RPC 框架
- Dubbo「通讯基于 netty,有界面化操作 dubbo-admin」
- OpenFeign「通讯基于 HttpClient」
注册中心
- zookeeper「需要另外部署 zookeeper 服务」
- Eureka「集成在系统里面,不需要另外部署服务」
负载均衡
- Ribbon「客户端技术」
- Nginx「服务端技术,多一次 io,配置让运维崩溃」
限流
- Sentinel「阿里开源,界面化操作」
消息队列
- RocketMQ
- RabbitMQ
RPC 解决的问题
解决了跨应用的服务之间的调用问题,能够做到调用远程的服务就和调用本地服务一样的便捷。
RPC 需要实现的功能:
- 寻址问题:像本地方法一样调用远程的方法,使用对象调用方法,rpc 需要将其转换为远程服务的接口;
- 序列化和反序列化:需要将入参和出参进行序列化和反序列化;
- 通讯协议:保证调用过程的可靠性;
注册中心解决的问题
为 RPC 调用提供了可靠的服务清单。
注册中心应该实现的功能:
- 服务注册表:用来记录各个微服务的信息,例如微服务的名称、IP、端口等。服务注册表提供查询API和管理API,查询API用于查询可用的微服务实例,管理API用于服务的注册与注销。
- 服务注册与发现:服务注册是指微服务在启动时,将自己的信息注册到注册中心的过程。服务发现是指查询可用的微服务列表及网络地址的机制。
- 服务检查:注册中心使用一定的机制定时检测已注册的服务,如发现某实例长时间无法访问,就会从服务注册表移除该实例。
负载均衡解决的问题
在可靠的服务清单里面,更好的调用每一个服务,不会因为某个服务访问量过高而导致服务服务不可用。
限流解决的问题
防止出现接口访问量超过最大值,导致接口不可用,继而出现连锁反应,出现服务雪崩,导致整个应用不可用。
限流解决需要实现的功能
- 在超过阈值时自动关闭服务
- 在低于阈值时自动开启服务「或者半开」
sentinel 流控效果
- 快速失败(直接抛出异常)
- 预热(warmUp)
- 排队等待
Dubbo
面向接口编程
ServiceLoader
性能高的原因:
1. 去中心化的注册中心,直接点对点的调用;
2. 通讯协议相比 http 要轻量,所以更加高效;
- 服务发现:用于服务的注册与发现,目的是让消费方找到提供方;
- 服务治理:用于治理服务间的关系,或为开发测试提供便利条件;
- 性能调优:用于调优性能,不同的选项对性能会产生影响。
1. dubbo 配置项

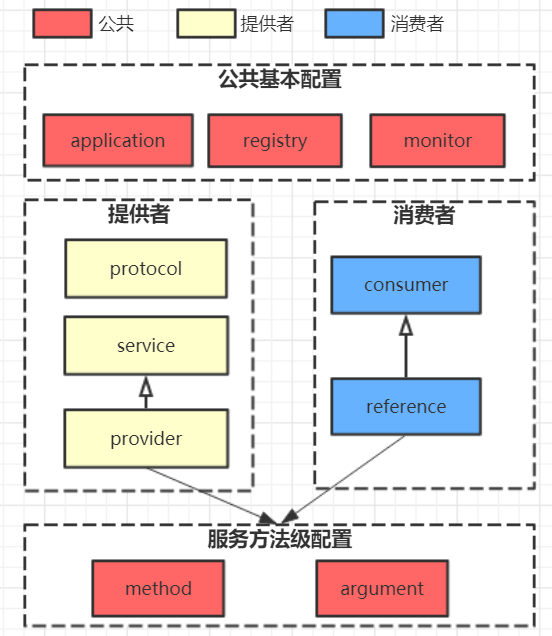
2. 支持的协议
Dubbo 支持 dubbo、rmi、hessian、http、webservice、thrift、redis 等多种协议,但是 Dubbo官网是推荐我们使用 dubbo 协议。
3. 支持的负载均衡
- 随机(默认):随机来;
- 轮询:一个一个来;
- 活跃度:机器活跃度来负载;
- 一致性 hash:同样的 Hash 值就会落到同一台机器上;
