Shell脚本学习指南
作者:Danbo 2015-8-3
脚本编程语言与编译型语言的差异
许多中型、大型的程序都是用编译型语言写的,例如:C、C+、Java等。这类程序只要从源代码(Source Code)转换成目标代码(object code),便能直接通过计算机来执行。
编译型语言的好处是高效,缺点是:他们多半运作于底层,所处理的是字节、整数、浮点数或是其他机器层级的对象。而脚本语言Shell通常是解析型(interpreted)的。这类程序的执行,是由解析器(interpreter)读入程序代码,并将其转换成内部的形式。解析器本身是一般的编译型程序。
查找文本
以grep程序查找文本,传统上有三种程序:
1.grep:使用基本正则表达式(Basic Regular Expression,BRE)
2.egrep:扩展grep使用扩展正则表达式(Extended Regular Expression),不过会消耗更多的资源。
3.fgrep:快速grep匹配固定字符串而非正则表达式,grep与egrep只能匹配单个正则表达式,而fgrep使用不同的算法,却能匹配多个字符串。
简单的grep
grep -F danbo,-F选项,以查找固定字符串danbo。事实上,只要匹配的模式里面未包含正则表达式的meta字符表达式的meta字符,grep默认行为模式就等于使用了-F。
grep的语法格式:
-E 使用扩展正则表达式进行匹配。grep -E等同于egrep。
-F 使用固定字符串进行匹配。grep -F可取代传统的。
-i 模式匹配时忽略字母大小写差异。
-q 静默地。不输出结果,echo $? 返回0成功,返回1没有找到匹配的内容。
-v 显示不匹配模式的行。
-c 计算找到搜索字符串的次数。
-n 输出含有搜索字符串所在行的行号。
正则表达式
正则表达式是一种表示方式,让你可以查找匹配特定准则的文本。
常用到的字符及其意义:
逃脱字符,关闭后续字符的特殊意义。有时则具有特殊意义:{...}
. 匹配任意单个字符,但是nul除外。
* 匹配之前的任意的单个字符。当位于第一个字符时,无意义。
^ 匹配在行或字符串的起始处。BRE:仅在正则表达式的开头出具有意义。EBR:置于任何位置都具有特殊含义。
$ 匹配前面的正则表达式,在字符串或行尾。BRE:仅在正则表达式结尾处具特殊含义。ERE:置于任何位置都具有特殊含义。
[...] 方括号表达式,匹配方括号内的任意字符。连接符“-”指的是连续字符的范围。“^”置于第一个位置取反。
{n,m} 区间表达式,匹配在它前面的单个字符重现的次数,{n}指的是重新n次;{n,}重新n次及以上;{n,m}指的是前面单个字符重新n至m次。
( ) 将“(”与“)”的模式存储在特殊的“保留空间”。最多可以将9个独立的子模式(sbupattern)存储在单个模式中。可以通过1至9,被重复使用在相同模式里。例如(ab).*1指的是匹配ab组合的两次重新,中间可以存在任意数目的字符。例如可以匹配:ab..........ab。另一个例如:(ab)(cd).*21则是匹配:abcd........cdab注意后面的
表示匹配前面第几个小括号。
+ 匹配前面正则表达式的一个或多个实例。
? 匹配前面正则表示式的零个或一个实例。
| 匹配|左右的正则表达式。
( ) 匹配括号括起来的正则表达式。
POSIX字符集
扩展正则表达式
我们比较一下BRE与ERE的区别,主要体现在以下几点:
BRE只定义了4组元字符:
[] 用于在多个字符中选定一个字符进行匹配,[]内可以有-以示范围,但-本身不是元字符
. 用于匹配任意字符
^ 用于匹配时表示“非”的含义,还有一个用法是匹配行首
$ 用于匹配行尾
ERE在此基础上增加了3组元字符的定义:
{} 用于表示重复匹配的次数。BRE中只将{}当作普通字符对待,要使用此功能必须加进行转义,即“{}”
() 用于分组。BRE中只将()当作普通字符对待,要使用此功能必须加进行转义,即“()” 比如:(why)+匹配一个或多个why
| 完全为ERE新增的多项匹配能力定义的,BRE无多项匹配能力,只将|作普通字符对待。比如:(read|write)+表示一个或多个read或者一个或多个write。
注意|为所有运算中优先级最低的,^abcd|efgh$意思是“匹配字符串的其实处是否有a、b、c、d,或者结尾处是否有e、f、g、h”,这个和^(abcd|efgh)$不一样,后者表示“以abcd开头或者以efgh结尾”
