超越CNN的transformer:VOLO
Transformer技术在CV领域大有"取代"CNN结构的趋势,但是不管是VIT、还是Swin Transformer感觉都差一点火候。这些引入“注意力”的模型在学者的手中,总是告诉我们其很美好,但是在实际的使用过程中,往往性价比远低于CNN结构。但是,即使如此也不能说明Transformer结构的失败,相反,我们可以看见其强大的生命力。最近发表的VOLO模型就是如此,它第一次超越了传统的CNN模型,那么在训练困难度、收敛速度、运算速度上,它能否超越CNN结构呢?
论文:https://arxiv.org/pdf/2106.13112.pdf
项目:https://github.com/sail-sg/volo
0、摘要
多年来,卷积神经网络一直是视觉识别的主流。虽然目前流行的视觉Transformer(ViTs)在ImageNet分类中显示出了基于自注意模型的巨大潜力,但是如果不提供额外的数据,其性能仍然不如最新的SOTA-CNNs。在这项工作中,我们试图缩小性能差距,并证明基于注意力的模型确实能够优于CNNs。我们发现限制ViTs在ImageNet分类中性能的一个主要因素是ViTs在将精细特征编码到 token 表示中的效率低下。为了解决这个问题,我们引入了一个新的 outlook attention,并提出了一个简单而通用的体系结构,称为vision outlooker (VOLO)。与关注粗糙层次上的全局依赖模型的自我注意不同,outlook attention 有效地将更精细层次的特征和上下文编码为 token,这对识别性能非常有利,但在很大程度上被自我注意所忽略。实验表明,我们的VOLO在ImageNet-1K分类上达到了87.1%的top-1分类精度,这是第一个在这个竞争性基准上超过87%的模型,而不需要使用任何额外的训练数据。此外,预训练的VOLO能很好地转移到下游任务,如语义分割 。我们在cityscapes验证集上获得了84.3%的mIoU分数,在ADE20K验证集上获得了54.3%的mIoU分数。
1、介绍
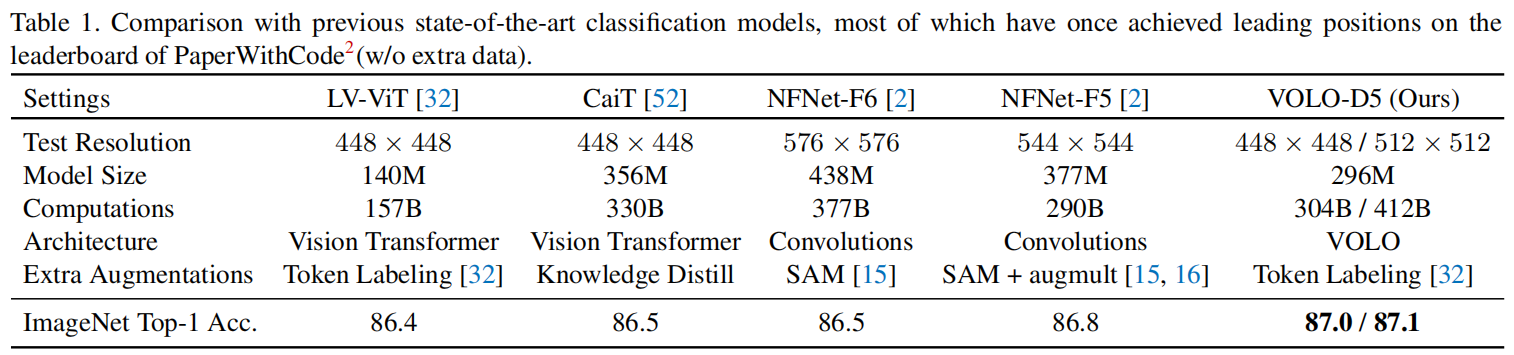
