公司主要做的事物联网和数字孪生,下半年我们项目要接入大数据,要进行处理再整合Drools,进行规则预警。最近几个月一直在忙pmp考试和平时工作,也没有进行学习整理,最近就开始学习flink和kafka,记点笔记。
Flink组件栈
一个计算框架要有长远的发展,必须打造一个完整的 Stack。只有上层有了具体的应用,并能很好的发挥计算框架本身的优势,那么这个计算框架才能吸引更多的资源,才会更快的进步。所以 Flink 也在努力构建自己的 Stack。
Flink分层的组件栈如下图所示:每一层所包含的组件都提供了特定的抽象,用来服务于上层组件。
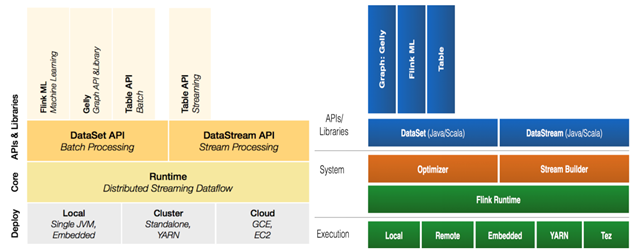
各层详细介绍:
-
物理部署层:Flink 支持本地运行、能在独立集群或者在被 YARN 管理的集群上运行,也能部署在云上,该层主要涉及Flink的部署模式,目前Flink支持多种部署模式:本地、集群(Standalone、YARN)、云(GCE/EC2)、Kubenetes。Flink能够通过该层能够支持不同平台的部署,用户可以根据需要选择使用对应的部署模式。
-
Runtime核心层:Runtime层提供了支持Flink计算的全部核心实现,为上层API层提供基础服务,该层主要负责对上层不同接口提供基础服务,也是Flink分布式计算框架的核心实现层,支持分布式Stream作业的执行、JobGraph到ExecutionGraph的映射转换、任务调度等。将DataSteam和DataSet转成统一的可执行的Task Operator,达到在流式引擎下同时处理批量计算和流式计算的目的。
-
API&Libraries层:Flink 首先支持了 Scala 和 Java 的 API,Python也正在测试中。DataStream、DataSet、Table、SQL API,作为分布式数据处理框架,Flink同时提供了支撑计算和批计算的接口,两者都提供给用户丰富的数据处理高级API,例如Map、FlatMap操作等,也提供比较低级的Process Function API,用户可以直接操作状态和时间等底层数据。
-
扩展库:Flink 还包括用于复杂事件处理的CEP,机器学习库FlinkML,图处理库Gelly等。Table 是一种接口化的 SQL 支持,也就是 API 支持(DSL),而不是文本化的SQL解析和执行。
Flink基石
Flink之所以能这么流行,离不开它最重要的四个基石:Checkpoint、State、Time、Window。

-
Checkpoint
