境是Linux CentOS7。
如果使用python requests模块,可以简单这样写:
# coding=utf8
from requests import request
data = {
'oid': '4492528',
'type': '1',
'message': '正片被tx抢走了',
'plat': '1',
'jsonp': 'jsonp',
'csrf': '141500e3a4d910c9d4b44'
}
headers = {
'Cookie': 'xxx'
}
r = request('post', 'https://api.bilibili.com/x/v2/reply/add', data=data, headers=headers, timeout=1)
print r.status_code
print r.text
她的底层会根据你自定义的headers以及data进行解析,然后补充上一些缺少的重要key-value。
顺便提下之前在该篇中提到的csrf
1.旧csrf + 旧cookie:
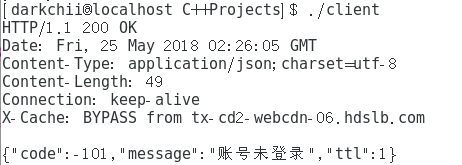
2.新csrf + 旧cookie:
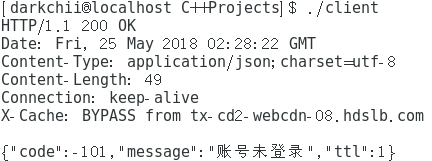
3.旧csrf + 新cookie:
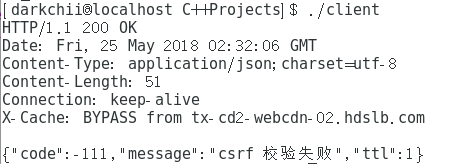
# 2018-12-15 12:02:22 咳咳,今天回头看了一下这篇文章。。。はつかし。。。emmm,发现自己真是个文盲。。。基本上各大网站的csrf和cookie都是有生命周期的。。。一些网站做得更严谨,可能关闭掉网页就死了,但一般都是通过session来持续一段生命周期,并且csrf是一种名为Cross-site request forgery(跨站请求伪造)的技术,嘛,做过网站应该就明白了。所以,我重新登录,之前的csrf以及cookie当然会失效。。。
...然后B站的csrf怎么获得呢?不可能每次都发表评论 + F12看吧,这也太事后诸葛亮了,所以找找还有没有其他方法,当然我也是无意间找到一个办法,当视频播放时,有个接口会每隔几秒钟发送一次请求,其中也带有该视频下通用的csrf,这个接口名为:heartbeat,如图:
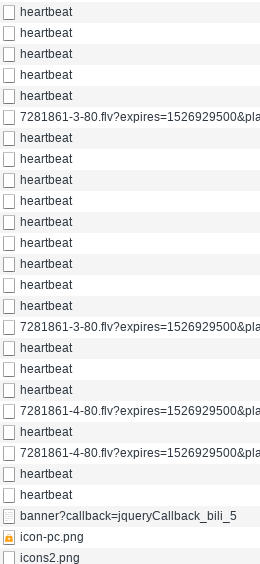
点一下她,在Headers中From Data就可以看见了。
ps:今天才知道如何查看网站的robots.txt,在浏览器地址栏中输入是格式:http://网站主页/robots.txt,比如B站的:https://www.bilibili.com/robots.txt,上面写清楚了网站中哪些是不允许爬取的。
参考:
1.https://www.zhihu.com/question/34980963
2.http://www.robotstxt.org/robotstxt.html