长期以来一直由卷积神经网络(CNNs)主导的视觉识别建模,最近被 Vision Transformers(ViTs)彻底改变了[14,51,68]。与通过局部和密集卷积核聚合和转换特征的cnn不同,ViTs通过在视觉内容建模方面具有更大灵活性的自注意机制,直接对局部补丁(又称token)的长期依赖性进行建模。尽管在视觉识别方面有显著的效果[37,32,52,79],ViT模型的性能仍然落后于最先进的CNN模型。例如,如表1所示,最先进的基于变压器的CaiT[52]在ImageNet上达到86.5%的top-1精度,但是与基于CNN的NFNet-F5[2]与SAM和augmult[15,16]实现的86.8%的top-1精度相比,仍然低0.3%。
在这项工作中,我们试图缩小这种性能差距。我们发现,限制ViTs优于CNNs的一个主要因素是ViTs在将精细特征和上下文编码为token表示方面的低效性,这对于获得令人信服的视觉识别性能至关重要。精细层次的信息可以通过细粒度的图像标记化编码成标记,然而这将导致更长的标记序列,从而二次增加ViTs的自我注意机制的复杂性。
在这项工作中,我们提出了一种新的简单而轻量级的注意机制,称为Outlooker,它可以有效地用精细层次的信息丰富表征。提出的Outlooker方法创新了token聚合的注意力产生方式,使模型能够有效地编码精细层次的信息。特别地,它通过有效的线性投影直接从anchor标记特征中推断聚集周围标记的机制,从而避免了昂贵的点积注意力计算。
基于提出的Outlooker,我们提出了一个简单而强大的视觉识别模型体系结构VOLO。VOLO采用两级体系结构设计,实现了精细的token表示编码和全局信息聚合。具体地,给定大小为224× 224的输入图像,使用自我注意力在粗略的层次上建立全局依赖关系之前(例如,14× 14) ,VOLO将图像标记在较小大小的补丁上(例如,8× 8),并使用多个Outlookers对令牌表示进行精细编码(例如,28× 28). 得到的token表示更具表现力,从而显著提高了模型在图像分类中的性能。
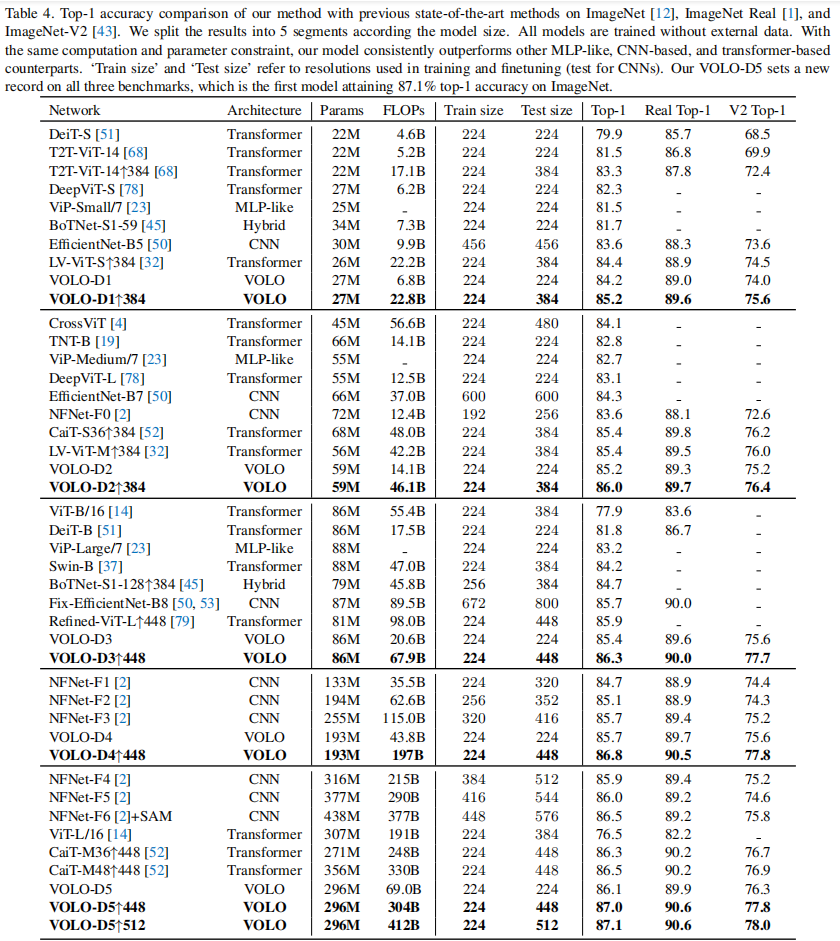
实验表明,本文提出的VOLO算法在图像网分类中具有很好的性能。以一个具有26.6M可学习参数的VOLO模型为例。它在ImageNet上实现了84.2%的top-1精度,而不需要任何额外的数据。在384× 384的输入分辨率上微调此模型可进一步提高精度至85.2%。此外,当将模型尺寸扩大到296M参数时,在ImageNet、ImageNet ReaL和ImageNet-V2上可分别达到87.1%、90.6%和78.0%的top-1精度,为所有三个分类基准设定了新的SOTA性能。