这是Flink最重要的一个特性。
Flink基于Chandy-Lamport算法实现了一个分布式的一致性的快照,从而提供了一致性的语义。
Chandy-Lamport算法实际上在1985年的时候已经被提出来,但并没有被很广泛的应用,而Flink则把这个算法发扬光大了。
Spark最近在实现Continue streaming,Continue
streaming的目的是为了降低处理的延时,其也需要提供这种一致性的语义,最终也采用了Chandy-Lamport这个算法,说明Chandy-Lamport算法在业界得到了一定的肯定。 -
State
提供了一致性的语义之后,Flink为了让用户在编程时能够更轻松、更容易地去管理状态,还提供了一套非常简单明了的State
API,包括里面的有ValueState、ListState、MapState,近期添加了BroadcastState,使用State
API能够自动享受到这种一致性的语义。 -
Time
除此之外,Flink还实现了Watermark的机制,能够支持基于事件的时间的处理,能够容忍迟到/乱序的数据。
-
Window
另外流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算。Flink提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口。
Flink用武之地
http://www.liaojiayi.com/flink-IoT/
https://flink.apache.org/zh/usecases.html
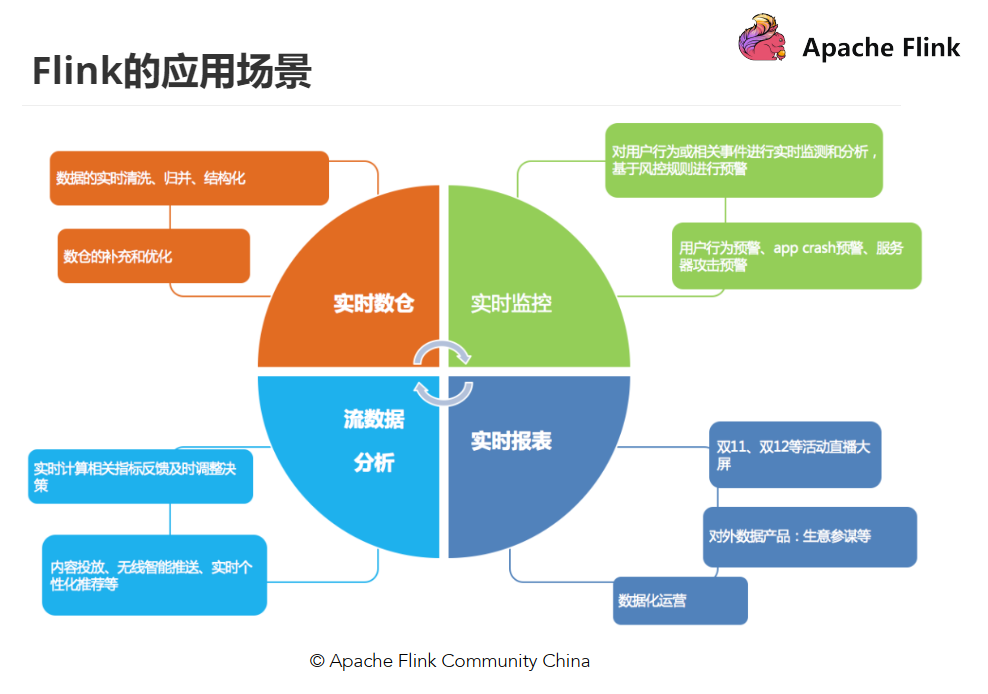
从很多公司的应用案例发现,其实Flink主要用在如下三大场景:
Event-driven Applications【事件驱动】
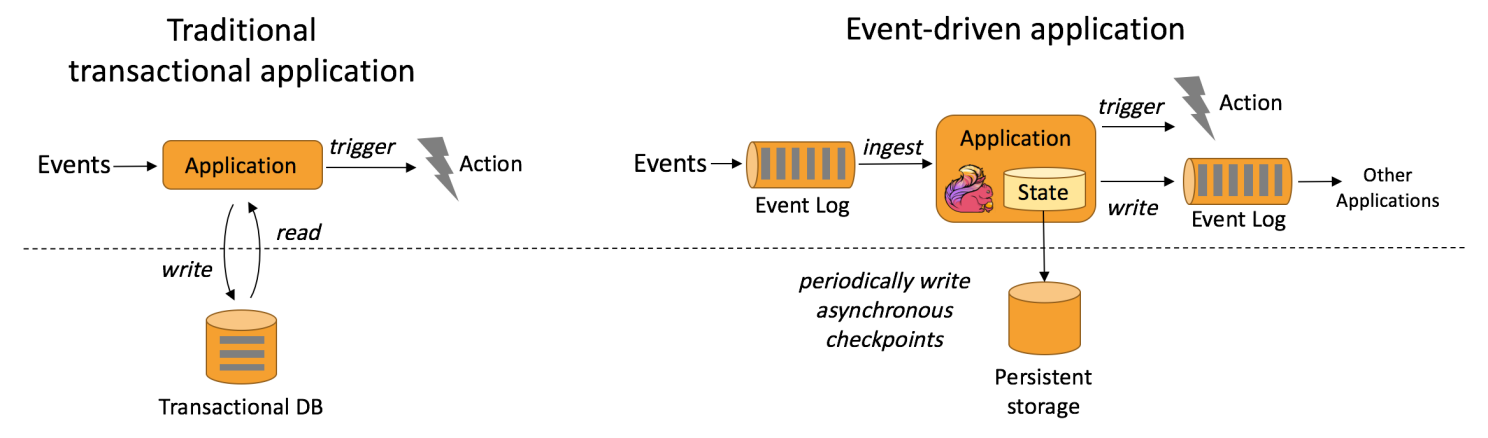
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
事件驱动型应用是在计算存储分离的传统应用基础上进化而来。
在传统架构中,应用需要读写远程事务型数据库。
相反,事件驱动型应用是基于状态化流处理来完成。在该设计中,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据。
系统容错性的实现依赖于定期向远程持久化存储写入checkpoint。下图描述了传统应用和事件驱动型应用架构的区别。
