告警的介绍
在前面当中,我们已经安装、配置并使用Prometheus了。现在,我们需要了解如何从监视数据生成有用的警报。
普罗米修斯是一个划分的平台,度量的收集和存储与警报是分开的。警报由称为Alertmanager的工具提供,这是
监视环境的独立部分。警报规则在Prometheus服务器上定义。这些规则可以触发事件,然后将其传播到
Alertmanager。Alertmanager随后决定如何处理各自的警报,处理复制之类的问题,并决定在发送警报时使用什么
机制:实时消息、电子邮件或其它工具。
常见的反人类模式设计:
警报方法中最常见的反模式是发送太多警报。太多的警报相当于监控“喊狼来了的男孩”。收件人将变得麻木,对
警告和不理会他们。关键的警报常常被淹没在不重要的更新的洪流中。
第二个最常见的反模式是警告的错误分类。
第三个最常见的反模式是发送无用的警告
良好的警示有一些关键特征:
- 嘈杂的提醒会导致警觉疲劳,最终,警告会被忽略。
- 应该设置正确的警报优先级。如果警报是紧急的,那么应该将其快速路由到负责响应的一方。如果警报不是紧急的,我们应该以适当的速度发送它,以便在需要时作出响应。
- 警报应该包含适当的上下文,使它们立即有用。
Alertmanager 介绍
alertmanager是Prometheus中的一个独立的告警模块,接受Prometheus发来警报,然后通过分组、删除重复等处理,并将他们通过路由发送给正确的接收器。

[root@localhost ~]# tar -zvxf alertmanager-0.21.0.linux-amd64.tar.gz
alertmanager-0.21.0.linux-amd64/
alertmanager-0.21.0.linux-amd64/alertmanager
alertmanager-0.21.0.linux-amd64/amtool
alertmanager-0.21.0.linux-amd64/NOTICE
alertmanager-0.21.0.linux-amd64/LICENSE
alertmanager-0.21.0.linux-amd64/alertmanager.yml
[root@localhost ~]# cp alertmanager-0.21.0.linux-amd64/alertmanager /usr/local/bin/
[root@localhost ~]# cp alertmanager-0.21.0.linux-amd64/amtool /usr/local/bin/
[root@localhost ~]# alertmanager --version
alertmanager, version 0.21.0 (branch: HEAD, revision: 4c6c03ebfe21009c546e4d1e9b92c371d67c021d)
build user: root@dee35927357f
build date: 20200617-08:54:02
go version: go1.14.4
[root@localhost ~]# mkdir -pv /etc/alertmanager
mkdir: 已创建目录 "/etc/alertmanager"
[root@localhost ~]# vim /etc/alertmanager/alertmanager.yml
[root@localhost ~]# alertmanager --config.file alertmanager.yml
配置 Alertmanager
[root@localhost ~]# cat /etc/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '332574835@qq.com'
smtp_auth_username: '332574835@qq.com'
smtp_auth_password: 'xxxxxxxxx'
smtp_require_tls: false
route:
receiver: mail
receivers:
- name: 'mail'
email_configs:
- to: 'dalianpai@126.com'
[root@localhost ~]#
启动 alertmanager
alertmanager --config.file alertmanager.yml

在 Prometheus 上添加 Alertmanager的配置


在 prometheus添加告警规则
[root@localhost ~]# cat /wgr/prometheus/rules/node_alerts.yml
groups:
- name: node_alerts
rules:
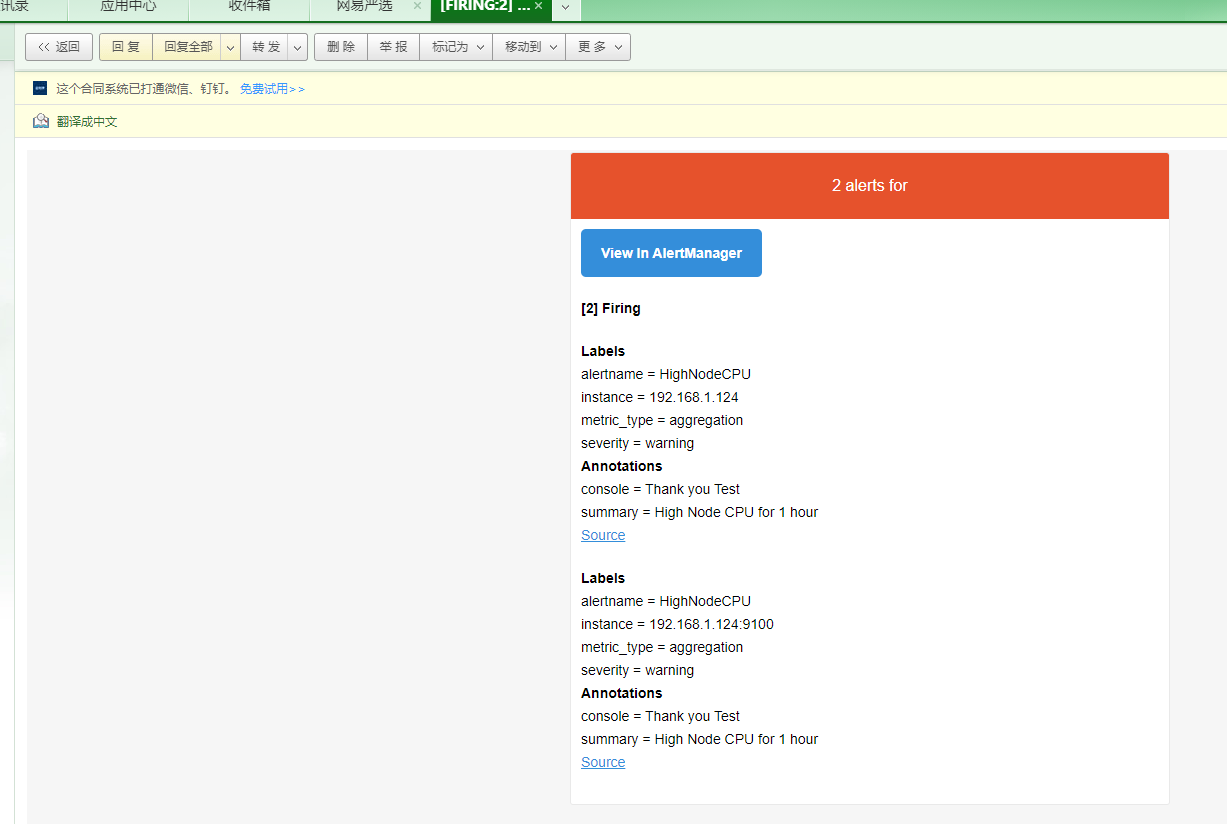
- alert: HighNodeCPU
expr: instance:node_cpu:avg_rate1m > 4
for: 10s
labels:
severity: warning
annotations:
summary: High Node CPU for 1 hour
console: Thank you Test
[root@localhost ~]#


进行重启Prometheus进行压测
java -DbusyNum=50 -jar cpu-used.jar #50代表cpu跑到50%,根据需要自定义填写