如上图所示,与先前最先进的基于CNN的模型(NFNet-F6[2]和SAM[15])以及基于变压器的模型(带有KD的CaiT-M48[52])相比,我们的最佳模型VOLO-D5利用了最少的可学习参数,但实现了最佳的精度。此外,如表1所示,即使与以前使用更强的数据扩充和优化方法的最新模型(如SAM[15]和augmult[16])相比,我们的Outlooker仍然表现最好。
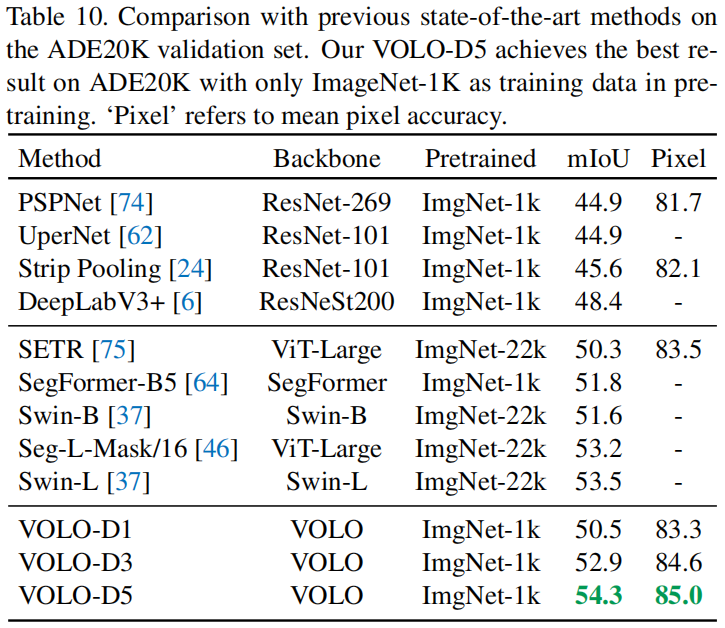
我们的VOLO在语义分割任务上也取得了很好的性能。我们在两个广泛使用的分割基准上进行了实验:Cityscapes[10]和ADE20K[77]。实验表明,我们的VOLO在Cityscapes验证集上获得了84.3%的mIoU分数,比SegFormer-B5[64]的最新结果好0.3%。在ADE20K验证集上,我们获得了54.3%的mIoU分数,大大提高了在ImageNet-22k上预训练的Swin Transformer[37]的最新结果(53.5%)。
2、方法
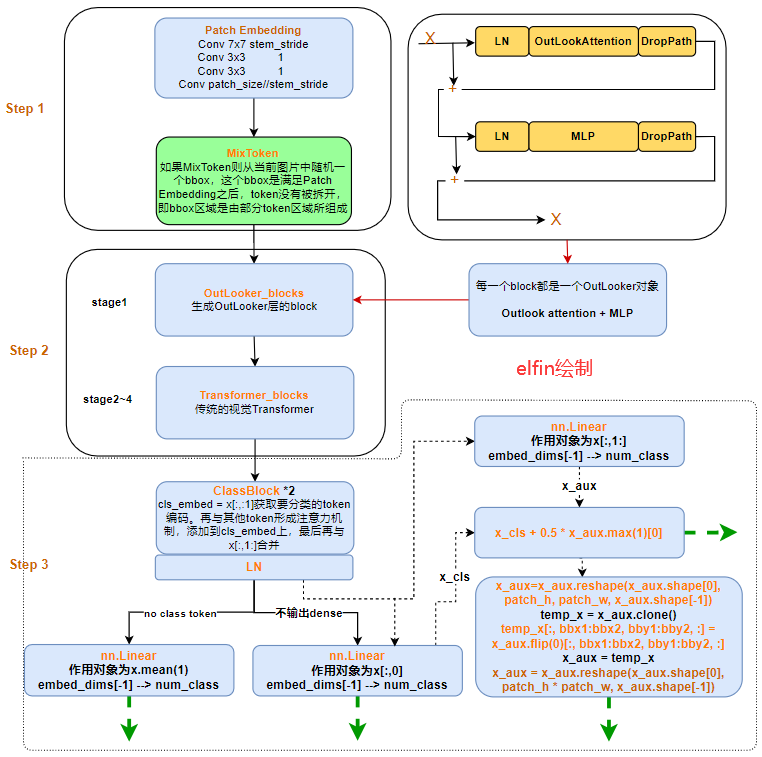
我们的模型可以看作是一个具有两个独立阶段的架构。第一阶段由一堆outlooker组成,这些outlooker生成精细级别的token表示。第二阶段部署一系列transformer块来聚合全局信息。在每一阶段的开始,使用patch嵌入模块将输入映射到具有设计形状的token表示。
2.1 Outlooker
Outlooker由用于空间信息编码的outlook注意力层和用于通道间信息交互的多层感知器(MLP)组成。对于给定的(C)维token序列(mathbf{X} in mathbb{R}^{H imes W imes C}),Outlooker过程可以表示为:
其中,LN表示LayerNorm。
作者在设计网络架构的时候,首先PatchEmbed,然后分为4个stage,所有模型都只有第一个是Outlooker。
论文中的Outlook attention是这样的