从某种程度上来说,所有的实时的数据处理或者是流式数据处理都应该是属于Data Driven,流计算本质上是Data Driven计算。应用较多的如风控系统,当风控系统需要处理各种各样复杂的规则时,Data Driven就会把处理的规则和逻辑写入到Datastream 的API 或者是ProcessFunction 的API中,然后将逻辑抽象到整个Flink引擎,当外面的数据流或者是事件进入就会触发相应的规则,这就是Data Driven的原理。在触发某些规则后,Data Driven会进行处理或者是进行预警,这些预警会发到下游产生业务通知,这是Data Driven的应用场景,Data Driven 在应用上更多应用于复杂事件的处理。
典型实例:
-
欺诈检测(Fraud detection)
-
异常检测(Anomaly detection)
-
基于规则的告警(Rule-based alerting)
-
业务流程监控(Business process monitoring)
-
Web应用程序(社交网络)
Data Analytics Applications【数据分析】
数据分析任务需要从原始数据中提取有价值的信息和指标。如下图所示,Apache Flink 同时支持流式及批量分析应用。
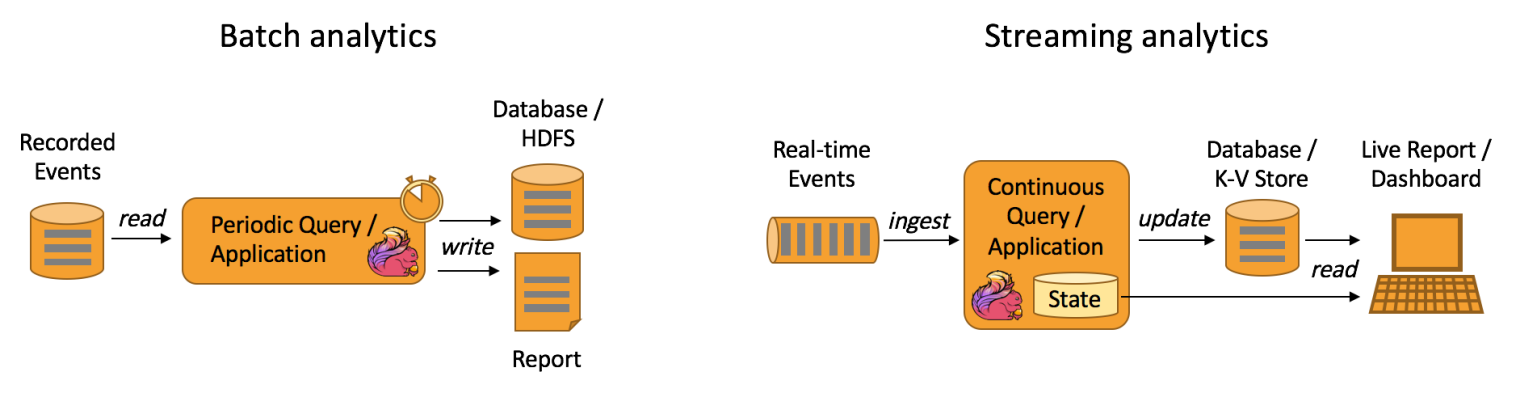
Data Analytics Applications包含Batch analytics(批处理分析)和Streaming analytics(流处理分析)
Batch analytics可以理解为周期性查询:Batch Analytics 就是传统意义上使用类似于Map Reduce、Hive、Spark Batch等,对作业进行分析、处理、生成离线报表。比如Flink应用凌晨从Recorded Events中读取昨天的数据,然后做周期查询运算,最后将数据写入Database或者HDFS,或者直接将数据生成报表供公司上层领导决策使用。
Streaming analytics可以理解为连续性查询:比如实时展示双十一天猫销售GMV(Gross Merchandise Volume成交总额),用户下单数据需要实时写入消息队列,Flink应用源源不断读取数据做实时计算,然后不断的将数据更新至Database或者K-VStore,最后做大屏实时展示。
典型实例
-
电信网络质量监控
-
移动应用中的产品更新及实验评估分析
-
消费者技术中的实时数据即席分析
-
大规模图分析
Data Pipeline Applications【数据管道】
什么是数据管道?
