1、大纲
-
了解 Apache Kafka是什么
-
掌握Apache Kafka的基本架构
-
搭建Kafka集群
-
掌握操作集群的两种方式
-
了解Apache Kafka高级部分的内容
2、消息系统的作用是什么?
消息系统最核心的功能有三个,分别是解耦、异步、并行。
下面我们通过用户注册的案例来说明消息系统的作用:
2.1、用户注册的一般流程
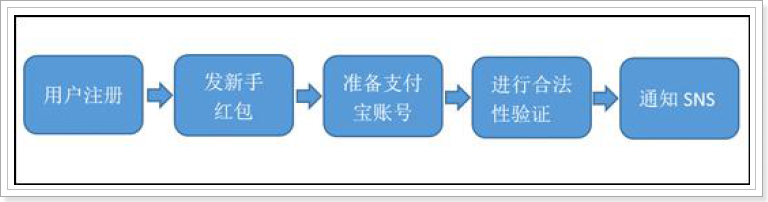

问题:随着后端流程越来越多,每步流程都需要额外的耗费很多时间,从而会导致用户更长的等待延迟。
2.2、改进成并行流程

问题:系统并行的发起了4 个请求,4 个请求中,如果某一个环节执行1 分钟,其他环节再快,用户也需要等待1 分钟。如果其中一个环节异常之后,整个服务挂掉了。
如何解决???
2.3、通过消息系统解决(异步架构)
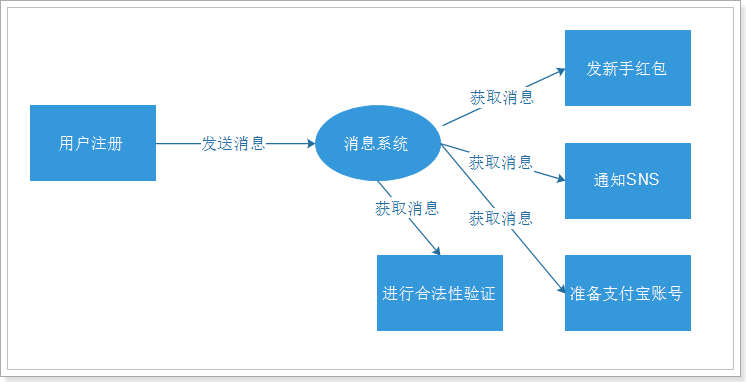

可见,通过消息架构解决了并行架构的问题。
3、了解 Apache Kafka
3.1、简介

-
Apache Kafka 是一个开源消息系统,由Scala 写成。是由Apache 软件基金会开发的一个开源消息系统项目。
-
Kafka 最初是由LinkedIn 开发,并于2011 年初开源。2012 年10 月从Apache Incubator 毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待(低延时)的平台。
-
Kafka 是一个分布式消息系统:具有生产者、消费者的功能。它提供了类似于JMS 的特性,但是在设计实现上完全不同,此外它并不是JMS 规范的实现。【重点】
3.2、kafka的基本结构

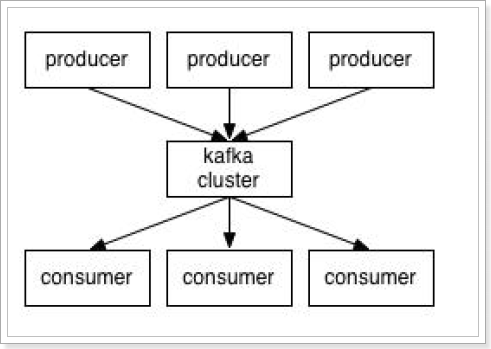
-
Producer:消息的发送者
-
Consumer:消息的接收者
-
kafka cluster:kafka的集群。
-
Topic:就是消息类别名,一个topic中通常放置一类消息。每个topic都有一个或者多个订阅者(消费者)。
消息的生产者将消息推送到kafka集群,消息的消费者从kafka集群中拉取消息。
3.3、kafka的完整架构

