课程视频地址:https://www.coursera.org/learn/machine-learning/lecture/1VkCb/supervised-learning
Supervised Learning 监督学习
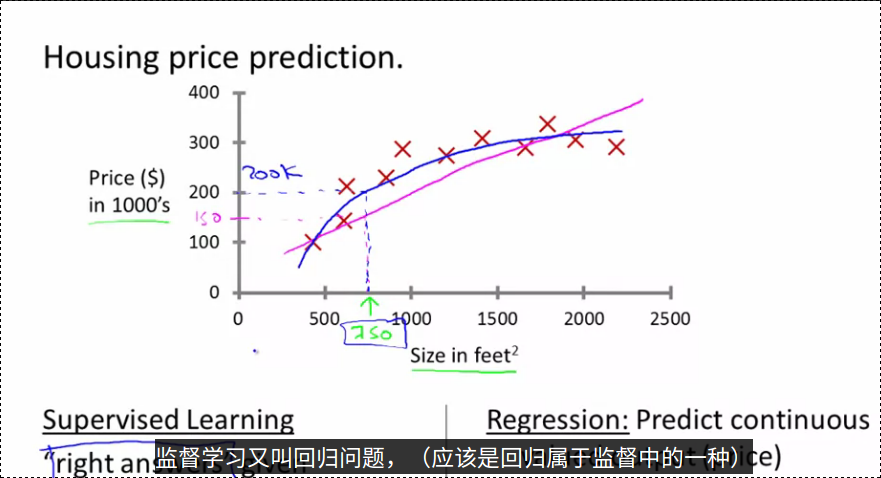
监督学习:给出一个算法,需要部分数据集已经有正确答案。比如给出给定房价数据集,对于里面每个数据,算法都能计算出对应的正确房价。算法的结果就是短处更多的正确价格。
像房价预测问题这样的监督学习又叫回归学习(一般是监督学习的一种)。
Supervised Learning:“right and answers given”
监督学习:给出训练集
Regression Learning:Predict continuous valued output(eg:price)
回归学习:预测输出是连续值,比如说价格。
Classification: Discrete value output ( 0 or 1 )
分类问题: 离散值输出,有时可以不止两个特征,甚至无穷个特征。
课堂训练(如图):

答案是C。
Unsupervised Learning 无监督学习
在无监督学习中,我们用到的数据和监督学习中的不一样。在无监督学习中,没有属性或者说标签的概念,只有一个数据集。
对于给定的数据集,无监督学习算法通过数据中存在的内在结构可能判定,该数据集包含几个不同的聚类,然后把数据分到这几个聚类中。这就是聚类算法(clustering algorithm)。聚类算法的实际用例有谷歌新闻每天搜索成千上万条新闻,然后把同一个事件的新闻报道聚集在一起。
历史上,由于聚类问题和无监督学习关联更紧密,所以时常将两者概念混在一起。但事实上,无监督学习还有另一种算法——关联规则挖掘。实例如鸡尾酒宴问题。关联规则挖掘也是无监督学习。