4. Dubbo 默认使用什么序列化框架,你知道的还有哪些?
默认使用 Hessian 序列化,还有 Duddo、FastJson、Java 自带序列化。hessian是一个采用二进制格式传输的服务框架,相对传统soap web service,更轻量,更快速。
- Hessian 序列化:hessian中 client 与 server 的交互,基于 http-post 方式。hessian 将辅助信息,封装在 http header 中,比如“授权 token”等,我们可以基于 http-header 来封装关于“安全校验”、“meta 数据”等。hessian提供了简单的“校验”机制。
5. Dubbo 有哪些容错策略?「6 种」
- 重试「failover cluster」:provider 宕机重试以后,请求会分到其他的 provider 上,默认两次,可以手动设置重试次数,建议把写操作重试次数设置成 0;
- 失败返回「failback」 :失败自动恢复会在调用失败后,返回一个空结果给服务消费者。并通过定时任务对失败的调用进行重试,适合执行消息通知等操作。
- 快速失败「failfast cluster 」:快速失败只会进行一次调用,失败后立即抛出异常。适用于幂等操作、写操作,类似于 failover cluster 模式中重试次数设置为 0 的情况。
- 安全失败「failsafe cluster」:失败安全是指,当调用过程中出现异常时,仅会打印异常,而不会抛出异常。适用于写入审计日志等操作。
- 并行调用「forking cluster」:并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。