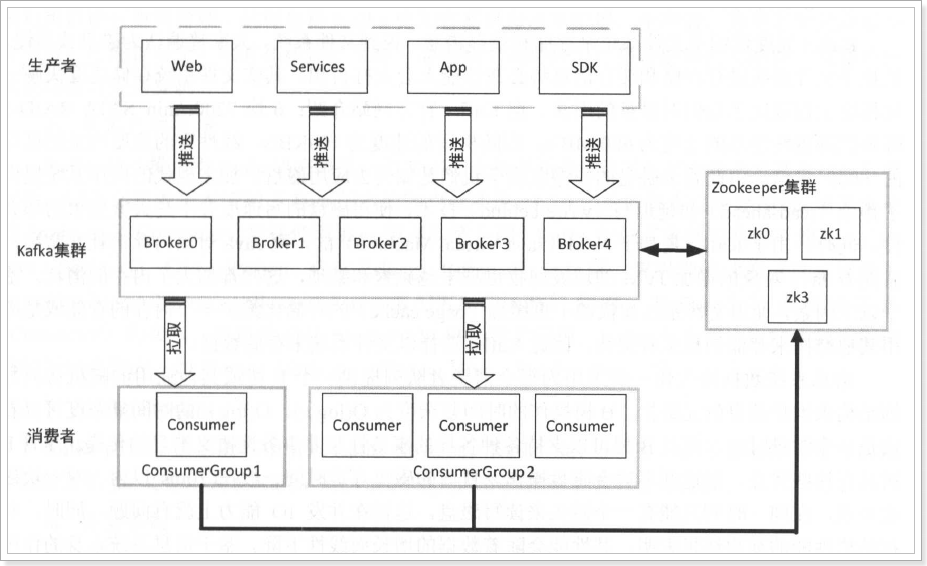
说明:
-
broker:集群中的每一个kafka实例,称之为broker;
-
ZooKeeper:Kafka 利用ZooKeeper 保存相应元数据信息, Kafka 元数据信息包括如代理节点信息、Kafka集群信息、旧版消费者信息及其消费偏移量信息、主题信息、分区状态信息、分区副本分配方案信息、动态配置信息等。
-
ConsumerGroup:在Kafka 中每一个消费者都属于一个特定消费组( ConsumerGroup ),我们可以为每个消费者指定一个消费组,以groupld 代表消费组名称,通过group.id 配置设置。如果不指定消费组,则该消费者属于默认消费组test-consumer-group 。
3.4、kafka的特性
-
消息持久化
-
Kafka 基于文件系统来存储和缓存消息。
-
-
高吞吐量
-
Kafka 将数据写到磁盘,充分利用磁盘的顺序读写。同时, Kafka 在数据写入及数据同步采用了零拷贝( zero-copy )技术,采用sendFile()函数调用,sendFile()函数是在两个文件描述符之间直接传递数据,完全在内核中操作,从而避免了内核缓冲区与用户缓冲区之间数据的拷贝,操作效率极高。
-
Kafka 还支持数据压缩及批量发送,同时Kafka 将每个主题划分为多个分区,这一系列的优化及实现方法使得Kafka 具有很高的吞吐量。经大多数公司对Kafka 应用的验证, Kafka 支持每秒数百万级别的消息。
-
-
高扩展性
-
Kafka 依赖ZooKeeper来对集群进行协调管理,这样使得Kafka 更加容易进行水平扩展,生产者、消费者和代理都为分布式,可配置多个。
-
同时在机器扩展时无需将整个集群停机,集群能够自动感知,重新进行负责均衡及数据复制。
-
-
多客户端支持
-
Kafka 核心模块用Scala 语言开发,Kafka 提供了多种开发语言的接入,如Java 、Scala、C 、C++、Python 、Go 、Erlang 、Ruby 、Node. 等。
-
-
安全机制
-
的Kafka 支持以下几种安全措施:
-
通过SSL 和SASL(Kerberos), SASL/PLA时验证机制支持生产者、消费者与broker连接时的身份认证;
-
支持代理与ZooKeeper 连接身份验证;
-
通信时数据加密;
-
客户端读、写权限认证;
-
Kafka 支持与外部其他认证授权服务的集成;
-
-
-
数据备份
-
Kafka 可以为每个topic指定副本数,对数据进行持久化备份,这可以一定程度上防止数据丢失,提高可用性。
-
-
轻量级
-
Kafka 的实例是无状态的,即broker不记录消息是否被消费,消费偏移量的管理交由消费者自己或组协调器来维护。
-
同时集群本身几乎不需要生产者和消费者的状态信息,这就使得Kafka非常轻量级,同时生产者和消费者客户端实现也非常轻量级。
-
-
消息压缩
-
Kafka 支持Gzip, Snappy 、LZ4 这3 种压缩方式,通常把多条消息放在一起组成MessageSet,然后再把Message Set 放到一条消息里面去,从而提高压缩比率进而提高吞吐量。
-
3.5、kafka的应用场景
-
消息系统。
-
Kafka 作为一款优秀的消息系统,具有高吞吐量、内置的分区、备份冗余分布式等特点,为大规模消息处理提供了一种很好的解决方案。
-
-
应用监控。
-
利用Kafka 采集应用程序和服务器健康相关的指标,如CPU 占用率、IO 、内存、连接数、TPS 、QPS 等,然后将指标信息进行处理,从而构建一个具有监控仪表盘、曲线图等可视化监控系统。例如,很多公司采用Kafka 与ELK (Elastic Search 、Logstash 和Kibana)整合构建应用服务监控系统。
-
-
网站用户行为追踪。
-
为了更好地了解用户行为、操作习惯,改善用户体验,进而对产品升级改进,将用户操作轨迹、内容等信息发送到Kafka 集群上,通过Hadoop 、Spark 或Strom等进行数据分析处理,生成相应的统计报告,为推荐系统推荐对象建模提供数据源,进而为每个用户进行个性化推荐。
-
-
流处理。
-
需要将己收集的流数据提供给其他流式计算框架进行处理,用Kafka 收集流数据是一个不错的选择。
-
-
持久性日志。
-
Kafka 可以为外部系统提供一种持久性日志的分布式系统。日志可以在多个节点间进行备份, Kafka 为故障节点数据恢复提供了一种重新同步的机制。同时, Kafka很方便与HDFS 和Flume 进行整合,这样就方便将Kafka 采集的数据持久化到其他外部系统。
-
4、Kafka的安装与配置
准备三台虚拟机,分别是node01,node02,node03,并且修改hosts文件如下:
vim /etc/hosts
#注意: 前面的ip地址改成自己的ip地址
192.168.40.133 node01
192.168.40.134 node02
192.168.40.135 node03
#3台服务器的时间要一致
#时间更新:
yum install -y rdate
rdate -s time-b.nist.gov
4.1、基础环境配置
4.1.1、JDK环境
由于Kafka 是用Scala 语言开发的,运行在JVM上,因此在安装Kafka 之前需要先安装JDK 。
安装过程略过,我这里使用的是jdk1.8。

