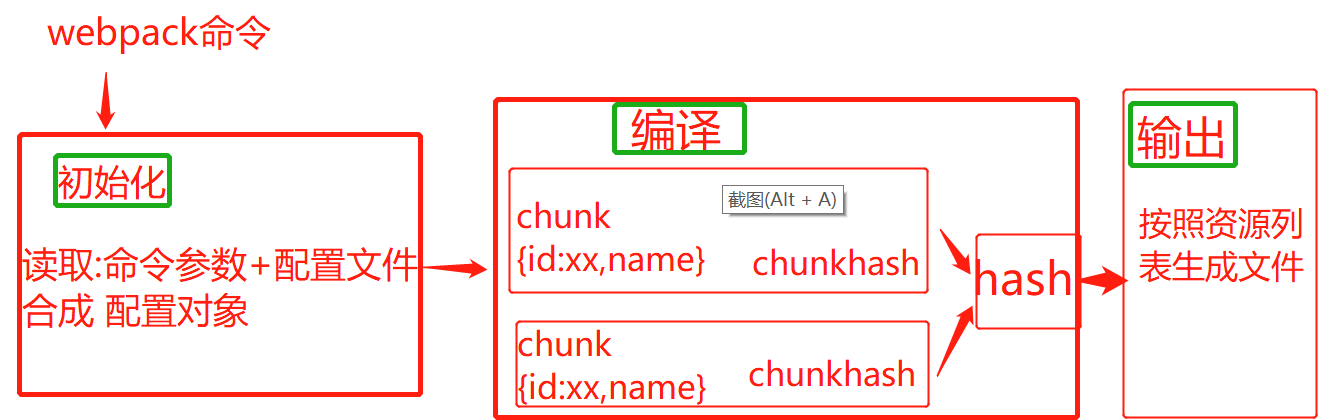
一: webpack编译过程分为初始化, 编译和输出三个阶段.
二: 初始化: 整理配置, 形成最终配置对象
1.命令行中的配置参数的权重最高, 因为最晚确定的. 命令中配置参数用: --xx=yy表示
比如 npx webpack --mode=development --devtool=eval-source-map,
2. 读取配置文件中的配置: 默认是webpack.config.js, 也可以通过命令行去指定 --config=myconfig.js
3, 默认配置
将三项合并, 最终形成配置对象, 按照配置对象打包;
三. 编译过程
1. 生成chunk. 每一入口文件到他所有的依赖文件,都会生成的一个代码块.这就是chunk

每个chunk都有name 和id
name: 默认是main所以我们打包后的代码,如果没配置output的filename属性, 都是main.js
id: 开发环境中与name相同, 生成环境中是一个数字, 从0开始;
过程:
(一) 生成模块记录
如下所示: 目的是记录所有模块
{ ./src/js/argset.js": ` const GENERATE_TIME = 100; const WAITTIME = 100; const DISPEAR_TIME = 100; `, ...//还有很多模块, 1.记录了所有模块(路径作为属性, 模块内容字符串化后作为值), 2 模块的导入函数做了特殊处理. }
1. chunk中会创建一个模块记录: 属性值是模块id, 即模块路径; 值是转换后的代码内容, 初始化时该记录内容为空;