- 广播调用「broadcacst cluster」:广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
6. Dubbo 动态代理策略有哪些?
默认使用 javassist 动态字节码生成,创建代理类,但是可以通过 SPI 扩展机制配置自己的动态代理策略。
7. 服务提供者没挂,但在注册中心里看不到,怎么办?
首先,确认服务提供者是否连接了正确的注册中心,不只是检查配置中的注册中心地址,而且要检查实际的网络连接。
其次,看服务提供者是否非常繁忙,比如压力测试,以至于没有CPU片段向注册中心发送心跳,这种情况减小压力将自动恢复。
8. dubbo 服务请求流程
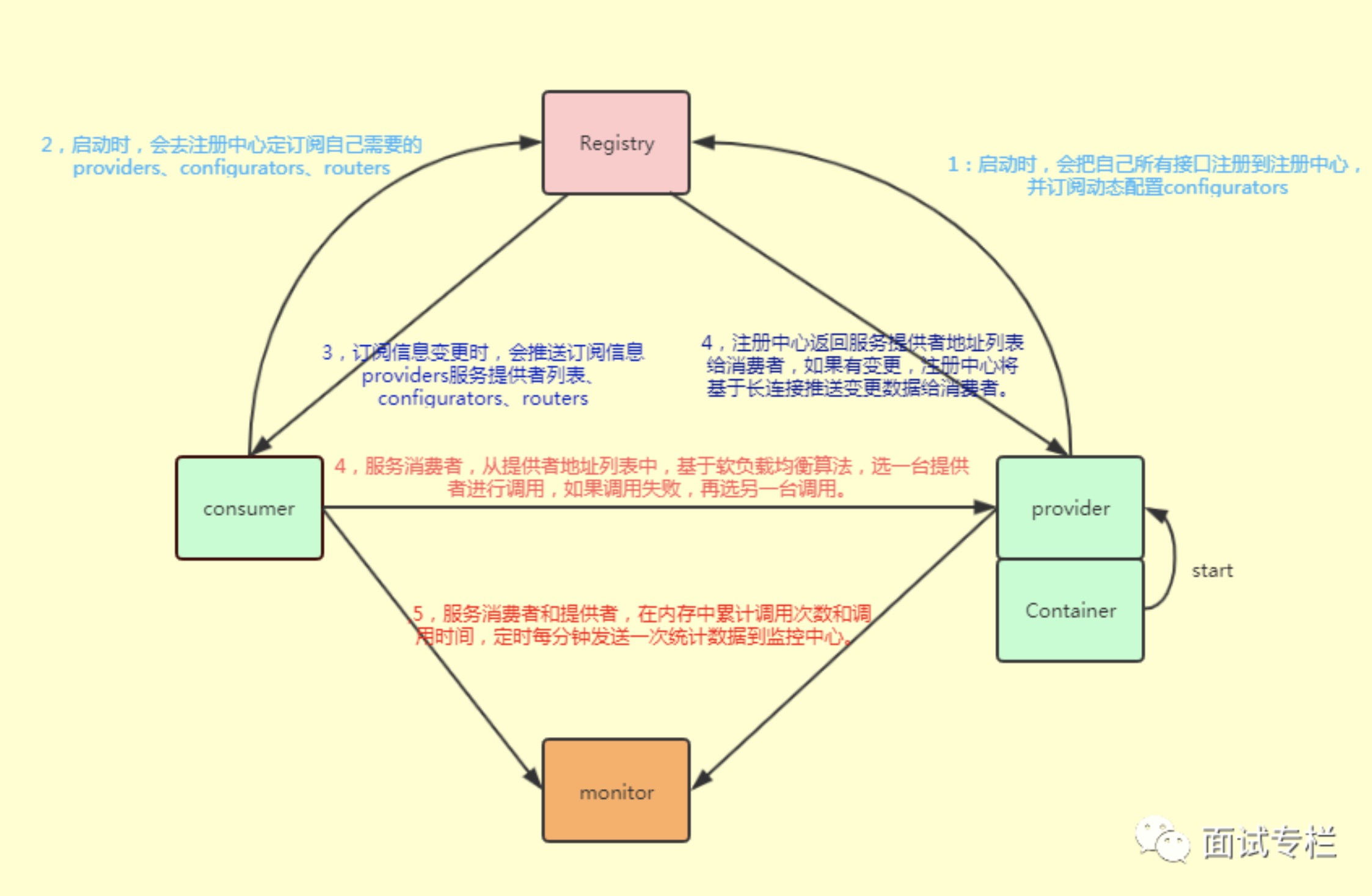
上图中各部分的含义
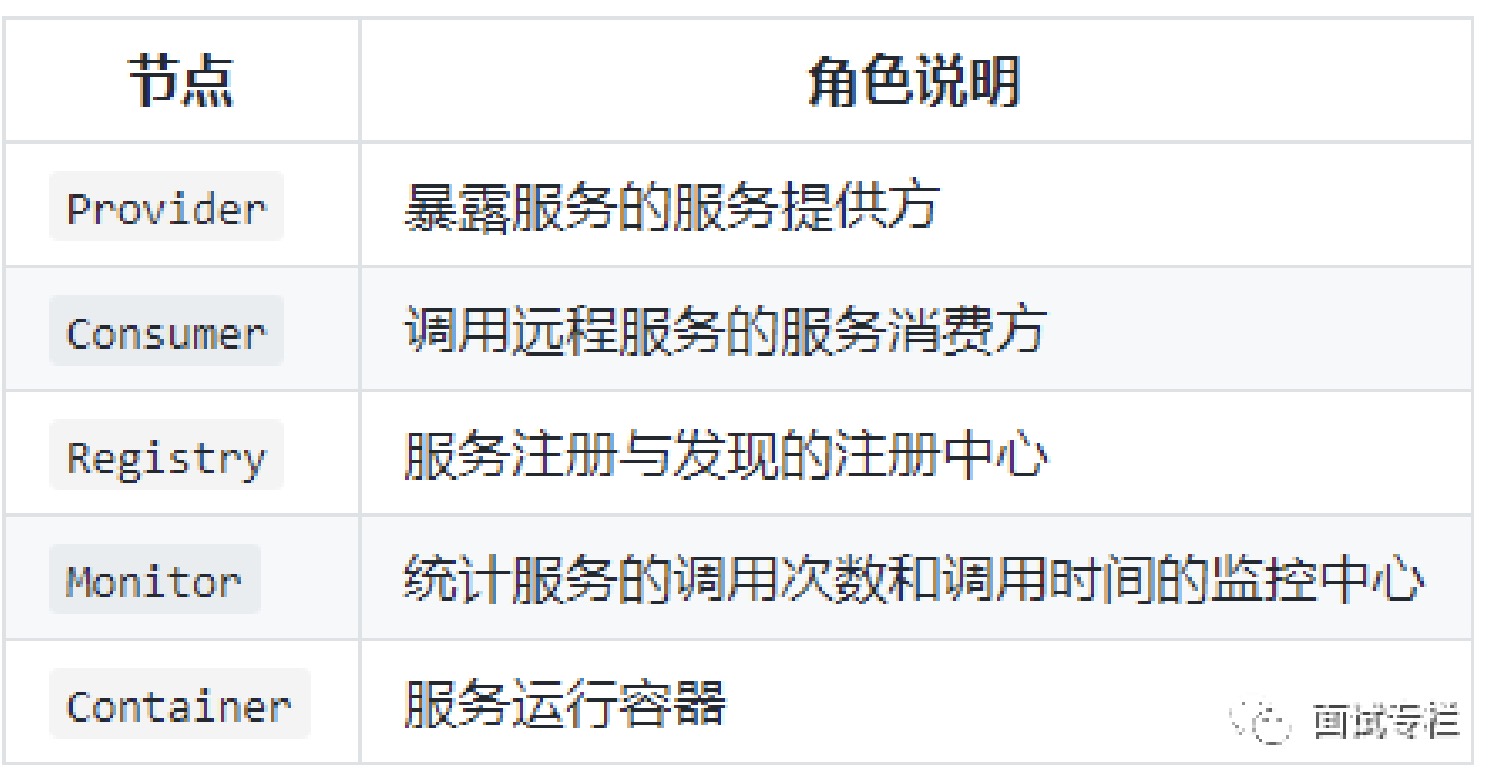
9. Dubbo 的整体架构设计有哪些分层?「10 层」
- service:接口层,给服务提供者和消费者来实现的(留给开发人员来实现);
- config:配置层,主要是对 Dubbo 进行各种配置的,Dubbo 相关配置;
- proxy:服务代理层,透明生成客户端的 stub 和服务端的 skeleton,调用的是接
口,实现类没有,所以得生成代理,代理之间再进行网络通讯、负责均衡等;- registry:服务注册层,负责服务的注册与发现;
- cluster:集群层,封装多个服务提供者的路由以及负载均衡,将多个实例组合成一 个服务;
- monitor:监控层,对 rpc 接口的调用次数和调用时间进行监控;
- protocol:远程调用层,封装 rpc 调用;
- exchange:信息交换层,封装请求响应模式,同步转异步;
- transport:网络传输层,抽象 mina 和 netty 为统一接口;