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。
ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。
数据管道和 ETL作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。
但数据管道是以持续流模式运行,而非周期性触发。因此数据管道支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。
例如:数据管道可以用来监控文件系统目录中的新文件,并将其数据写入事件日志;另一个应用可能会将事件流物化到数据库或增量构建和优化查询索引。
和周期性 ETL 作业相比,持续数据管道可以明显降低将数据移动到目的端的延迟。此外,由于它能够持续消费和发送数据,因此用途更广,支持用例更多。
下图描述了周期性ETL作业和持续数据管道的差异。
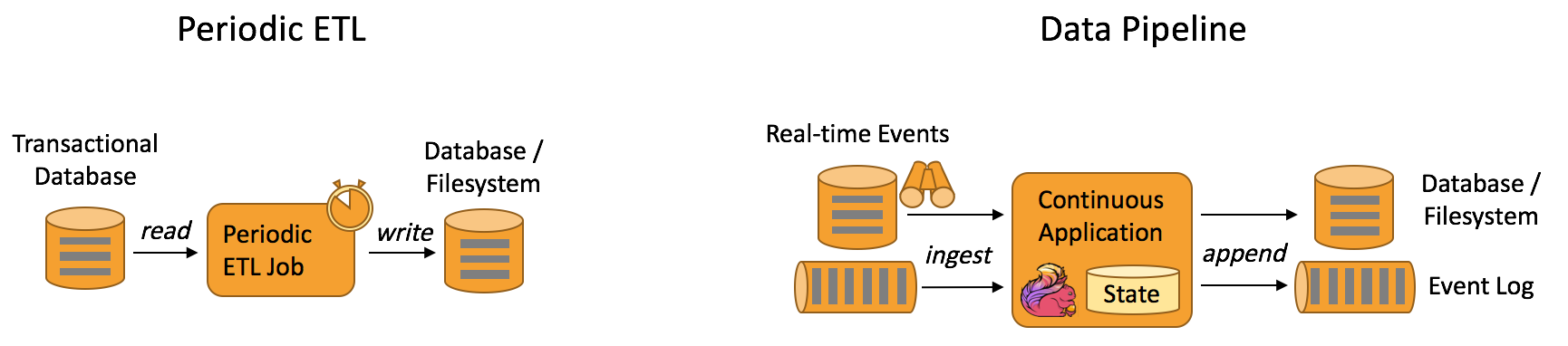
Periodic ETL:比如每天凌晨周期性的启动一个Flink ETL Job,读取传统数据库中的数据,然后做ETL,最后写入数据库和文件系统。
Data Pipeline:比如启动一个Flink实时应用,数据源(比如数据库、Kafka)中的数据不断的通过Flink Data Pipeline流入或者追加到数据仓库(数据库或者文件系统),或者Kafka消息队列。
Data Pipeline的核心场景类似于数据搬运并在搬运的过程中进行部分数据清洗或者处理,而整个业务架构图的左边是Periodic ETL,它提供了流式ETL
或者实时ETL,能够订阅消息队列的消息并进行处理,清洗完成后实时写入到下游的Database或File system 中。
典型实例
- 电子商务中的持续 ETL(实时数仓)
当下游要构建实时数仓时,上游则可能需要实时的Stream ETL。这个过程会进行实时清洗或扩展数据,清洗完成后写入到下游的实时数仓的整个链路中,可保证数据查询的时效性,形成实时数据采集、实时数据处理以及下游的实时Query。
- 电子商务中的实时查询索引构建(搜索引擎推荐)
搜索引擎这块以淘宝为例,当卖家上线新商品时,后台会实时产生消息流,该消息流经过Flink系统时会进行数据的处理、扩展。然后将处理及扩展后的数据生成实时索引,写入到搜索引擎中。这样当淘宝卖家上线新商品时,能在秒级或者分钟级实现搜索引擎的搜索。
Flink的优势

- 主要原因
-
Flink 具备统一的框架处理有界和无界两种数据流的能力
-
部署灵活,Flink 底层支持多种资源调度器,包括Yarn、Kubernetes 等。Flink自身带的Standalone 的调度器,在部署上也十分灵活。
-
极高的可伸缩性,可伸缩性对于分布式系统十分重要,阿里巴巴双11大屏采用Flink处理海量数据,使用过程中测得Flink 峰值可达17 亿条/秒。
