本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
1. Time三兄弟
1.1 DataStream支持的三种time
DataStream有大量基于time的operator,windows操作只是其中一种。
Flink支持三种time:
1.EventTime
2.IngestTime
3.ProcessingTime

1.2三个时间的比较
EventTime
1.事件生成时的时间,在进入Flink之前就已经存在,可以从event的字段中抽取。
2.必须指定watermarks(水位线)的生成方式。
3.优势:确定性,乱序、延时、或者数据重放等情况,都能给出正确的结果
4.弱点:处理无序事件时性能和延迟受到影响
IngestTime
1.事件进入flink的时间,即在source里获取的当前系统的时间,后续操作统一使用该时间。
2.不需要指定watermarks的生成方式(自动生成)
3.弱点:不能处理无序事件和延迟数据
ProcessingTime
1.执行操作的机器的当前系统时间(每个算子都不一样)
2.不需要流和机器之间的协调
3.优势:最佳的性能和最低的延迟
4.弱点:不确定性 ,容易受到各种因素影像(event产生的速度、到达flink的速度、在算子之间传输速度等),压根就不管顺序和延迟
比较
性能: ProcessingTime> IngestTime> EventTime
延迟: ProcessingTime< IngestTime< EventTime
确定性: EventTime> IngestTime> ProcessingTime
1.3根据业务选择最合适的时间
Hadoop的日志进入Flink的时间为2018-12-23 17:43:46,666(Ingest Time),在进入window操作时那台机器的系统时间是2018-12-23 17:43:47,120(Processing Time),日志的具体内容是:
(Event Time)2018-12-23 16:37:15,624 INFO org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider - Failing over to rm2
要统计每个5min内的日志error个数,哪个时间是最有意义的? 最佳选择就是【event time】。一般都需要使用event time,除非由于特殊情况只能用另外两种时间来代替。
1.4设置time类型
设置时间特性
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
不设置Time 类型,默认是processingTime。
如果使用EventTime则需要在source之后明确指定Timestamp Assigner & Watermark Generator(见后面小节)。
2. 时间戳和水位线背后的机制
2.1 Watermarks是干啥的
out-of-order/late element
实时系统中,由于各种原因造成的延时,造成某些消息发到flink的时间延时于事件产生的时间。如果基于event time构建window,但是对于late element,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark。
Watermarks(水位线)就是来处理这种问题的机制
1.参考google的DataFlow。
2.是event time处理进度的标志。
3.表示比watermark更早(更老)的事件都已经到达(没有比水位线更低的数据 )。
4.基于watermark来进行窗口触发计算的判断。
2.2有序流中Watermarks
在某些情况下,基于Event Time的数据流是有续的(相对event time)。在有序流中,watermark就是一个简单的周期性标记。
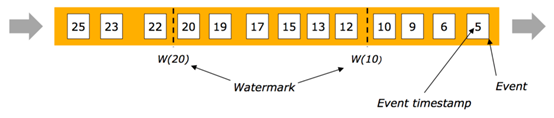
2.3乱序流中Watermarks
在更多场景下,基于Event Time的数据流是无续的(相对event time)。
在无序流中,watermark至关重要,她告诉operator比watermark更早(更老/时间戳更小)的事件已经到达, operator可以将内部事件时间提前到watermark的时间戳(可以触发window计算啦)
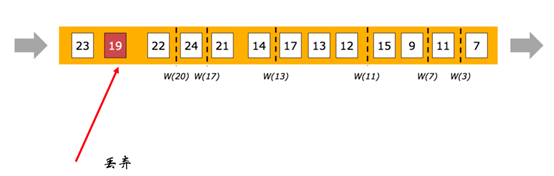
上图可以类比银行或者医院的排号来理解。
2.4并行流中的Watermarks
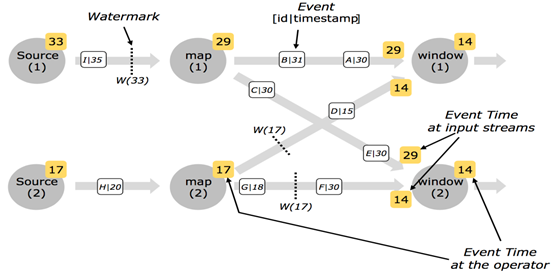
通常情况下, watermark在source函数中生成,但是也可以在source后任何阶段,如果指定多次 watermark,后面指定的 watermark会覆盖前面的值。 source的每个sub task独立生成水印。
watermark通过operator时会推进operators处的当前event time,同时operators会为下游生成一个新的watermark。
多输入operator(union、 keyBy、 partition)的当前event time是其输入流event time的最小值。
3.生成Timestamp和Watermark
3.1 Timestamp /Watermark两种生成方式
3.2 Timestamp /Watermark两种生成方式
只有基于EventTime的流处理程序需要指定Timestamp和Watermarks的生成方式。
指定时间特性为Event Time(前面讲过)。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
分配timestamp和生成Watermarks两种方式:
声明时间特性为Event Time后,Flink需要知道每个event的timestamp(一般从event的某个字段去抽取),Flink还需要知道目前event time的进度也就是Watermarks(一般伴随着Event Time一起指定生成方式,二者息息相关)
方式1:直接在source function中生成
方式2:timestamp assigner / watermark generator
注意:timestamp和watermark都是采用毫秒(从java的1970-01-01T00:00:00Z时间作为起始)。
声明:event、element、record都是一个意思。
3.3方式一、直接在source function中生成
自定义source实现SourceFunction接口或者继承RichParallelSourceFunction。