- serialize:数据序列化层。
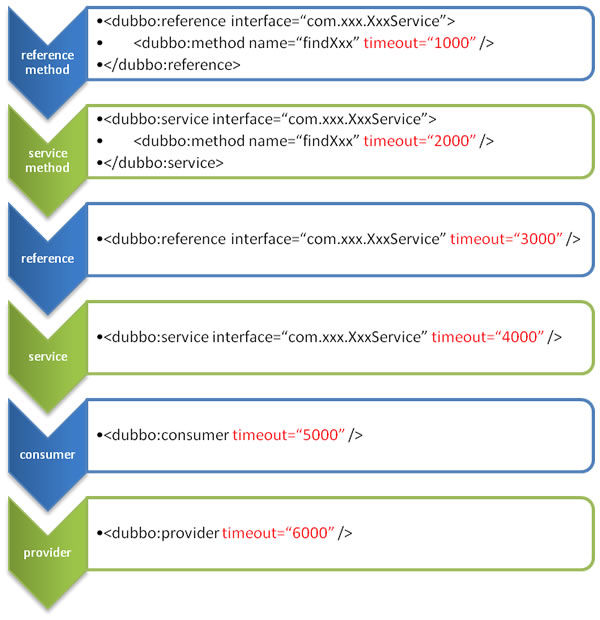
10. dubbo 配置超时时间优先级「可以在六个地方配置超时时间」
Dubbo 控制后台的安装
# 从github 中下载dubbo 项目
git clone https://github.com/apache/incubator-dubbo.git
# 更新项目
git fetch
# 临时切换至 dubbo-2.5.8 版本
git checkout dubbo-2.5.8
# 进入 dubbo-admin 目录
cd dubbo-admin
# mvn 构建admin war 包
mvn clean pakcage -DskipTests
# 得到 dubbo-admin-2.5.8.war 即可直接部署至Tomcat
# 修改 dubbo.properties 配置文件
dubbo.registry.address=zookeeper://127.0.0.1:2181
注:如果实在懒的构建 可直接下载已构建好的:
链接:https://pan.baidu.com/s/1zJFNPgwNVgZZ-xobAfi5eQ 提取码:gjtv
控制后台基本功能介绍:
- 服务查找:
- 服务关系查看:
- 服务权重调配:
- 服务路由:
- 服务禁用:
Feign
1. 主要的几个注解
@EnableFeignClients:用于修饰 Spring Boot 应用的入口类,以通知 Spring Boot 启动应用时,扫描应用中声明的Feign客户端可访问的Web服务;
@FeignClient:声明 Feign 客户端可访问的Web服务;
zookeeper
zookeeper 提供了什么?