ERE运算符的优先级
扩展:“”<与“>”分别匹配word的开头语结尾,其中word是由字母、数字、下划线组成的。我们称这类字符为单词组成(word-constituent)。例如:<chop匹配chopsticks,却不匹配lambchop。
额外的GUN正则表达式运算符
在文本里进行替换
sed基本用法:
-e 当有多个命令需要应用时,就必须使用-e了。
-f script-file 读取脚本文件中的sed命令。
-n 安静模式,仅显示经过sed名利处理的行。通常与p一起使用。
/字符扮演定界符(delimiter)的角色,用于分割正则表达式与替换文本,任何可现现实的字符都能作为定界符。标点符号也是可以的(比如:分号、冒号、逗号)。
例如:echo /home/tolstoy/ | sed 's;(/home)/tolstory/;1/lt/;'
注意:1表示匹配前面()之间的内容,且向后引用最多可以用到9个,这点前面已经讲过了。
sed 's/Tolstory/Camus/g' < example.txt #g表示全局性(Global)。另一个结尾指定数字,指示第n个匹配出现才去取代。
例如:sed -e 's/foo/bar/g' -e 's/chicken/cow/g' < example.txt
不过,如果有很多要编辑的话,我们就需要将编辑命令全部放入脚本文件中,再使用sed搭配-f选项:
cat fixup.sh
s/foo/bar/g
s/chicken/cow/g
...
sed -f fixup.sh example1.xml > example2.xml
上面意思为读取fixup.sh内的编辑命令,然后修改example1.xml的内容,修改后结果保存在example2.xml文件中。
sed的运作原理
sed读入每个文件,一次读入一行,将读取的行放入内存的一个区域---称之为模式空间(pattern space)。类似变量:内存的一个区域在编辑命令的指示下可以改变,所有编辑上的操作都会应用到模式空间的内容。当所有操作完成后,sed会将模式空间的最后内容打印到标准输出,再回到开始处,读取另外一个输入行。
sed匹配特定行
我们可以限制一条命令应用到哪些行,只要在命令前置一个地址(address)即可。
例如:sed '/named/ s/nologin/fuck/g' </etc/passwd
先定为含有named的行,然后在该行中进行替换。
范围:
指定行的范围:sed -n '10,21p' /etc/passwd #打印10-21行。
指定替换范围:sed '/foo/,/bar/ s/baz/quux/g' /etc/passwd #从含有foo的行开始匹配到bar的行,再进行替换。
否定正则表达式:
sed '/used/!s/new/used/g' #将没有used的每一行里所有的new改为used。
行 v.s. 字符串
大部分简易程序都是处理输入的数据的行,想grep与egrep,以及sed。在这些情况下,不会有内嵌的换行字符出现在将要匹配的数据中,^与$分别表示行的开头与结尾。
然而对于awk、Perl、Python,所处理的就多半是字符串。不过这类都会让你标明每条输入记录的定界符,所以有可能单独的输入行里会有内嵌的换行符,这种情况下,^与$是无法匹配内嵌的换行字符的。
记录和字段
一条记录(record)指的是相关信息的单个集合;字段(filed)指的是记录的组成一部分。
/etc/passwd每条记录中的每个字段的含义如下:
root:x:0:0:root:/root:/bin/bash
使用cut选定字段
cut命令是用来剪下文本文件里的数据,文本文件可以是字段类型或是字符类型
例如:cut -d : -t 1,5 /etc/passwd #范围1,5也可以使用1-5
-c 以字符为参考
-d 指定定界符,默认是制表字符(Tab)
-f filed指定第几个字段。
使用join连接字段
join命令可以将多个文件结合在一起,每个文件里的每条记录,都共享一个键值(key),键值值得是记录中的主字段,通常会是用户名称、个人姓氏、员工编号之类的数据。
语法:join [options...] file1 file2
-1 field1
-2 field2
标明要结合的字段。-1 field1指的是从file1取出field1,而-2指的是从file2中取出field2。