2. 从入口模块开始, 分析依赖, 看在模块记录中是否有属性,有则结束, 没有则读取文件内容,
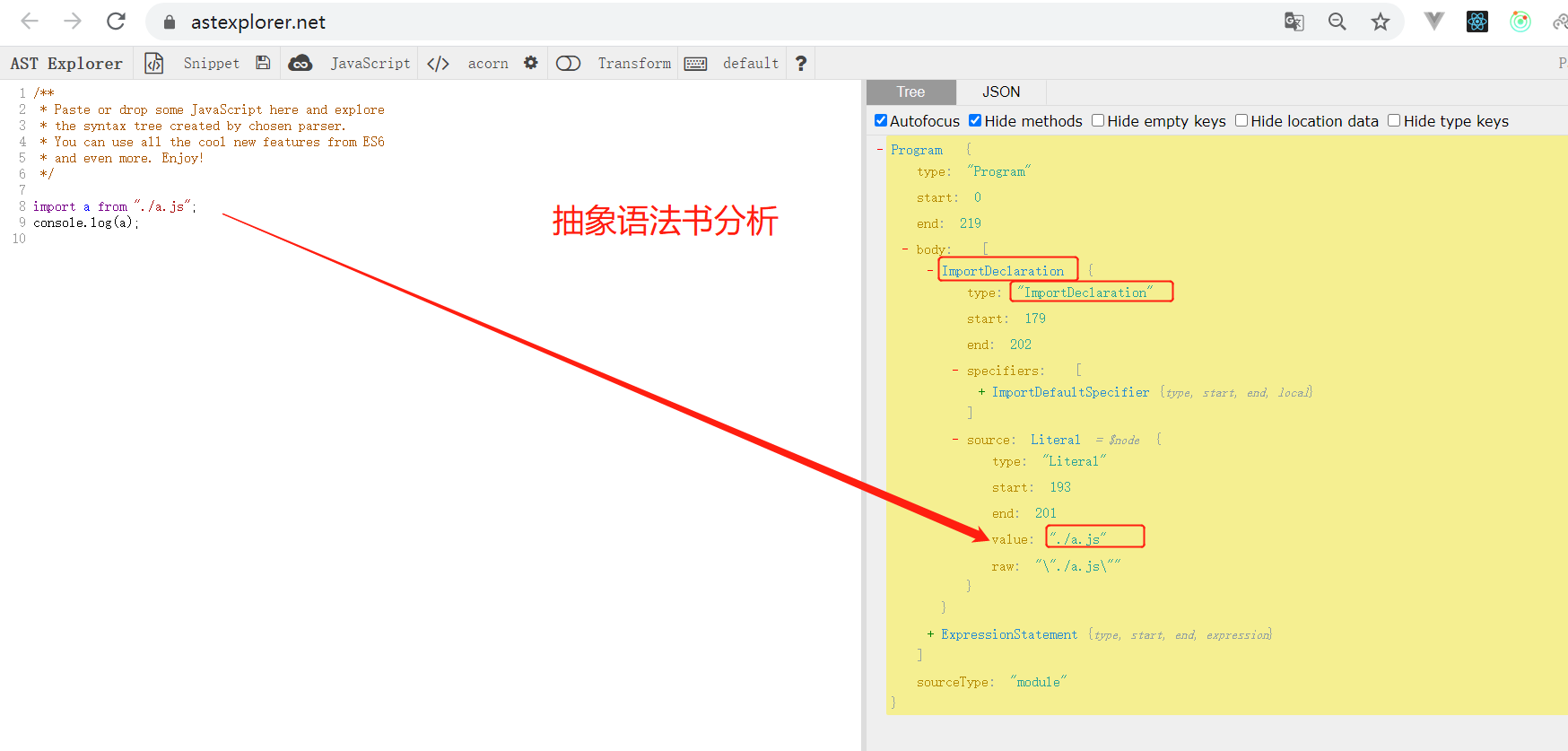
3.对文件内容进行AST抽象语法树分析:
目的是找出依赖: 对于其中的es6引入和commonjs规范的引入, 进行语法分析,找出路径. 这webpack需要用到第三方模块来专门的分析.
这也是为什么会支持es6和commonjs导入的原因;通过ast在线分析可以看到他们的结构
4. 将依赖保存到的dependencies数组里
5. 将读取文件字符串, 替换依赖函数, 比如import xx from "xx"换成 __webpack_require("xx"); require("xx")改成require("./src/xx")
6, 保存转换后的字符串到模块记录中.
7, 按照dependencies数组分析下一个依赖.
8. 递归按照depedencies数组依赖, 分析模块依赖, 并把未记录的模块记录到模块记录中.
最终形成 模块列表,来记录所有模块: 模块id: 模块代码 ,模块id: 模块代码 .....
(二) 生成资源列表: 每个chunk生成一个资源列表, 即chunk access;
根据资源列表生成hash文件
(三) 合成资源列表:将各个chunk生成的资源合成, 形成总的资源列表, 比如./dist/main.js.map和./dist/main.js ;
三. 输出(emit): 根据合成资源列表, nodejs会生成输出文件.
------------恢复内容结束------------