4.1.2、ZooKeeper环境
4.1.2.1、安装ZooKeeper
Kafka 依赖ZooKeeper ,通过ZooKeeper 来对服务节点、消费者上下线管理、集群、分区元数据管理等,因此ZooKeeper 也是Kafka 得以运行的基础环境之一。
#上传zookeeper-3.4.9.tar.gz到/export/software
cd /export/software
mkdir -p /export/servers/
tar -xvf zookeeper-3.4.9.tar.gz -C /export/servers/
#创建ZooKeeper的data目录
mkdir /export/data/zookeeper -p
cd /export/servers/zookeeper-3.4.9/conf/
#修改配置文件
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg
#设置data目录
dataDir=/export/data/zookeeper
#启动ZooKeeper
./zkServer.sh start
#检查是否启动成功
jps
4.1.2.3、搭建ZooKeeper集群
#在/export/data/zookeeper目录中创建myid文件
vim /export/data/zookeeper/myid
#写入对应的节点的id,如:1,2等,保存退出
#在conf下,修改zoo.cfg文件
vim zoo.cfg
#添加如下内容
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
4.1.2.3、配置环境变量
vim /etc/profile
export ZK_HOME=/export/servers/zookeeper-3.4.9
export PATH=${ZK_HOME}/bin:$PATH
#立即生效
source /etc/profile
4.1.2.4、分发到其它机器
scp /etc/profile node02:/etc/
scp /etc/profile node03:/etc/
cd /export/servers
scp -r zookeeper-3.4.9 node02:/export/servers/
scp -r zookeeper-3.4.9 node03:/export/servers/
4.1.2.5、一键启动、停止脚本
mkdir -p /export/servers/onekey/zk
vim slave
#输入如下内容
node01
node02
node03
#保存退出
vim startzk.sh
#输入如下内容
cat /export/servers/onekey/zk/slave | while read line
do
{
echo "开始启动 --> "$line
ssh $line "source /etc/profile;nohup sh ${ZK_HOME}/bin/zkServer.sh start >/dev/null 2>&1 &"
}&
wait
done
echo "★★★启动完成★★★"
#保存退出
vim stopzk.sh
#输入如下内容
cat /export/servers/onekey/zk/slave | while read line
do
{
echo "开始停止 --> "$line
ssh $line "source /etc/profile;nohup sh ${ZK_HOME}/bin/zkServer.sh stop >/dev/null 2>&1 &"
}&
wait
done
echo "★★★停止完成★★★"
#保存退出
#设置可执行权限
chmod +x startzk.sh stopzk.sh
#添加到环境变量中
export ZK_ONEKEY=/export/servers/onekey
export PATH=${ZK_ONEKEY}/zk:$PATH
4.1.2.6、检查启动是否成功