-o file.field
输出file文件中的field字段。一般的字段则不打印。除非使用多个-o选项,即可显示多个输出字段。
-t separator
使用separator作为输入字段分割字符,而非使用空白。
使用awk重新编排字段
awk设计的重点就是在字段与记录上:awk读入输入记录(通常是一些行),然后自动将各个记录切分为字段。awk将每条记录内的字段数据,存储到内建变量NF。
默认以空白分割字段---例如空格与制表符字段(或两者混用),你可以将FS变量设置为一个不同的值。
如需字段值,则是搭配$字符。通常$之后会接着一个数值常数,也可能是接着一个表达式,不过多半是使用变量名称。例如:
awk '{print $1,$NF}' #打印第1个与最后一个字段
awk 'NF > 0 {print $0}' #打印非空行 等同于:grep -v "^$"
设置字段分割字符
例如:awk -F: '{print $1,$5}' /etc/passwd
-F选项会自动地设置FS变量。请注意,程序不必直接参照FS变量。awk的输入、输出分割字符用法是分开的,这点与其他工具程序不同。也就是说,必须设置OFS变量,改变出字段分割字符。方式是在命令行里使用-v选项。例如:
[root@localhost uestc]# awk -F: -v 'OFS=**' '{print $1,$NF}' ./passwd
root**/bin/bash
打印行
[root@localhost uestc]# awk -F: '{print "User", $1, "is really", $NF}' /etc/passwd
User root is really /bin/bash
简单明了的print语句,如果没有任何参数,则等同于print $0,即显示整条记录。
当我们使用printf语句时,用法如下:
[root@localhost /]# awk -F: '{printf "User %s is really %s
",$1,$NF}' /etc/passwd
User root is really /bin/bash
awk的print语句会自动提供最后的换行字符,然后,如果使用printf语句,则用户必须要通过
转义序列的使用自己提供。
请记住:在print的参数间用都好隔开!,否则,awk将连接相邻的所有值。
起始于清除
BEGIN与END这两个特殊的“模式”,它们提供awk程序起始(startup)与清楚(cleanup)操作。
BEGIN与END的语句块是可选用的。如需设置,习惯上它们应分别位于awk程序的开头与结尾处。你可以有数个BEGIN与END语句块,awk会按照它们出现在程序的顺序来执行:所有的BEGIN语句块都应该放在起始处,所有END语句块也应该放在结尾。例如:
[root@localhost /]# awk 'BEGIN {FS=":" ; OFS="**"} {print $1,$NF}' /etc/passwd
root**/bin/bash
排序文本
未提供命令行选项时,整个记录都会根据当前locale所定义的次序排序。在传统的的C locale中,也就是ASCII顺序。这里我们介绍一个排序命令:sort
sort [options] [files]
-b 忽略开头的空白。
-c 检查输入是否已正确地排序。如果未经过排序,退出码(exit code)非零值,不会有任何输出。
-d 字典顺序,仅处理英文字母、数字、空格。
-f 忽略英文字母的大小写。
-i 忽略无法打印的字符,即只识别
-k 指定排序的键值,即按照哪个域进行排序。
-n 以整数类型排序。
-o outfile 将输出写到指定的文件,而非标准输出。
-r 倒置排序(descending),默认是由小到大(ascending)。
-t 指定分割符,默认空格
-u uniq即丢弃所有相同键值的记录,即删掉重复行。
例如:如果你想把结果输入到输入文件中,则不同能重定向了,此时我们需要使用-o
例如:sort -r number.txt -o number.txt
例如:sort -t ":" -k 2 /etc/passwd
使用点号字符位置,则比较的开始(一对数字的第一个)或结束(一对数字的第二个)在该字符位置处:
-k2.4,-k5.6指的是从第二个字段的第四个字符开始比较,一直比到第五个字段的第六个字符。