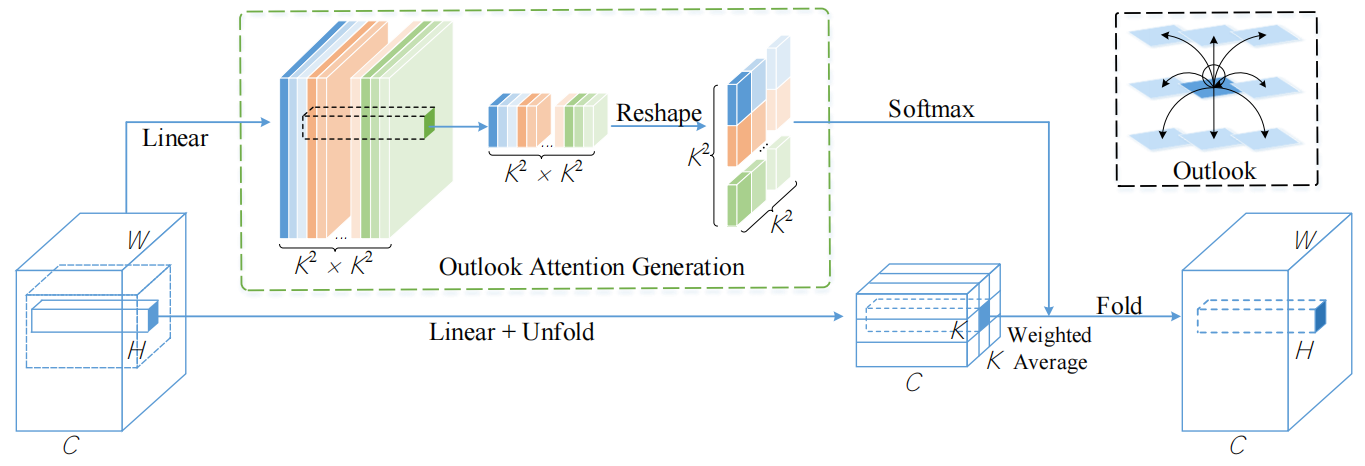
我眼中的Outlook attention是这样的
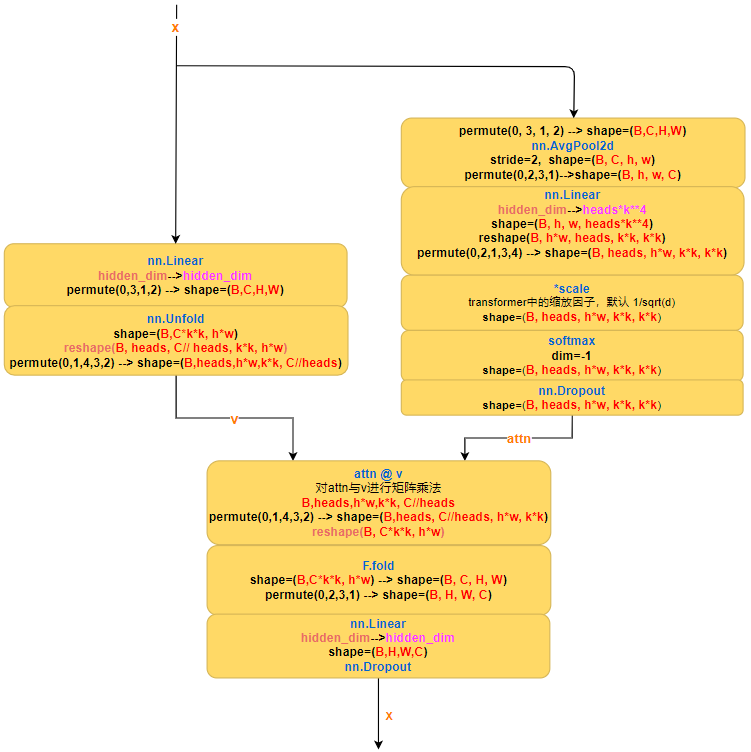
也许你看论文的图示有点云里雾里,我相信上图会给你较为清晰的解释,如果不知道Ufold与Fold可以参考博客Unfold与fold介绍。
2.1.1 Outlook Attention
Outlook attention简单、高效、易于实现。其背后的主要见解是:
- 1)每个空间位置的特征具有足够的代表性,可以生成关注权重,用于局部聚集其相邻特征;
- 2) 密集的局部空间聚集可以有效地编码精细层次的信息。
对于每个空间位置(left(i,j ight)),outlook attention计算其与以(left(i,j ight))为中心,大小(K imes K)的局部窗口中的所有邻居的相似度。与自我注意力不同,自我注意力需要查询键矩阵乘法来计算注意(即,(Softmaxleft ( extbf{Q}^{ ext{T}} extbf{K}/sqrt{d} ight ))),outlook attention通过一个reshape操作简化了这个过程。
最终,给定一个输入(mathbf{X}),每一个(C)维的token会被映射,使用两个线性层(权值分别为(mathbf{W}_{A}in mathbb{R}^{C imes K^{4}})和(mathbf{W}_{V}in mathbb{R}^{C imes C}))分别映射到outlook权值(mathbf{A}in mathbb{R}^{H imes W imes K^{4}}) 和值表示 (mathbf{V}in mathbb{R}^{H imes W imes C}) 。使用(mathbf{V}_{Delta_{i,j}} in mathbb{R}^{C imes K^{2}})表示以(left(i,j ight))为中心的局部窗口的所有值,即:
Outlook attention
在位置(left(i,j ight))的outlook权值直接被用作值聚合的注意力权值,它将使用reshape操作得到(hat{mathbf{A}}_{i,j} in mathbb{R}^{K^{2} imes K^{2}}),接着使用(Softmax)函数。所以值映射过程可以表示为:
Dense aggregation 密集聚集
Outlook attention密集地聚合了投影值表示。将来自不同局部窗口的同一位置的不同加权值相加得到输出:
公式(3)、(5)分别对应了Unfold、fold操作。在 outlook attention之后,经常使用一个线性层作为自注意力。
2.1.2 Multi-Head Outlook Attention
多头注意力的实现非常简单。假设head number设置为N。这里我们只需要调整:
- 将(mathbf{W}_{A})的维度变为(C imes N cdot K^{4}),这里相当于有(N)个之前的(mathbf{W}_{A}),类似于group分组;
- 生成(N)个outlook权值(mathbf{A}_{n} in mathbb{R}^{H imes W imes K^{4}});
- 生成(N)个值表示(mathbf{V}_{n} in mathbb{R}^{H imes W imes C_{N}});
其中,(C_{N} imes N = C). 对于任意的数据对 (left( mathbf{A}_{n}, mathbf{V}_{n} ight)) ,这里将outlook attention分开计算,最后聚合结果形成多头注意力机制。在实验部分,我们将讨论头数对模型性能的影响。
2.1.3 讨论
我们的outlook注意力继承了卷积和自注意力的优点。它具有以下优点。
- 首先,outlook attention通过度量token表示之间的相似性来编码空间信息,这对于特征学习来说比卷积更有效,正如前面的工作[37,45]中所研究的那样。
- 第二,前景注意采用滑动窗口机制对表征进行局部精细编码,并在一定程度上保留了视觉任务的关键位置信息[25,56]。
- 第三,产生注意力权重的方法简单有效。与依赖于查询、键矩阵乘法的自我关注不同,我们的outlook权重可以通过简单的reshape操作直接产生,节省了计算量。
为了直观地感受,我们分别计算自注意力(SA)、局部自注意力(LSA)、Outlook注意力三种注意力在多头情况下的计算量,我们只计算在size为(K imes K)的滑动窗口上的(H imes W) tokens操作:
我们考虑一般情形,假设(C=384,quad K=3, quad N=6),则公式(8)是最高效的,因为(NK^{2} <2C)。
当然(NK^{2} <2C)这个条件也很容易不成立。
2.2 网络架构变体
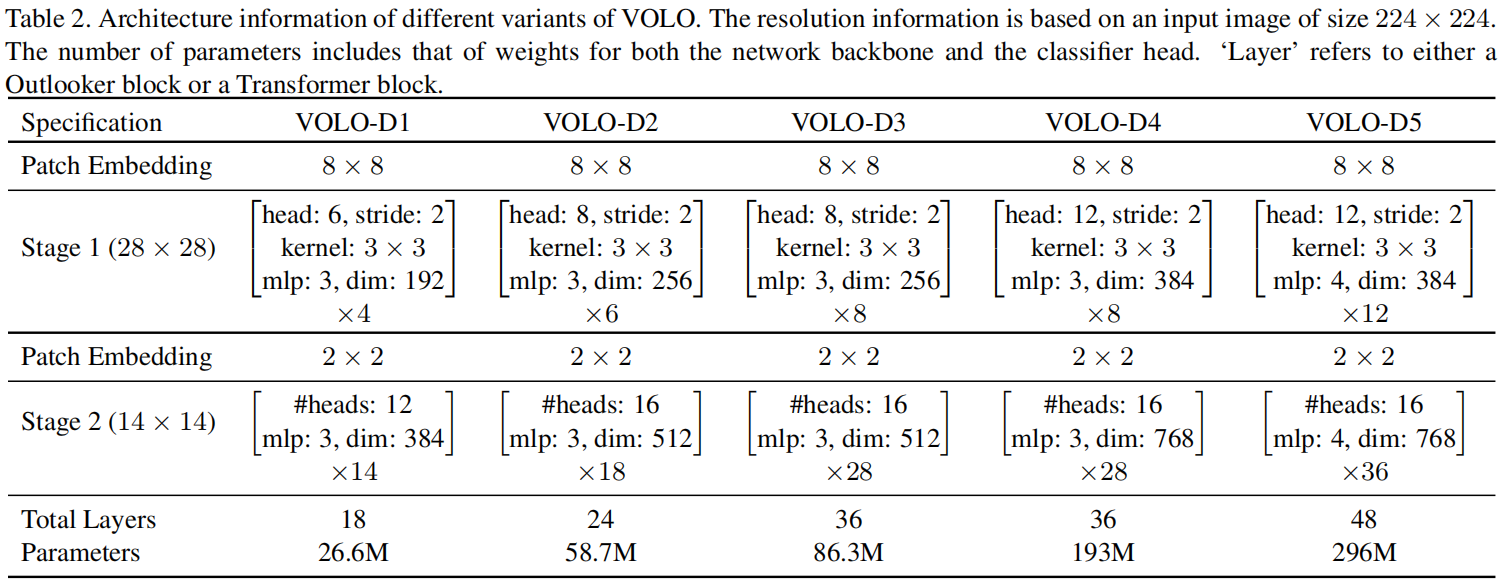
这里基于LV-ViT模型构造了VOLO模型,我们得到了一个健壮的baseline模型,它在ImageNet上实现了(86.2\%)的top-1准确率,参数量只有150M。原始的LV-ViT模型是由patch编码组成的,它将输入为(224 imes 224)的图像,将其映射到(14 imes 14)的tokens。为了利用精细级别的token表示,在第一阶段,我们调整了补丁嵌入模块,使图像在大小为(8 imes 8)而不是(16 imes 16)的图像补丁上进行token化。使用一个Outlookers堆栈在精细级别生成更具表现力的token表示。在第二阶段,利用另一个补丁嵌入模块对token进行下采样。然后采用一系列transformer对全局信息进行编码。
基于上述网络结构,我们介绍了五个版本的VOLO: VOLO-D1、VOLO-D2、VOLO-D3、VOLO-D4和VOLO-D5。所有五个版本的详细超参数设置见表2。在所有版本中,我们都将Outlooker和Transformer的比率保持在1:3左右,这在我们的实验中是最有效的。在最后阶段,我们还添加了两个类注意层[52],以更新类嵌入。Outlookers中的隐藏维度设置为Transformers中的一半。
小结:
模型的实现示意图:
3、实验
实验数据集:ImageNet
代码实现:基于pytorch
优化器:AdamW优化器
学习率:采用线性学习率缩放策略,(lr= ext{LR}_{base} imes frac{batch\_size}{1024}),权值衰减系数(5 imes 10^{-2})。
数据增强:CutOut、RandAug、Token Labeling objective with MixToken(不使用MixUp、CutMix)。
GPU:8张V100、A100
基础配置见下表:

我们发现较大的模型(参数大于100M)会出现过度拟合。为了缓解这个问题,我们为它们设置了较大的随机深度概率。此外,学习率的选择对学习性能也有轻微的影响。我们发现,对于小尺寸模型,使用较大的初始学习率更为有利。此外,裁剪比例也会略微影响性能。更大的模型更喜欢更大的裁剪比例。