-
极致的流式处理性能。Flink 相对于Storm最大的特点是将状态语义完全抽象到框架中,支持本地状态读取,避免了大量网络IO,可以极大提升状态存取的性能。
- 其他更多的原因:
- 同时支持高吞吐、低延迟、高性能
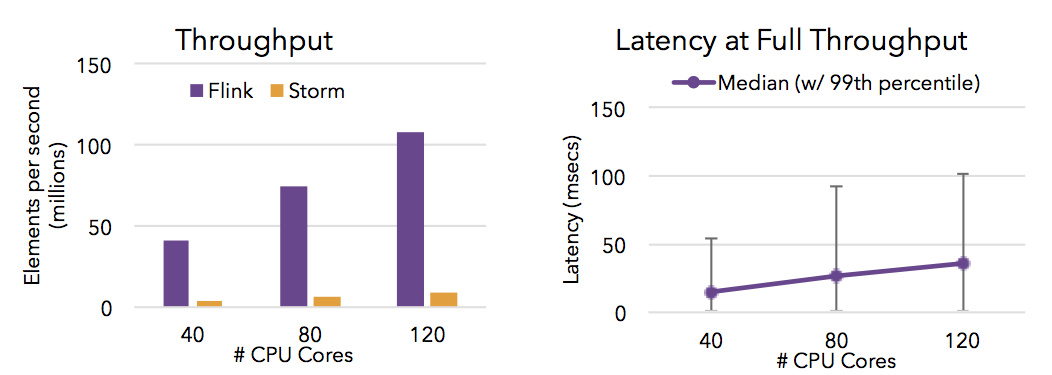
Flink是目前开源社区中唯一一套集高吞吐、低延迟、高性能三者于一身的分布式流式数据处理框架。
Spark只能兼顾高吞吐和高性能特性,无法做到低延迟保障,因为Spark是用批处理来做流处理
Storm 只能支持低延时和高性能特性,无法满足高吞吐的要求下图显示了 Apache Flink 与 Apache Storm 在完成流数据清洗的分布式任务的性能对比。
支持事件时间(Event Time)概念
在流式计算领域中,窗口计算的地位举足轻重,但目前大多数框架窗口计算采用的都是系统时间(ProcessTime),也就是事件传输到计算框架处理时,系统主机的当前时间。
Flink 能够支持基于事件时间(Event Time)语义进行窗口计算
这种基于事件驱动的机制使得事件即使乱序到达甚至延迟到达,流系统也能够计算出精确的结果,保持了事件原本产生时的时序性,尽可能避免网络传输或硬件系统的影响。

支持有状态计算
Flink1.4开始支持有状态计算
所谓状态就是在流式计算过程中将算子的中间结果保存在内存或者文件系统中,等下一个事件进入算子后可以从之前的状态中获取中间结果,计算当前的结果,从而无须每次都基于全部的原始数据来统计结果,极大的提升了系统性能,状态化意味着应用可以维护随着时间推移已经产生的数据聚合
支持高度灵活的窗口(Window)操作
Flink 将窗口划分为基于 Time 、Count、Session、以及Data-Driven等类型的窗口操作,窗口可以用灵活的触发条件定制化来达到对复杂的流传输模式的支持,用户可以定义不同的窗口触发机制来满足不同的需求
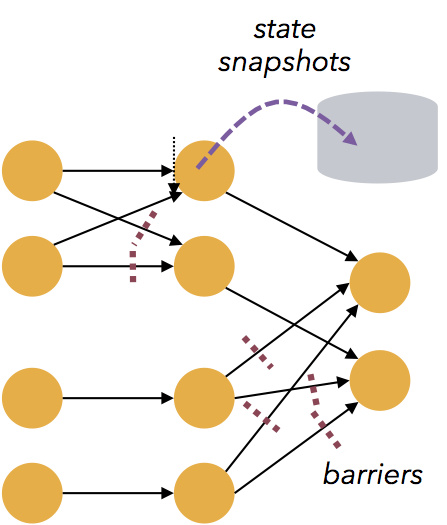
基于轻量级分布式快照(Snapshot/Checkpoints)的容错机制
Flink能够分布运行在上千个节点上,通过基于分布式快照技术的Checkpoints,将执行过程中的状态信息进行持久化存储,一旦任务出现异常停止,Flink
能够从 Checkpoints 中进行任务的自动恢复,以确保数据处理过程中的一致性
Flink的容错能力是轻量级的,允许系统保持高并发,同时在相同时间内提供强一致性保证。
基于 JVM 实现的独立的内存管理
Flink实现了自身管理内存的机制,通过使用散列,索引,缓存和排序有效地进行内存管理,通过序列化/反序列化机制将所有的数据对象转换成二进制在内存中存储,降低数据存储大小的同时,更加有效的利用空间。使其独立于Java 的默认垃圾收集器,尽可能减少 JVM GC 对系统的影响。
SavePoints 保存点