例如:sort -t ":" -k 3.1 /etc/passwd
例如:sort -t ":" -k3n -k4n /etc/passwd #按照第一个key值排序,然后再按照第二个key值排序。
sort的稳定性
稳定性(Stable)指的是:相同的记录输入顺序是否在输出时时也可保持原状,这点sort并不稳定,不过我们可以通过--stable选项来使其变得稳定。
删除重复
有时,将数据流里连续重复的记录删除是很有必要的,前面我们介绍了sort -u的用法,不过它的消除操作是依据匹配的键值,而非匹配的记录我们则使用uniq。
-c 可在每个输出行之前加上改行重复的次数。
-d 仅显示重复的行。
-u 仅显示未重复的行。
默认情况下不带任何选项:显示唯一的、排序后的记录,重复则仅取唯一行。
重新格式化段落
fmt通过将所有非空白行的长度设置为几乎相同,来进行简单的文本格式化。
-s 仅仅切割较长的行,但不会将短行结合成长行。
-w n 则设置输出行宽度为n个字符(默认通常为75个)。
例如:fmt -s -w 10 << END_OF_DATA
[root@localhost ~]# fmt -s -w 10 << END
> Welcome to UESTC
> Ali
> Taobao
> Baidu Group
> END
Welcome
to UESTC
Ali
Taobao
Baidu
Group
计算行数、字数以及字符数
wc -c 计算字节数(bytes)
wc -l 计算行数
wc -w 计算字数
wc -m 计算字符数(character)
注意:wc在处理的时候,一定要在文件末尾存在换行符,否则统计行数是不正确的:
[root@localhost ~]# echo "UESTC" | wc -l
1
[root@localhost ~]# echo -n "UESTC" | wc -l
0
提出开头或结尾数行
显示前n条记录:
head -n n
head -n
awk 'FNR<=n'
sed -e nq
sed nq
观察动态观察结尾:tail -n 10 -f /var/log/messages
几个值得加入工具箱的命令
dd 可以以用户指定的块大小与数量拷贝数据,可以进行大小写转换,以及字符转换,备份等。
dd应用实例:
1.将本地的/dev/hdb整盘备份到/dev/hdd
dd if=/dev/hdb of=/dev/hdd
2.备份/dev/hdb全盘数据,并利用gzip工具进行压缩,保存到指定路径
dd if=/dev/hdb | gzip > /root/image.gz
3.将压缩的备份文件恢复到指定盘
gzip -dc /root/image.gz | dd of=/dev/hdb
4.备份磁盘开始的512字节第一扇区文件,即MBR信息到指定文件
dd if/dev/hda of=/root/image count=1 bs=512
count=1指仅拷贝一个块;bs=512指块大小为512个字节。
5.拷贝内存内容到硬盘
dd if=/dev/mem of=/root/mem.bin bs=1024 (指定块大小为1k)
6.增加swap分区文件大小
Step1:创建一个大小为256M的文件
dd if=/dev/zero of=/swapfile bs=1024 count=262144
Step2:把这个文件变成swap文件:
mkswap /swapfile
Step3:启用这个swap文件:
swapon /swapfile
Step4:编辑/etc/fstab文件,使在每次开机使自动加载swap文件:
/swapfile swap swap default 0 0
7.销毁磁盘数据
dd if=/dev/urandom of=/dev/hda1 #注意利用随机的数据填充硬盘,在某些必要的场合可以用来销毁数据
8.测试硬盘的读写速度
dd if=/dev/zero bs=1024 count-1000000 of=/root/1GB.file;
dd if=/root/1GB.file bs=64k | dd of=/dev/null
9.修复硬盘
dd if=/dev/sda of=/dev/sda
file 用于检测文件类型
od 八进制码转存(octal dump)命令,显示ASCII码。此命令主要用来查看保存在二进制文件中的值。
