SQL去重的三种方法汇总
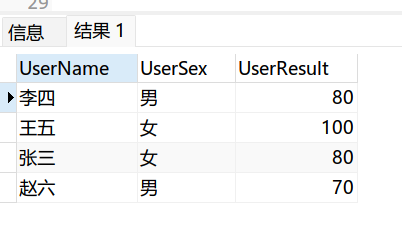
这里的去重是指:查询的时候, 不显示重复,并不是删除表中的重复项
1.distinct去重
注意的点:distinct
只能一列去重,当distinct后跟大于1个参数时,他们之间的关系是&&(逻辑与)关系,只有全部条件相同才会去重
弊端:当查询的字段比较多时,distinct会作用多个字段,导致去重条件增多
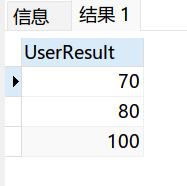
select distinct UserResult from Table1
2.group by去重
去重原理:将重复的行进行分组,相同的数据只显示第一行
弊端:使用group by后,所有查询字段都需要使用聚合函数,比较繁琐
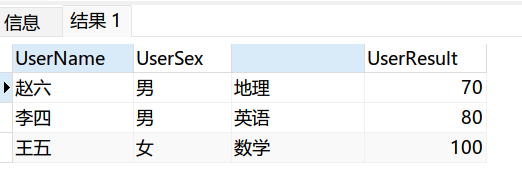
select min(UserName)UserName,min(UserSex)UserSex,min(UserSubject)UserSubject,min(UserResult)UserResult from Table1
group by UserResult
3.row_number() over (parttion by 分组列 order by 排序列)
弊端:小孟还不知道
去重原理:现根据重复列进行分组,分组后再进行排序,不同的组序号为1,相同的组序号为2,排除为2的就达到了去重效果
select *from
(
--查询出重复行
select *,row_number() over (partition by UserResult order by UserResult desc)num from Table1
)A
where A.num=1

这里安利第三个,row_number(),稳一些!