发现三台机器都有“QuorumPeerMain”进程,说明机器已经启动成功了。
检查集群是否正常:
zkServer.sh status



发现,集群运行一切正常。
4.2、安装Kafka
4.2.1、单机版Kafka安装
第一步:上传Kafka安装包并且解压
rz 上传kafka_2.11-1.1.0.tgz到 /export/software/
cd /export/software/
tar -xvf kafka_2.11-1.1.0.tgz -C /export/servers/
cd /export/servers
mv kafka_2.11-1.1.0/ kafka
第二步:配置环境变量
vim /etc/profile
#输入如下内容
export KAFKA_HOME=/export/servers/kafka
export PATH=${KAFKA_HOME}/bin:$PATH
#保存退出
source /etc/profile
第三步:修改配置文件
cd /export/servers/kafka
cd config
vim server.properties
# The id of the broker. This must be set to a unique integer for each broker.
# 必须要只要一个brokerid,并且它必须是唯一的。
broker.id=0
# A comma separated list of directories under which to store log files
# 日志数据文件存储的路径 (如不存在,需要手动创建该目录, mkdir -p /export/data/kafka/)
log.dirs=/export/data/kafka
# ZooKeeper的配置,本地模式下指向到本地的ZooKeeper服务即可
zookeeper.connect=node01:2181
# 保存退出
第四步:启动kafka服务
# 以守护进程的方式启动kafka
kafka-server-start.sh -daemon /export/servers/kafka/config/server.properties
第五步:检测kafka是否启动

如果进程中有名为kafka的进程,就说明kafka已经启动了。
4.2.2、验证kafka是否安装成功
由于kafka是将元数据保存在ZooKeeper中的,所以,可以通过查看ZooKeeper中的信息进行验证kafka是否安装成功。



4.2.3、部署kafka-manager
Kafka Manager 由 yahoo 公司开发,该工具可以方便查看集群 主题分布情况,同时支持对 多个集群的管理、分区平衡以及创建主题等操作。
源码托管于github:https://github.com/yahoo/kafka-manager
第一步:上传Kafka-manager安装包并且解压
rz上传kafka-manager-1.3.3.17.tar.gz到 /export/software/
cd /export/software
tar -xvf kafka-manager-1.3.3.17.tar.gz -C /export/servers/
cd /export/servers/kafka-manager-1.3.3.17/conf
第二步:修改配置文件
#修改配置文件
vim application.conf
#新增项,http访问服务的端口
http.port=19000
#修改成自己的zk机器地址和端口
kafka-manager.zkhosts="node01:2181"
#保存退出
第三步:启动服务
cd /export/servers/kafka-manager-1.3.3.17/bin
#启动服务
./kafka-manager -Dconfig.file=../conf/application.conf
#制作启动脚本
vim /etc/profile
export KAFKA_MANAGE_HOME=/export/servers/kafka-manager-1.3.3.17
export PATH=${KAFKA_MANAGE_HOME}/bin:$PATH
source /etc/profile
cd /export/servers/onekey/
mkdir kafka-manager
cd kafka-manager
vim start-kafka-manager.sh
nohup kafka-manager -Dconfig.file=${KAFKA_MANAGE_HOME}/conf/application.conf >/dev/null 2>&1 &
chmod +x start-kafka-manager.sh
vim /etc/profile
export PATH=${ZK_ONEKEY}/kafka-manager:$PATH
source /etc/profile
第四步:检查是否启动成功
打开浏览器,输入地址:http://node01:19000/,即可看到kafka-manage管理界面。

4.2.4、kafka-manager的使用
进入管理界面,是没有显示Cluster信息的,需要添加后才能操作。
-
添加 Cluster:

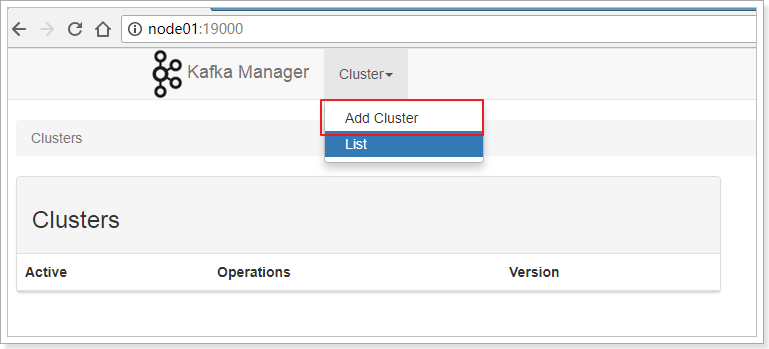
输入Cluster Name、ZooKeeper信息、以及Kafka的版本信息(这里最高只能选择1.0.0)。