- 文件系统
- 通知机制
zookeeper 文件系统
提供了一个类似 Linux 的文件系统,但是只有文件节点才能存储数据,并且存储的数据量不大,每个节点的数据量不能把超过 1M
四种类型的数据节点 Znode
- 持久节点:创建后需要手动删除;
- 持久序号节点:节点名称是按数字顺序递增;
- 临时节点:基于连接,连接断开则节点自动删除;
- 临时序号节点:节点名称是按数字顺序递增;「可用于分布式锁」
zookeeper 通知机制
Zookeeper 允许客户端向服务端的某个 Znode 注册一个 Watcher 监听,当服务端的一些指定事件触发了这个 Watcher,服务端会向指定客户端发送一个事件通知来实现分布式的通知功能,然后客户端根据 Watcher 通知状态和事件类型做出业务上的改变。
通知机制的工作流程
- 客户端注册 watcher
- 服务端处理 watcher
- 客户端回调 watcher
Watcher 特性总结
- 一次性;
- 客户端是串行执行;
- 轻量级「服务端只是告诉客户端,数据变动了,但具体变动成什么样子,由客户端自己去查询」;
- 网络断开后重连,监听依旧有效「除非在失联的这段时间,监听的节点被删除了」;
Zookeeper 的角色
- Leader
- 事务请求的唯一调度和处理者,保证集群事务处理的顺序性;
- 集群内部各服务的调度者;
- Follower
- 处理客户端的非事务请求,事务请求则会转发给 Leader 服务器;
- 参与事务请求 Proposal 的投票;
- 参与 Leader 选举投票;
- Observer
- 在不影响集群事务处理能力的基础上提升集群的非事务处理能力;
- 处理客户端的非事务请求,事务请求则会转发给 Leader 服务器;
- 不参与任何形式的投票;
Zookeeper 下 Server 工作状态
- Looking:寻找 Leader 状态。当服务器处于该状态时,它会认为当前集群中没有 Leader,因此需要进入 Leader 选举状态;
- Following:跟随者状态。表明当前服务器角色是 Follower;
- Leading:领导者状态。表明当前服务器角色是 Leader;
- Observing:观察者状态。表明当前服务器角色是 Observer;
Zookeeper数据同步
说几个 zookeeper 常用的命令
ls get set create delete
Zookeeper 都有哪些功能
- 集群管理:
- 主节点选举:
- 分布式锁:
- 命名服务:在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息
Zookeeper 和 Eureka 的区别:
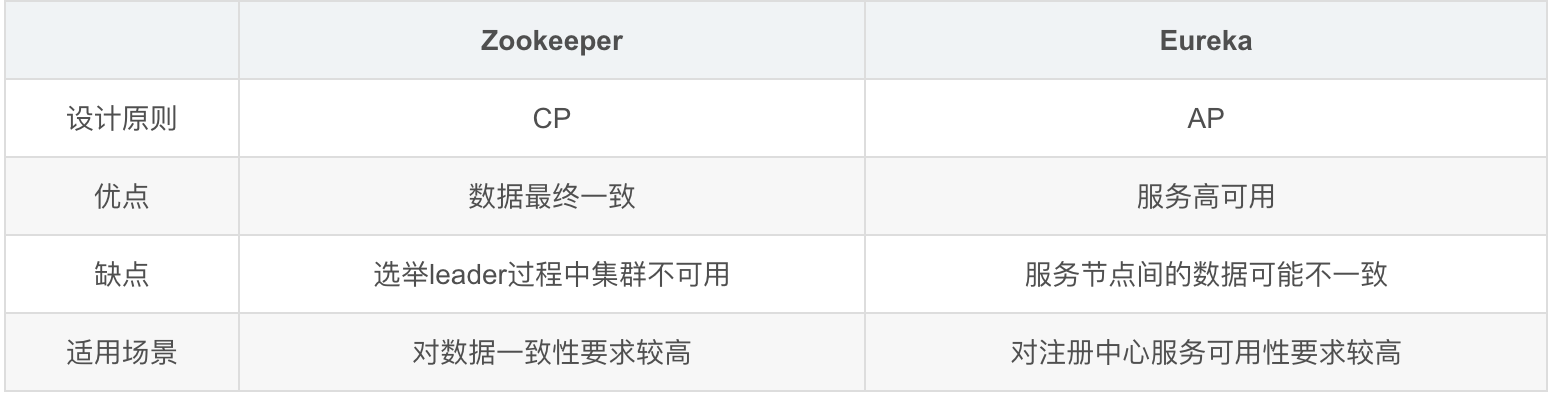
CAP 理论