3.1 实验结果
3.2 Outlooker的表现
VOLO-D1的性能如下:
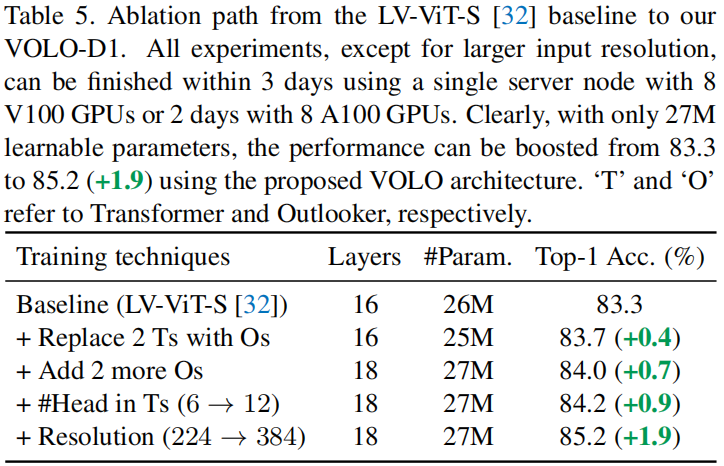
Outlooker层的影响:

3.3 消融实验
模型放缩: 设置了不同的模型: VOLO-D1 ~ VOLO-D5.
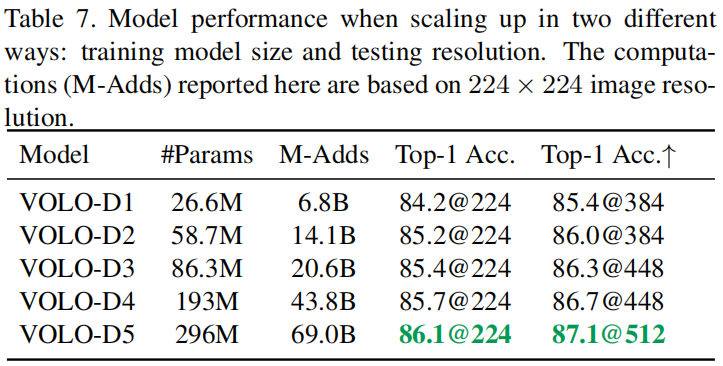
Outlooker的数量、Outlooker的头数量:
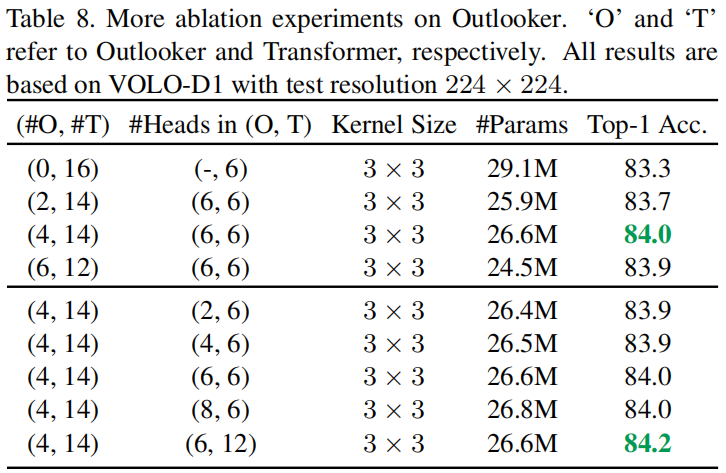
3.4 语义分割
基于预训练模型在语义分割的数据集上测试。
Cityscapes

ADE20K
4、相关工作
图像分类作为计算机视觉中最基本的问题之一,自从深度神经网络模型的引入以来,已经取得了显著的进展。接下来,我们将简要回顾那些与这项工作密切相关的成功模式。
早期达到图像分类最先进性能的模型大多是基于CNN的模型,这些模型简单地叠加了一系列空间卷积和池化层,如AlexNet[33]和VGGNet[44]表示。ResNets[20]通过引入skip连接来支持非常深层模型的训练,从而推进了CNN架构的设计。Inceptions[48、49、47]和ResNeXt[65]研究了模型构建块的设计原则,并引入了多组专用滤波器的并行路径。SENet[27]提出了一个压缩和激励模块来显式地建模通道之间的相互依赖关系。DPN[7]利用residual连接和dense连接来设计更强大的构建块。EfficientNet[50]和NasNet[80]利用神经结构搜索来搜索强大的网络结构。后来的最新模型[30、53、63]大多采用不同的训练或优化方法或微调技术来提高网络效率。最近,NFNet[2]通过设计一个无规范化的体系结构打破了EfficientNet的主导地位,是第一个工作在ImageNet上实现了86.5%的top-1精度,而不需要额外的数据。CNNs作为事实上的视觉识别网络,多年来确实取得了很大的成功,但其研究的重点是如何通过设计更好的体系结构来学习更具辨别力的局部特征。本质上,它们缺乏在已被证明至关重要的表示之间显式构建全局关系的能力[58]。