strings 用来查看二进制文件,例如声音、图像文件有时会在开头出包含一些有用的文本数据。
例如:
[root@localhost ~]# strings -a 12.jpg | head -c 256 | fmt -w 65
JFIF rExif Apple iPhone 5s 7.1.1 2014:06:12 23:11:30 0221 0100
2014:06:12 23:11:30 2014:06:12 23:11:30 dApple iOS
tr 它可以非常容易地试下sed许多最基本的功能。它可以用一个字符来替换另一个字符,或者可以完全除去一些字符。同时也可以用它来除去重复字符。
-c 用字符串1中字符集的补集替换此字符集,
-d 从标准输入中删除字符串1中所有字符
-s 删除所有重复出现字符序列,只保留一个。
例如:
[root@localhost ~]# echo Hello,world,root,2015 | tr -c "[0-9]" "*"
*****************2015*
可以看出,我们使用0-9,添加-c选项后,会把0-9替换为其补集,这时补集自然不包含0-9,而包含很多其他的字符,接下来就把其他字符都替换成*号,但不包含数字。
变量与算术
Shell脚本里面经常出现一些简单的算术运算,例如每经过一次循环,变量就会加1,。Shell为内嵌算术提供了一种标记法,称为算术展开(arithmetic expansion)。Shell会对$((...))里面的算术表达式进行计算,再将计算后的结果放回到命令的文本内容。
最常见的命令是export,其用法是将变量放入环境里。环境是一个名称与值的简单列表,可供所有执行中的程序使用。新的进程会从其父进程继承环境。
export命令仅将变量加到环境中,如果你要从程序的环境中删除变量,则要用到env命令,env也可临时改变环境变量的值:
env -i PATH=/usr/bin/local
-i 选项时用来初始化环境变量的,仅传递命令行上指定的变量给程序使用。
unset 命令从执行内中的Shell中删除变量与函数。默认情况下,它会解除变量设置。
-f 删除指定的函数
-v 默认选项,删除指定的变量。
展开运算符
在Shell下,有更复杂的形式可用与更特殊的情况。这些形式都是将变量名括在花括号里${variable},然后再增加额外的语法以告诉Shell该做些什么。
替换运算符:
${varname:-word} 如果varname存在且非null,则返回其值;否则,返回word。
${varname:=word} 如果varname存在且非null,则返回其值;否则,设置它为word,并返回其值。
${varname:?word} 如果varname存在且非null,则返回其值;否则,显示varname:word。
${varname:+word} 如果varname存在且非null,则返回word;否则返回null。为了测试变量的存在。
上述中“:”是可选的,如果没有的话,则将存在且非空改为存在。
模式匹配运算符:
${path#/*/*} 从前匹配最短删除或替换。
${path%/*/*} 从后匹配最短删除或替换。
${#variable} 返回$variable值里的字符长度。
位置参数:
$# 提供传递到Shell脚本或函数的参数总数。
while [ $# != 0 ]
do
case $1 in
...
esac
shift
done
$* & $@ 将所有命令行参数传递给脚本或函数所执行的程序。
$* 将所有命令行参数视为单个字符串。
$@ 将所有命令行参数视为单独的个体。
Shell内置变量


算术展开

“位与”与“逻辑与”的区别:
对于两个整型量,逻辑与只判断两个均不为0,则为True,但是按位与则将两个数转为二进制,对于每个位进行与运算,如果结果不为0,则为True。
退出状态
退出状态及其含义如下图所示:
exit n 目的是从Shell脚本返回一个退出状态给脚本的调用者。
test命令

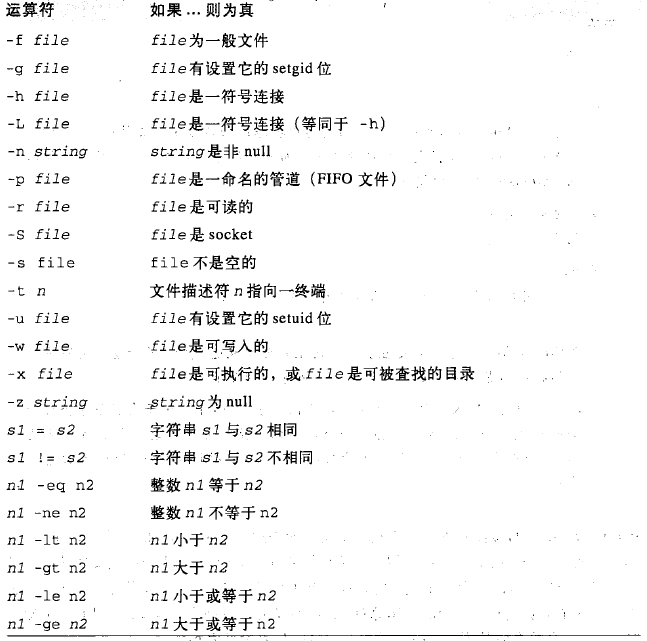
test中-a的优先级高于-o
注意:-a的使用与&&的适用范围不同,"&&"和"||"只能用在[]之间,而-a与-o能用在[]之内。
例如:test -f file && echo true||echo false 等同于 [ -f file ] && echo true|| echo false