3.4方式二、 timestamp assigner / watermark generator
通过assignTimestampsAndWatermarks方法指定timestamp assigner / watermark generator
一般在datasource后调用assignTimestampsAndWatermarks,也可以在第一个基于event time的operator之前指定(例如window operator)。
特例:使用Kafka Connector作为source时,在source内部assignTimestampsAndWatermarks。

3.5两种Watermark
Periodic(周期性) Watermarks
1.基于Timer
2.ExecutionConfig.setAutoWatermarkInterval(msec) (默认是 200ms, 设置watermarker 发送的周期)。
3.实现AssignerWithPeriodicWatermarks 接口。
Puncuated(间断的) WaterMarks
1.基于某些事件触发watermark 的生成和发送(由用户代码实现,例如遇到特殊元素) 。
2.实现AssignerWithPeriodicWatermarks 接口。
3.6 Periodic Watermark
周期性调用getCurrentWatermark,如果获取的Watermark不等于null且比上一个最新的Watermark大就向下游发射。
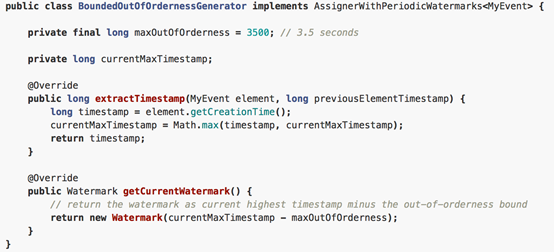
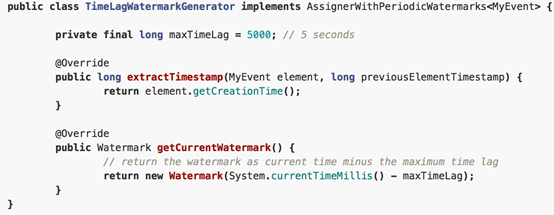
3.7 Puncuated Watermark
间断性调用getCurrentWatermark,它会根据一个条件发送watermark,这个条件可以自己去定义。
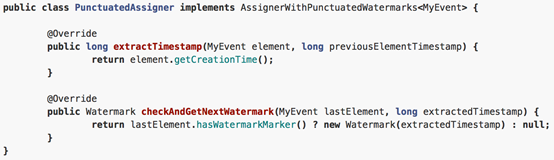
4. 预定义Timestamp Extractors / Watermark Emitters
4.1Assigners with ascending timestamps
适用于event时间戳单调递增的场景,数据没有太多延时。

4.2允许固定延迟的Assigner
适用于预先知道最大延迟的场景(例如最多比之前的元素延迟3000ms)。

4.3延迟数据处理
延时数据处理一般有两种处理方式:
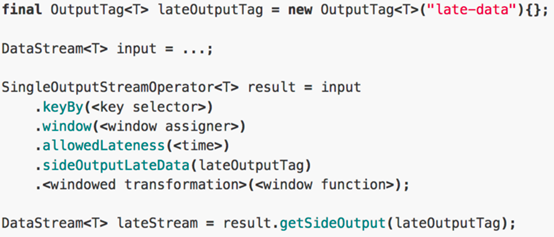
方式一:allowedLateness(),设定最大延迟时间,触发被延迟,不宜设置太长。
方式二: sideOutputTag ,提供了延迟数据获取的一种方式,这样就不会丢弃数据了。