点击Save按钮保存。

添加成功。
-
查看kafka的信息

-
查看Broker信息

-
查看Topic列表

-
查看单个topic信息以及操作

-
优化副本选举

-
查看消费者信息

4.2.5、搭建kafka集群
kafka集群的搭建是非常简单的,只需要将上面的单机版的kafka分发的其他机器,并且将ZooKeeper信息修改成集群的配置以及设置不同的broker值即可。
第一步:将kafka分发到node02、node03
cd /export/servers/
scp -r kafka node02:/export/servers/
scp -r kafka node03:/export/servers/
scp /etc/profile node02:/etc/
scp /etc/profile node03:/etc/
# 分别到node02、node03机器上执行
source /etc/profile
第二步:修改node01、node02、node03上的kafka配置文件
-
node01:
cd /export/servers/kafka/config
vim server.properties
zookeeper.connect=node01:2181,node02:2181,node03:2181 -
node02:
cd /export/servers/kafka/config
vim server.properties
broker.id=1
zookeeper.connect=node01:2181,node02:2181,node03:2181 -
node03:
cd /export/servers/kafka/config
vim server.properties
broker.id=2
zookeeper.connect=node01:2181,node02:2181,node03:2181
第三步:编写一键启动、停止脚本。注意:该脚本依赖于环境变量中的KAFKA_HOME。
mkdir -p /export/servers/onekey/kafka
vim slave
#输入如下内容
node01
node02
node03
#保存退出
vim start-kafka.sh
#输入如下内容
cat /export/servers/onekey/kafka/slave | while read line
do
{
echo "开始启动 --> "$line
ssh $line "source /etc/profile;nohup sh ${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties >/dev/null 2>&1 &"
}&
wait
done
echo "★★★启动完成★★★"
#保存退出
chmod +x start-kafka.sh
vim stop-kafka.sh
#输入如下内容
cat /export/servers/onekey/kafka/slave | while read line
do
{
echo "开始停止 --> "$line
ssh $line "source /etc/profile;nohup sh ${KAFKA_HOME}/bin/kafka-server-stop.sh >/dev/null 2>&1 &"
}&
wait
done
echo "★★★停止完成★★★"
#保存退出
chmod +x stop-kafka.sh
#加入到环境变量中
export PATH=${ZK_ONEKEY}/kafka:$PATH
source /etc/profile
第四步:通过kafka-manager管理工具查看集群信息。 
由此可见,kafka集群已经启动完成。
5、Kafka快速入门
对kafka的操作有2种方式,一种是通过命令行方式,一种是通过API方式。
5.1、通过命令行Kafka
Kafka在bin目录下提供了shell脚本文件,可以对Kafka进行操作,分别是: 
通过命令行的方式,我们将体验下kafka,以便我们对kafka有进一步的认知。
5.1.1、topic的操作
5.1.1.1、创建topic
kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 1 --partitions 1 --topic my-kafka-topic
#执行结果:
Created topic "my-kafka-topic".
参数说明:
-
zookeeper:参数是必传参数,用于配置 Kafka 集群与 ZooKeeper 连接地址。至少写一个。
-
partitions:参数用于设置主题分区数,该配置为必传参数。
-
replication-factor:参数用来设置主题副本数 ,该配置也是必传参数。
-
topic:指定topic的名称。
5.1.1.2、查看topic列表
kafka-topics.sh --list --zookeeper node01:2181
__consumer_offsets
my-kafka-topic
可以查看列表。
如果需要查看topic的详细信息,需要使用describe命令。
kafka-topics.sh --describe --zookeeper node01:2181 --topic test-topic
#若不指定topic,则查看所有topic的信息
kafka-topics.sh --describe --zookeeper node01:2181
5.1.1.3、删除topic
通过kafka-topics.sh执行删除动作,需要在server.properties文件中配置 delete.topic.enable=true,该配置默认为 false。
否则执行该脚本并未真正删除主题 ,将该topic标记为删除状态 。
kafka-topics.sh --delete --zookeeper node01:2181 --topic my-kafka-topic
# 执行如下
[root@node01 config]# kafka-topics.sh --delete --zookeeper node01:2181 --topic my-kafka-topic
Topic my-kafka-topic is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
# 如果将delete.topic.enable=true
[root@node01 config]# kafka-topics.sh --delete --zookeeper node01:2181 --topic my-kafka-topic2
Topic my-kafka-topic2 is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
# 说明:虽然设置后,删除时依然提示没有设置为true,实际上已经删除了。
5.1.2、生产者的操作
kafka-console-producer.sh --broker-list node01:9092 --topic my-kafka-topic