图像分类的最新进展主要是由基于注意力的模型[73,58,26]或特别是基于transformer的模型推动的。transformer利用了自我注意机制,使得远程依赖的建模成为可能。transformer[55]最初设计用于自然语言任务[13、41、3、67、40、36],最近被证明在图像分类方面是有效的。Dosovitskiy等人[14]率先表明,纯基于transformer的架构(即ViT)也可以在图像分类中获得最先进的性能,但需要大规模的数据集,如ImageNet-22k和JFT-300M(尚未公开)进行预训练。DeiT[51]和T2T-ViT[68]缓解了ViT需要大规模数据集的问题,提出了数据高效的ViT。从那时起,随着技术的进一步发展,基于ViT的研究工作不断涌现。其中一些[4,19,61,54,79]通过修改patch 编码或修改transformer块或两者,将局部依赖引入视觉transformer中,而另一些[21,37,57]采用金字塔结构,在保持模型捕捉低级特征的能力的同时,减少整体计算量。也有一些工作[78,71,52,18]旨在解决ViTs的优化和定标问题。
我们的VOLO不仅对长程依赖性建模,而且还通过Outlooker将精细级别的特征编码为token表示。与最近依赖卷积进行特征编码的混合架构(例如,Hybrid-ViT[14]和BoTNet[45])不同,Outlooker建议使用局部成对token相似性将精细级别的特征和空间上下文编码为token特征,因此更有效和参数效率更高。这也使得我们的模型不同于动态卷积[60]和Involution[34],后者生成依赖输入的卷积核来编码特征。
5、总结
我们提出了一个新的模型,Vision Outlooker(VOLO)。大量的图像分类和分割实验表明,VOLO模型优于CNN和Transformer模型,并建立了新的SOTA结果。我们希望VOLO在一些计算机视觉任务上的强大表现将鼓励后续研究更好的精细特征学习。VOLO的性能优势来自于新的outlook注意机制,它以一种密集的方式动态地聚集精细级别的特征,我们将继续在其他应用程序中进行研究,如自然语言处理。
6、感想
近几个月transformer模型大行其道,各种技巧层出不穷,每新出一个技术总会让我们欣喜不已,但是这个VOLO不仅性能指标更好;作者在处理精细特征、结构设计上都给我们很大的启示。
完!