1.分布式文件系统理解
使用低配置电脑配置成集群,存储管理单台电脑不能处理的大型文件。
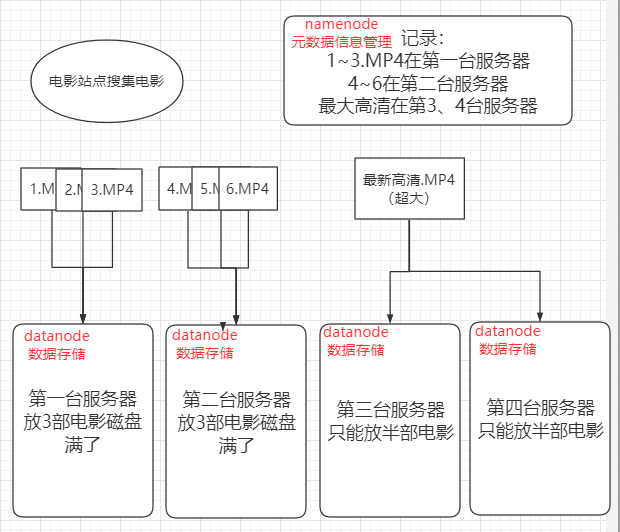
直观理解三个臭皮匠,顶个诸葛亮。
很多磁盘加一起就可以装超多电影。
类似于你出5毛,我出5毛,我们一起凑一块。
2.hdfs优缺点
优点:
a.高容错性:数据自动保存多个副本;通过增加副本的形式,提高容错性。一个副本丢失以后,它可以自动恢复。
b.适合处理大数据:数据规模达到GB、TB甚至PB级数据;能够处理百万规模以上的文件数量,数量相当大;能够处理10k节点规模。
c.可构建在廉价机器上,通过多副本机制,提高可靠性。
d.适合批处理:它是通过移动计算不是移动数据;它会把数据位置暴露给计算框架。
e.流式数据访问:一次写入,多次读取,不能修改,只能追加,能保证数据的一致性。
缺点:
a.不适合低延时数据访问,做不到毫秒级的数据存储;
b.无法高效的对大量小文件进行存储,存储小量文件,会占用NameNode大量内存来存储文件、目录、块信息。小文件存储的寻道时间会超过读取时间,违反了hdfs的设计目标。
c.不支持并发写入:一个文件只能有一个写,不允许多个线程同时写入;仅支持数据追加,不支持文件的随机修改。
3.hdfs的架构详细剖析
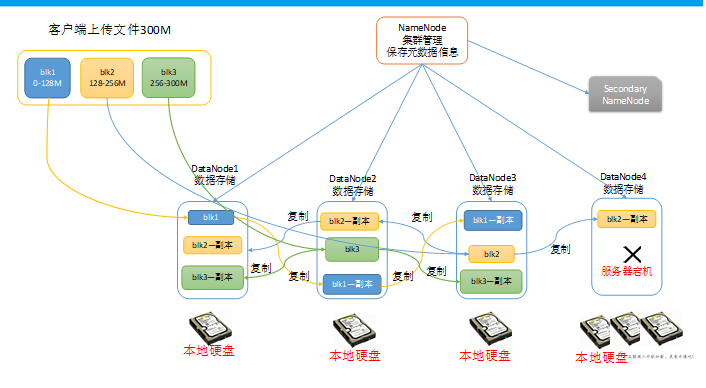
数据以block块的形式统一存储管理,每个块默认最多可存储128M的文件,如果有一个文件大小为1kb,也是要占用一个block块,但是实际磁盘空间还是1kb大小。
每个block块的元数据大小大概为150字节。
a)hdfs集群包括NameNode、DataNode、SecondaryNameNode。
b)NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的的块信息。
c)DataNode负责管理用户的文件数据块,每一个数据块可以在多个datanode上存储多个副本。
d)SecondaryNode用来监控hdfs状态的辅助后台程序,每隔一段时间获取hdfs元数据的快照。最主要作用是辅助NameNode管理元数据信息。