可以看到,已经向topic发送了消息。
5.1.3、消费者的操作
kafka-console-consumer.sh --bootstrap-server node01:9092 --topic my-kafka-topic
# 通过以上命令,可以看到消费者可以接收生产者发送的消息
# 如果需要从头开始接收数据,需要添加--from-beginning参数
kafka-console-consumer.sh --bootstrap-server node01:9092 --from-beginning --topic my-kafka-topic

5.2、通过Java Api操作Kafka
除了通过命令行的方式操作kafka外,还可以通过Java api的方式操作,这种方式将更加的常用。
5.2.1、创建工程

导入依赖:
5.2.2、topic的操作
由于主题的元数据信息是注册在 ZooKeeper 相 应节点之中,所以对主题的操作实质是对 ZooKeeper 中记录主题元数据信息相关路径的操作。 Kafka将对 ZooKeeper 的相关操作封装成一 个 ZkUtils 类 , 井封装了一个AdrninUtils 类调用 ZkClient 类的相关方法以实现对 Kafka 元数据 的操作,包括对主题、代理、消费者等相关元数据的操作。对主题操作的相关 API调用较简单, 相应操作都是通过调用 AdminUtils类的相应方法来完成的。
package cn. .kafka;
import kafka.admin.AdminUtils;
import kafka.utils.ZkUtils;
import org.apache.kafka.common.security.JaasUtils;
import org.junit.Test;
import java.util.Properties;
public class TestKafkaTopic {
测试结果:

5.2.2.1、删除topic
测试结果:

5.2.3、生产者的操作
package cn. .kafka;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.Test;
import java.util.Properties;
public class TestProducer {
5.2.4、消费者的操作
package cn. .kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.Test;
import javax.sound.midi.Soundbank;
import java.util.Arrays;
import java.util.Properties;
public class TestConsumer {
6、Kafka高级
6.1、生产者的同步和异步模式

-
异步方式:两个 send 方法都返回一个 Future<RecordMetadata>对象,即只负责将消息 发送到消息缓冲区,并不等待 Sender线程处理结果,若希望了解异步方式消息发送成功与否 ,可以在回调函数中进行相应处理, 当消息被 Sender线程处理后会回调 Callback。
-
同步方式:通过调用 send方法返回的 Future对象的 get()方法以阻塞式获取执行结果, 即等待 Sender线程处理的最终结果。
-
默认采用的异步方式。
6.1.1、异步实现
package cn. .kafka;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.Test;
import java.util.Properties;
public class TestAsyncProducer {
测试的结果:
发送消息 --> 0 发送消息 --> 1 发送消息 --> 2 发送消息 --> 3 发送消息 --> 4 发送消息 --> 5 发送消息 --> 6 发送消息 --> 7 发送消息 --> 8 发送消息 --> 9 消息的callbakc --> my-kafka-topic-0@-1 消息的callbakc --> my-kafka-topic-0@-1 消息的callbakc --> my-kafka-topic-0@-1 消息的callbakc --> my-kafka-topic-0@-1 消息的callbakc --> my-kafka-topic-0@-1 消息的callbakc --> my-kafka-topic-0@-1 消息的callbakc --> my-kafka-topic-0@-1 消息的callbakc --> my-kafka-topic-0@-1 消息的callbakc --> my-kafka-topic-0@-1 消息的callbakc --> my-kafka-topic-0@-1 Process finished with exit code 0
6.1.2、同步实现
package cn. .kafka;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.Test;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
public class TestSyncProducer {
测试:
消息的callbakc --> my-kafka-topic-0@3128 发送消息 --> 0 消息的callbakc --> my-kafka-topic-0@3129 发送消息 --> 1 消息的callbakc --> my-kafka-topic-0@3130 发送消息 --> 2 消息的callbakc --> my-kafka-topic-0@3131 发送消息 --> 3 消息的callbakc --> my-kafka-topic-0@3132 发送消息 --> 4 消息的callbakc --> my-kafka-topic-0@3133 发送消息 --> 5 消息的callbakc --> my-kafka-topic-0@3134 发送消息 --> 6 消息的callbakc --> my-kafka-topic-0@3135 发送消息 --> 7 消息的callbakc --> my-kafka-topic-0@3136 发送消息 --> 8 消息的callbakc --> my-kafka-topic-0@3137 发送消息 --> 9 Process finished with exit code 0
6.2、消费者组
在 Kafka 中每一个消费者都属于一个特定消费组( ConsumerGroup),我们可以为每个消费者指定一个消费组,以 groupld 代表消费组名称,通过 group.id 配置设置 。 如果不指定消费组,则 该消费者属于默 认消费组 test-consumer-group。
需要重点说明的是:
-
同一个主题的一条消息只能同一个消费者组下的某一个消费者消费。
-
不同消费组的消费者可同时消费该消息。
6.2.1、测试:同一个消息只能为同组的一个消费者消费
消费者1: my-client-1
package cn. .kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.Test;
import org.springframework.kafka.listener.MessageListener;
import javax.sound.midi.Soundbank;
import java.util.Arrays;
import java.util.Properties;
public class TestConsumer {
消费者2:my-client-2
package cn. .kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.junit.Test;
import java.util.Arrays;
import java.util.Properties;
public class TestConsumer2 {
测试:
分别启动消费者1和消费者2,然后在控制台输入消息,观察消费者1和消费者2的控制台打印情况。