对于 7 * 24小时运行的流式应用,数据源源不断的流入,在一段时间内应用的终止有可能导致数据的丢失或者计算结果的不准确。比如集群版本的升级,停机运维操作等。值得一提的是,Flink 通过SavePoints技术将任务执行的快照保存在存储介质上,当任务重启的时候,可以从事先保存的SavePoints 恢复原有的计算状态,使得任务继续按照停机之前的状态运行。
Flink保存点提供了一个状态化的版本机制,使得能以无丢失状态和最短停机时间的方式更新应用或者回退历史数据。

灵活的部署方式,支持大规模集群
Flink 被设计成能用上千个点在大规模集群上运行除了支持独立集群部署外,Flink 还支持 YARN 和Mesos 方式部署。
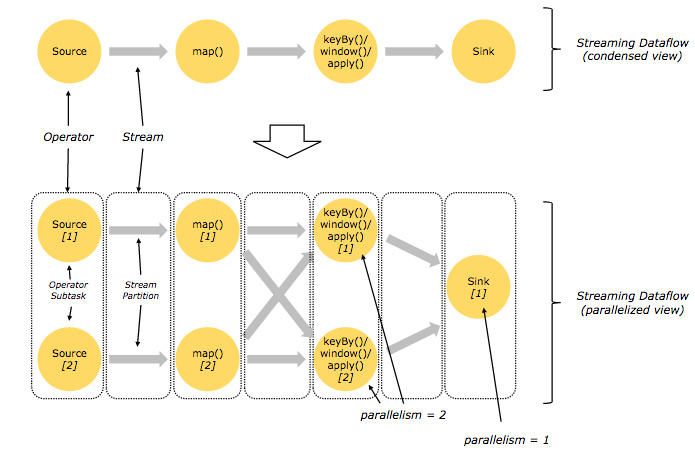
Flink 的程序内在是并行和分布式的
数据流可以被分区成 stream partitions,operators 被划分为operator subtasks;这些 subtasks 在不同的机器或容器中分不同的线程独立运行;
operator subtasks 的数量就是operator的并行计算数,不同的 operator阶段可能有不同的并行数;如下图所示,source operator 的并行数为 2,但最后的 sink operator 为1;
丰富的库
Flink 拥有丰富的库来进行机器学习,图形处理,关系数据处理等。
流处理 VS 批处理
- 数据的时效性
日常工作中,我们一般会先把数据存储在表,然后对表的数据进行加工、分析。既然先存储在表中,那就会涉及到时效性概念。
如果我们处理以年,月为单位的级别的数据处理,进行统计分析,个性化推荐,那么数据的的最新日期离当前有几个甚至上月都没有问题。但是如果我们处理的是以天为级别,或者一小时甚至更小粒度的数据处理,那么就要求数据的时效性更高了。比如:
- 对网站的实时监控
这些场景需要工作人员立即响应,这样的场景下,传统的统一收集数据,再存到数据库中,再取出来进行分析就无法满足高时效性的需求了。
- 流式计算和批量计算

- Batch Analytics,右边是 Streaming Analytics。批量计算:统一收集数据->存储到DB->对数据进行批量处理,就是传统意义上使用类似于 Map Reduce、Hive、Spark Batch 等,对作业进行分析、处理、生成离线报表
- Streaming Analytics流式计算,顾名思义,就是对数据流进行处理,如使用流式分析引擎如Storm,Flink 实时处理分析数据,应用较多的场景如实时大屏、实时报表。
它们的主要区别是:
-
与批量计算那样慢慢积累数据不同,流式计算立刻计算,数据持续流动,计算完之后就丢弃。
-
批量计算是维护一张表,对表进行实施各种计算逻辑。流式计算相反,是必须先定义好计算逻辑,提交到流式计算系统,这个计算作业逻辑在整个运行期间是不可更改的。
-
