本文是根据Coursera上吴恩达老师深度学习视频整理而成的笔记,包含课程所有精华内容,对深度学习感兴趣的同学还是推荐看看吴恩达老师的课程视频,讲解深入浅出,很适合作为入门教材,课程视频请在coursera官网或者网易云课堂观看。
一、误差分析
- 在开发验证集合(dev set,有时也叫交叉验证集)上找100个被错误分类的图片
- 数一数有多少张图片是把狗错误分类成猫的
- 修改那些把狗当成猫的照片
- 修改把大型猫科动物(狮子、豹子)当成猫的照片
- 提升模糊图像的性能
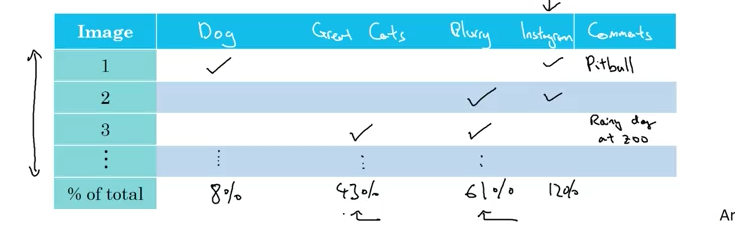
我们可以列张表格,把所有错误图像被误分类的原因标注出来,对错误进行简单的分类,这样一来我们很容易看见哪类错误是导致误分类率高的主要原因,也更容易确定自己的工作方向——把精力投在最有提升潜力的部分(比如图中的模糊因素)
二、清除标注错误的数据对于标注错误的数据该如何处理呢?
深度学习算法对随机误差鲁棒性很强,随机误差可以不用管,只要总数据及足够大。但时对系统误差(比如做标记的人一直把如例子中的白色的狗标记成猫)则最后的结果会出错。

在之前那个表格中添加一列,用来记录错误的标签,通过计算整体错误中因为标签错误而导致的错误比例,我们可以判断是否需要纠正错误的标签

修正开发、测试集上错误样例:
- 对开发集和测试集上的数据进行检查,确保他们来自于相同的分布。使得我们以开发集为目标方向,更正确地将算法应用到测试集上。
- 考虑算法分类错误的样本的同时也去考虑算法分类正确的样本。(通常难度比较大,很少这么做)
- 训练集和开发/测试集来自不同的分布(这通常是一件比较合理的事情)
三、快速搭建你的第一个系统并进行迭代

如果你要搭建一个语音系统,可能遇到图中所示的问题,你可以用之前的方法分析清楚导致错误的各个因素以及所占比重,从而决定下一步行动方向。吴恩达的建议很简答,最快搭建系统,然后再迭代。系统既不能太简单,也不能太复杂,同时你的经验以及同行们已经发表的论文都是很好的 借鉴。

四、不同分布上的训练和测试
我们可以从网上获取大量的高清晰的猫的图片去做分类,如200000张,但是只能获取少量利用手机拍摄的不清晰的图片,如10000张。但是我们系统的目的是应用到手机上做分类
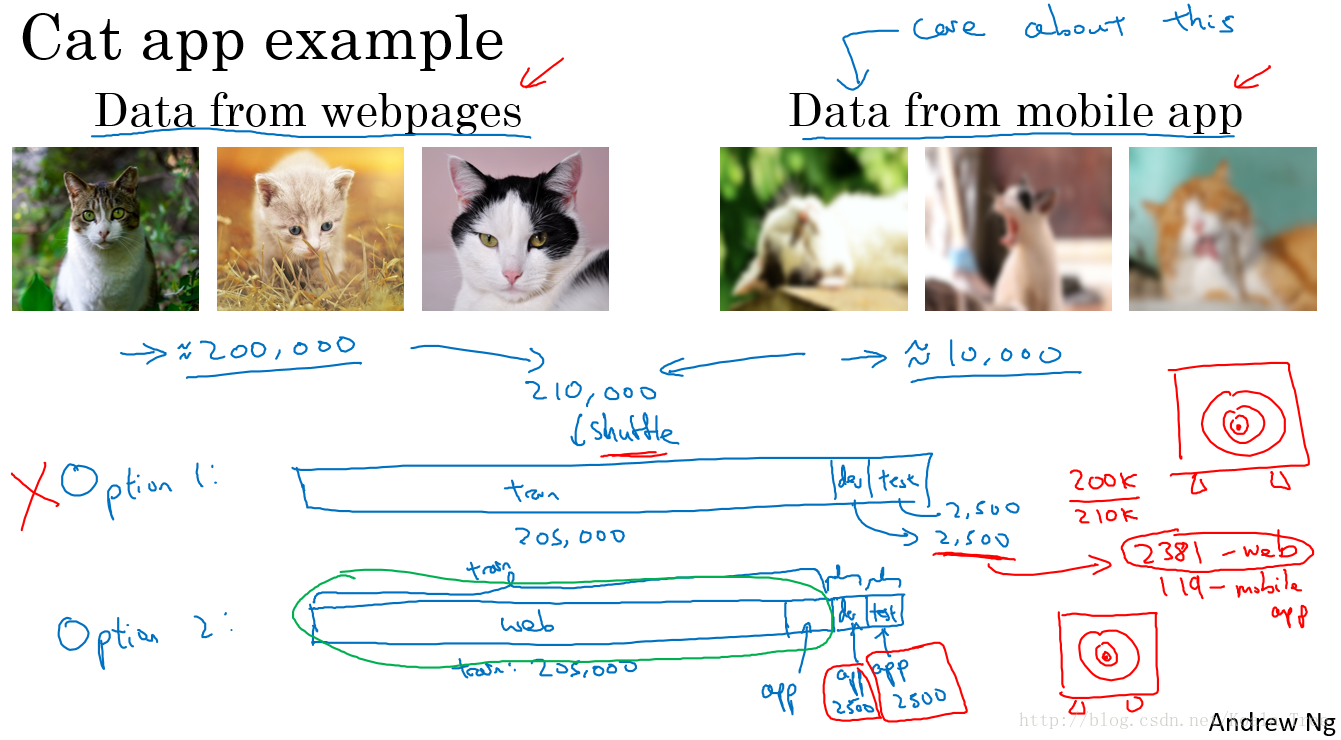
当训练集和测试集数据分布不一样怎么办呢?两种方法
1、将两部分的数据合在一起,然后重新分配训练集、验证集、测试集,这么做的优缺点如下:
- 优点:三个集合分布相同
- 缺点:手机拍着的猫的图片展验证集的比例太小,使得我们更多关注了非来自用户手机的图片,后期的优化方向也会有偏离,我们设立开发集的目的是瞄准目标,而现在我们的目标绝大部分是为了去优化网上获取的高清晰度的照片,而不是我们真正的目标。
所以不推荐这种方法
2、来自网络的大多数图片作为训练集,来自手手机的图片作为测试集和验证集,这么做的优缺点如下:
优点:开发集全部来自客户拍摄的图片,瞄准目标,(目标集中在优化客户的需求)
缺点:训练集和验证集分布不一样