6.2.2、测试:不同组的消费可以获取相同的数据
消费者1:my-client-11在my-group-test-3组中
package cn. .kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.Test;
import org.springframework.kafka.listener.MessageListener;
import javax.sound.midi.Soundbank;
import java.util.Arrays;
import java.util.Properties;
public class TestConsumer {
消费者2:my-client-22在my-group-test-4组中
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.junit.Test;
import java.util.Arrays;
import java.util.Properties;
public class TestConsumer2 {
测试:


由此可见,2个消费者获取到的消息是一样的。
6.2.3、总结
消费组是 Kafka 用来实现对一个主题消息进行广播和单播的手段,实现消息广播只需指定各消费者均属于不同的消费组,消息单播则只 需让各消费者属于同 一个消费组 。
6.3、分区和副本
6.3.1、分区
6.3.1.1、什么是分区?

-
创建topic时,如果不指定分区,那么,topic的数据只是在一个broker中存储。
-
问题:如果一台机器存储不下怎么办?
-
-
创建topic时,可以指定分区,将一个topic的数据分散存储到多个broker,实现分区存储,从而解决一个机器存储不下的问题,也就实现了存储的横向扩展。
6.3.1.2、如何设置分区?
第一种:通过脚本创建topic时指定
kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 1 --partitions 3 --topic my-kafka-topic-3

第二种:在通过java api创建topic时指定
//参数:zkUtils,topic名称,partition数量,副本数量,参数,机架感知模式
AdminUtils.createTopic(zkUtils, topicName, 3, 1, new Properties(), AdminUtils.createTopic$default$6());
6.3.1.3、分区和消费者的关系(负载均衡机制)

说明:
-
同一个partition的数据可以被不同的消费组获取。
-
同一个组内的消费者不能同时消费同一个partition。
-
同一个组内的消费者可以消费不同的partition,也就是说,同一个组内的消费者数 小于等于 partition数,不能大于。
-
如果同组内的消费者数大于partition数,那么一定会有消费者是空闲的。
-
6.3.2、副本
6.3.2.1、什么是副本?

-
创建topic时,如果不指定副本,那么一个partition只会在一个Broker中存储
-
问题:如果该机器宕机,那么topic的数据将丢失。
-
-
创建topic时,如果设置副本,那么kafka将在其他分区中保存该分区的数据,已确保数据的可靠性。
-
在多个副本中,kafka会选取一个作为leader提供服务。其它的作为Follower节点存在。
6.3.2.2、如何设置副本?
第一种:通过脚本创建topic时指定
kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 3 --partitions 3 --topic my-kafka-topic-4