计算结果上,批量计算对全部数据进行计算后传输结果,流式计算是每次小批量计算后,结果可以立刻实时化展现。
-
流批统一
在大数据处理领域,批处理任务与流处理任务一般被认为是两种不同的任务,一个大数据框架一般会被设计为只能处理其中一种任务:
MapReduce只支持批处理任务;Storm只支持流处理任务;Spark Streaming采用micro-batch架构,本质上还是基于Spark批处理对流式数据进行处理
Flink通过灵活的执行引擎,能够同时支持批处理任务与流处理任务
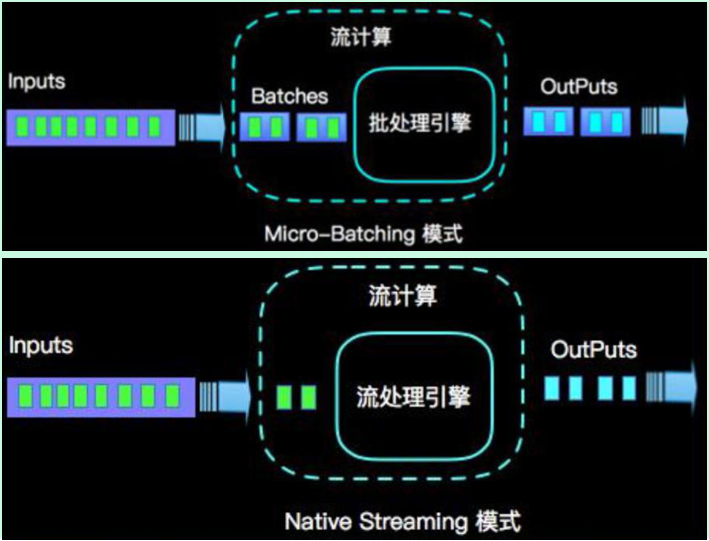
在执行引擎这一层,流处理系统与批处理系统最大不同在于节点间的数据传输方式:
1.对于一个流处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理
2.对于一个批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点这两种数据传输模式是两个极端,对应的是流处理系统对低延迟的要求和批处理系统对高吞吐量的要求Flink的执行引擎采用了一种十分灵活的方式,同时支持了这两种数据传输模型:Flink以固定的缓存块为单位进行网络数据传输,用户可以通过设置缓存块超时值指定缓存块的传输时机。如果缓存块的超时值为0,则Flink的数据传输方式类似上文所提到流处理系统的标准模型,此时系统可以获得最低的处理延迟
如果缓存块的超时值为无限大/-1,则Flink的数据传输方式类似上文所提到批处理系统的标准模型,此时系统可以获得最高的吞吐量同时缓存块的超时值也可以设置为0到无限大之间的任意值。缓存块的超时阈值越小,则Flink流处理执行引擎的数据处理延迟越低,但吞吐量也会降低,反之亦然。通过调整缓存块的超时阈值,用户可根据需求灵活地权衡系统延迟和吞吐量
默认情况下,流中的元素并不会一个一个的在网络中传输,而是缓存起来伺机一起发送(默认为32KB,通过taskmanager.memory.segment-size设置),这样可以避免导致频繁的网络传输,提高吞吐量,但如果数据源输入不够快的话会导致后续的数据处理延迟,所以可以使用env.setBufferTimeout(默认100ms),来为缓存填入设置一个最大等待时间。等待时间到了之后,即使缓存还未填满,缓存中的数据也会自动发送。
-
timeoutMillis > 0 表示最长等待 timeoutMillis 时间,就会flush
-
timeoutMillis = 0 表示每条数据都会触发flush,直接将数据发送到下游,相当于没有Buffer了(避免设置为0,可能导致性能下降)
-
timeoutMillis = -1 表示只有等到 buffer满了或CheckPoint的时候,才会flush。相当于取消了 timeout 策略
总结:
Flink以缓存块为单位进行网络数据传输,用户可以设置缓存块超时时间和缓存块大小来控制缓冲块传输时机,从而控制Flink的延迟性和吞吐量