- C:一致性「Consistency」:所有节点在同一时间具有相同的数据;
- A:可用性「Availability」:保证每个请求不管成功或者失败都有响应;
- P:分隔容忍「Partition tolerance」:系统中任意信息的丢失或失败不会影响系统的继续运作。
注册中心比对
SPI 机制
- Java spi :当服务的提供者,提供了服务接口的一种实现之后,在 jar 包的 META-INF/services/ 目录里同时创建一个以服务接口命名的文件。该文件里就是实现该服务接口的具体实现类。而当外部程序装配这个模块的时候,就能通过该 jar 包 META-INF/services/ 里的配置文件找到具体的实现类名,并装载实例化,完成模块的注入。基于这样一个约定就能很好的找到服务接口的实现类,而不需要再代码里制定。jdk 提供服务实现查找的一个工具类 java.util.ServiceLoader;
- dubbo spi:在 Java 自带的 spi 基础上加入了扩展点的功能,即每个实现类都会对应至一个扩展点名称,其目的是应用可基于此名称进行相应的装配;
- spring spi:
Ribbon
1. 负载均衡策略
- 随机 「Random」
- 轮询 「RoundRobin」
- AvailabilityFilteringRule:过滤失败的节点
- BestAvailableRule:选择当前并发量最小的
- WeightedResponseTimeRule :响应时间加权重
- ZoneAvoidanceRule「默认」:复合判断 Server 所在 Zone 的性能和 Server 的可用性选择 Server,在没有 Zone的情况下类是轮询。
sentinel 限流
常用的限流算法
- 计数器算法
- 滑动窗口算法
- 令牌桶算法
- 漏桶算法
计数器算法的实现
//1.判断是否存在该key
if(EXIT(key)){
// 1.1自增后判断是否大于最大值,并返回结果
if(INCR(key) > maxPermit){
return false;
}
return true;
}
//2.不存在key,则设置key初始值为1,失效时间为3秒
SET(KEY,1);
EXPIRE(KEY,3);
滑动窗口的实现
令牌桶的实现
令牌桶的核心概念:
- 用户请求资源时首选从桶里获取令牌,如果有令牌则放行,如此同时桶里的令牌数量 -1;
- 于此同时,以一定的速率往桶里加入令牌,这个速度是可根据实际场景随意设置。
漏桶算法
漏桶核心概念:
- 桶的容量是固定的,并且水流以一个固定的速率流出;
- 流入的水流可以是任意速率;
- 如果流入的水流超出了桶的容量,则后续流入的水流溢出(请求被丢弃)。
- 如果桶内没有水,则不需要流出
缺点:
不能很好的应对突发的流量限制,在某一个时间段流量激增,则漏桶算法处理就比较无能为力。这个时候就需要用到和他相反设计的令牌桶算法。