第二种:在通过java api创建topic时指定
//参数:zkUtils,topic名称,partition数量,副本数量,参数,机架感知模式
AdminUtils.createTopic(zkUtils, topicName, 3, 3, new Properties(), AdminUtils.createTopic$default$6());
6.3.2.3、副本之间数据同步是否会丢失数据?
消息的生产者将消息发送到leader,Follower会进行同步消息,如果消息还未同步完成,leader宕机,消息会丢失吗?
其实, Kafka为生产者提供3种消息确认机制(acks),分别是,0,-1,1,默认为:1。
( 1) 当 acks=0时,生产者不用等待代理返回确认信息,而连续发送消息。显然这种 方式加快了消息投递的速度,然而无法保证消息是否己被代理接受 ,有可能存在丢失数据 的风险。
(2)当 acsk=1时,生产者需要等待 Leader 己成功将消息写入日志文件中。这种方式 在一定程度上降低了数据丢失的可能性,但仍无法保证数据一定不会丢失。如果在 Leader副本 成功存储数据后, Follower 副本还没有来得及进行同步,而此时 Leader 着机了,那么此时虽 然数据己进行了存储,由于原来的 Leader 己不可用而会从集群中下线,同时存活的代理又再也不会有从原来的 Leader副本存储的数据,此时数据就会丢失。
(3)当 acks=-1 时, Leader副本和所有 ISR列表中的副本都完成数据存储时才会向生产者 发送确认信息,这种策略保证只要 Leader 副本和 Follower 副本中至少有一个节点存活,数据就 不会丢失。为了保证数据不丢失,需要保证同步的副本至少大于1,通过参数 min.insync.replicas 设置,当同步副本数不足此配置值时,生产者会抛出异常,但这种方式同时也影响了生产者发 送消息的速度以及吞吐量。
6.4、消费者如何保证消息不丢失?
在kafka0.8.2版本之后,消费者将消费记录(offset)值,保存在名为__consumer_offsets的topic中。
所以,只要能够正确记录offset值,就能保证消息不丢失,但是有可能消息会重复消费。

6.5、Kafka的文件存储机制
6.5.1、Kafka 文件存储基本结构
-
在Kafka 文件存储中,同一个topic 下有多个不同partition,每个partition 为一个目录,partiton命名规则为topic 名称+有序序号,第一个partiton 序号从0 开始,序号最大值为partitions数量减1。
-
每个partion(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file 消息数量不一定相等,这种特性方便old segment file 快速被删除。默认保留7 天的数据。


6.5.2、Segment文件
-
Segment file 组成:由3大部分组成,分别为index file 、data file、timeindex file,此3个文件一一对应,分别表示为segment 索引文件、数据文件、时间日志。
-
当log文件等于1G时,新的会写入到下一个segment中。

-
Segment 文件命名规则:partion 全局的第一个segment 从0 开始,后续每个segment文件名为上一个segment 文件最后一条消息的offset 值。数值最大为64 位long 大小,19 位数字字符长度,没有数字用0 填充。
-
索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message 的物理偏移地址。

上述图中索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中message 的物理偏移地址。其中以索引文件中元数据3,497 为例,依次在数据文件中表示第3 个message(在全局partiton表示第368772 个message)、以及该消息的物理偏移地址为497。
6.5.3、Kafka 查找message

如果需要读取offset=368776 的message,如何查找?
6.5.3.1、查找segment file
00000000000000000000.index 表示最开始的文件,起始偏移量(offset)为000000000000000368769.index 的消息量起始偏移量为368770 = 368769 + 100000000000000737337.index 的起始偏移量为737338=737337 + 1其他后续文件依次类推。以起始偏移量命名并排序这些文件,只要根据offset 二分查找文件列表,就可以快速定位到具体文件。当offset=368776 时定位到00000000000000368769.index 和对应log 文件。
6.5.3.2、通过segment file 查找message
当offset=368776 时, 依次定位到00000000000000368769.index 的元数据物理位置和00000000000000368769.log 的物理偏移地址,然后再通过00000000000000368769.log 顺序查找直到offset=368776 为止。
6.5.4、思考?
kafka为什么要将数据进行分段存储,好处是什么?
-
读写数据速度快
-
小文件一定比大文件快
-
-
对于旧数据,清除起来方便
6.6、生产者数据分发策略

kafka在数据生产的时候,有一个数据分发策略。默认的情况使用DefaultPartitioner.class类。
分发策略有三种:
-
如果是用户指定了partition,生产就不会调用DefaultPartitioner.partition()方法
-
当用户指定key,使用hash算法。Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions
-
如果key一直不变,同一个key算出来的hash值是个固定值。
-
如果是固定值,这种hash取模就没有意义。
-
-
当用既没有指定partition也没有key,就采用轮询算法。
源码:
public class KafkaProducer<K, V> implements Producer<K, V> {
。。。。。。。
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
return partition != null ?
partition :
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
DefaultPartitioner.java文件:
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
// 轮询算法
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition hash算法
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}