前几天查了一些与独热编码相关的资料后,发现看不进去...看不太懂,今天又查了一下,然后写了写代码,通过自己写例子加上别人的解释后,从结果上观察,明白了sklearn中独热编码做了什么事。
下面举个例子解释一下:
code:
from sklearn.preprocessing import OneHotEncoder
import numpy as np
train = np.array([
[0, 1, 2],
[1, 1, 0],
[2, 0, 1],
[3, 1, 1]
])
one_hot = OneHotEncoder()
one_hot.fit(train)
print(one_hot.transform([[1, 0, 1]]).toarray())
Output:
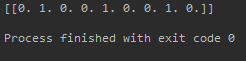
这里的output输出的是什么?怎么与例子中的矩阵关系起来?例子给的是一组4行3列的矩阵,从列来看它的特点是第1列4个数都不同,第2列只有二进制数(0,1),第3列有3个不同的数。
这样的数值矩阵对应的文本类表单可以是这样的:
| 姓名 | 性别 | 成绩 |
| 鸣人:0 | 男:1 | 32:2 |
| 佐助:1 | 男:1 | 99:0 |
| 小樱:2 | 女:0 | 87:1 |
| 佐井:3 | 男:1 | 87:1 |
于是
one_hot.transform([[1, 0, 1]]).toarray()
编码的结果这样理解:
第1列:矩阵第一列有4个不同的数,用4位表示,1出现在[0,1,2,3]中的下标为1的位置上,所以对应的独热码为:[0,1,0,0]。
第2列:矩阵第二列有2个不同的数,用2位表示,0出现在[0,1]中的下标为0的位置上,所以对应的独热码为:[1,0]。
第3列:矩阵第三列有3个不同的数,用3位表示,1出现在[0,1,2]的下标为1的位置上,所以对应的独热码为:[0,1,0]。
可以用例子证明上面的结论:
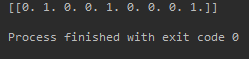
Input:[[1,0,2]]
Output:
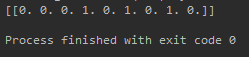
Input:[[3,1,1]
Output:
假如要进行编码的数据没有出现在对应列中将会出现错误:
Input:[[4,1,1]]
Output:

等等,还可以自行写其他例子验证一下。
现在我们就知道了独热编码做了什么了,它先统计每列中每个数据出现的次数并去除重复的,然后在没有重复数据的数据集上对不同列的数据进行相应的编码。按这样的规则编码的结果就可以只有0,1出现了。
参考资料:
1.https://blog.csdn.net/google19890102/article/details/44039761
2.https://blog.csdn.net/pipisorry/article/details/61193868
3.https://blog.csdn.net/counsellor/article/details/60145426