Namespace --- 集群的共享与隔离
语言中namespace概念

-
namespace核心作用隔离
以上是隔离的代码。namespace隔离的是:
- 1.资源对象的隔离:Service、Deployment、Pod
- 2.资源配额的隔离:Cpu、Memory
创建命名空间
kubectl create namespace dev apiVersion: v1 kind: Namespace metadata: name: dev
kubectl create -f namespace.yaml
kubectl get all -n dev
yaml文件中指定namespace


apiVersion: apps/v1 kind: Deployment metadata: name: web-demo-new namespace: dev spec: selector: matchLabels: app: web-demo replicas: 1 template: metadata: labels: app: web-demo spec: containers: - name: web-demo image: 172.17.166.217/kubenetes/k8s-web-demo:2021070520 ports: - containerPort: 8080 --- #service apiVersion: v1 kind: Service metadata: name: web-demo namespace: dev spec: ports: - port: 80 protocol: TCP targetPort: 8080 selector: app: web-demo type: ClusterIP --- #ingress apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: web-demo namespace: dev spec: rules: - host: www.csweb.com http: paths: - pathType: Prefix path: / backend: service: name: web-demo port: number: 80
####在metadata中指定namespace
不同命名空间下的service-ip是可以互相访问的,与命名空间无关。
不同命名空间下的pod名称与dns是访问不到的。pod-ip是不隔离的。
切换默认namespace
kubectl config set-context ctx-dev --cluster=kubernetes --user=admin --namespace=dev --kubeconfig=/root/.kube/config 设置上下文 区分权限的话重新创建user并赋予对应权限 kubectl config set-context ctx-dev --kubeconfig=/root/.kube/config 设置当前默认上下文
-
划分Namespace方式
- 1.按照环境划分:dev、test
- 2.按照团队来划分
- 3.自定义多级划分 #安装-划线名称作用等划分
Resources---多维度集群资源管理

-
限制namespace下资源
- 1.内存
- 2.cpu
- 3.gpu
- 4.持久化存储
kubelet会收集node硬件信息等上报给apiserver。
-
Resources核心设计
- 1.Requests(请求)
- 2.Limits(限制)
requests是希望容器被容器分配到的资源,可以完全保证的资源。scheduler会使用这个值来计算,从而得到最优节点。scheduler调度是不考虑limits的。
limits是容器使用的资源上限,当整个节点资源不足时,发生竞争会参考这个值从而做出进一步的决策。把某些pod驱逐。
deployment中对于pod限制
apiVersion: apps/v1 kind: Deployment metadata: name: web-demo namespace: dev spec: selector: matchLabels: app: web-demo replicas: 4 template: metadata: labels: app: web-demo spec: containers: - name: web-demo image: 172.17.166.217/kubenetes/web:v1 ports: - containerPort: 8080 resources: requests: memory: 500Mi cpu: 100m limits: memory: 1000Mi cpu: 200m
#内存单位为Mi/Gi cpu为m/个数 1核心cpu=1000m
查看node节点中资源使用情况
kubectl describe nodes node-3-172.17.166.219
对应传输给docker的值,查看容器详细信息
docker inspect 容器id
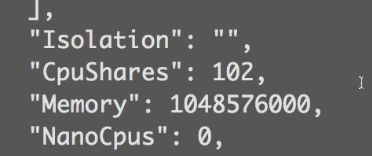
CpuShares=requests中cpu的值 会先把requests中定义的cpu值转化为核数,然后乘以1024。等于其cpu权重。
Memory=requests中memory的值 会将memory定义的值*1024*1024转化为内存字节。

CpuQuota=limits中cpu的值,单位是minico需要*10万。CpuPeriod是docker中默认值10万纳秒,100毫秒。一起使用表示在100毫秒中最多分配的cpu量。
测试内存资源限制,进入容器编写脚本
#!/bin/bash str="[sdfsofajpfjpfsajfs]" while true; do str="$str$str" echo "+++++" sleep 0.1 done
###当资源耗尽(cpu/memory),会将容器中资源占用最多的进程杀掉。并不会杀掉容器。
测试cpu限制
查看cpu使用情况
crictl stats d5c1df6d1561e
kubectl top命令需要第三方api metrics-server支持,可参考https://blog.csdn.net/wangmiaoyan/article/details/102868728
进入容器模拟cpu占用
dd if=/dev/zero of=/dev/null &执行多次就会占用光cpu
###cpu占满后与内存不同的是进程不会杀掉,cpu是可压缩资源,内存不是。
设置pod container默认限制
apiVersion: v1 kind: LimitRange #范围的限制 metadata: name: test-limits #策略名称 spec: limits: - max: cpu: 4000m #最大cpu memory: 2Gi #最大内存 min: cpu: 100m #最小cpu memory: 100Mi #最小内存 maxLimitRequestRatio: cpu: 3 #cpu中limits最大比requests的倍数 memory: 2 #memory中limits最大比requests的倍数 type: Pod #类型pod - default: cpu: 300m #默认cpu memory: 200Mi #默认memory defaultRequest: cpu: 200m #默认requestcpu memory: 100Mi #默认request memory max: cpu: 2000m #最大值 memory: 1Gi min: cpu: 100m #最小值 memory: 100Mi maxLimitRequestRatio: cpu: 5 #limit最多比request比例的倍数 memory: 4 type: Container #类型container
查看命名空间下资源限制
kubectl describe limitranges --all-namespaces
namespace资源限制
资源限制
apiVersion: v1 kind: ResourceQuota #资源配额 metadata: name: resource-quota namespace: wanger spec: hard: pods: 4 #最多允许pod个数 requests.cpu: 2000m requests.memory: 4Gi limits.cpu: 4000m limits.memory: 8Gi
apiVersion: v1 kind: ResourceQuota metadata: name: object-counts spec: hard: configmaps: 10 #最多允许configmap persistentvolumeclaims: 4 #最多允许pvc replicationcontrollers: 20 #最多允许有replicat secrets: 10 #最多允许secret services: 10 #最多允许service
查看quota设置
kubectl get quota -n test kubectl describe -n wanger quota
pod驱逐策略-Eviction
-
pod容器资源策略优先级
- requests == limits时优先级最高(绝对可靠)
- 不设置 (最为不可靠)
- limits > requests 优先级次之(相对可靠)

kubelet启动常用驱逐策略配置:

###当node内存小于1.5G持续1m30秒进行pod驱逐,如果node内存小于100M磁盘小于1G剩余inodes节点小于百分之五立刻进行驱逐。
kubelet配置驱逐策略:
kubelet --eviction-hard=imagefs.available<10%,memory.available<500Mi,nodefs.available<5%,nodefs.inodesFree<5% --eviction-soft=imagefs.available<30%,nodefs.available<10% --eviction-soft-grace-period=imagefs.available=2m,nodefs.available=2m --eviction-max-pod-grace-period=600
#或者启动文件中配置
磁盘紧缺驱逐优先级
- 删除死掉的pod、容器
- 删除没用的镜像
- 按资源优先级、资源占用情况进行驱逐 ###如同一优先级下先驱逐占用资源多的

内存驱逐策略
- 驱逐不可靠的pod #按照资源占用情况驱逐
- 驱逐基本可靠的pod #limit大于request的pod limit比request占用值越大越先驱逐
- 驱逐可靠pod #按照资源占用
label小标签大作用
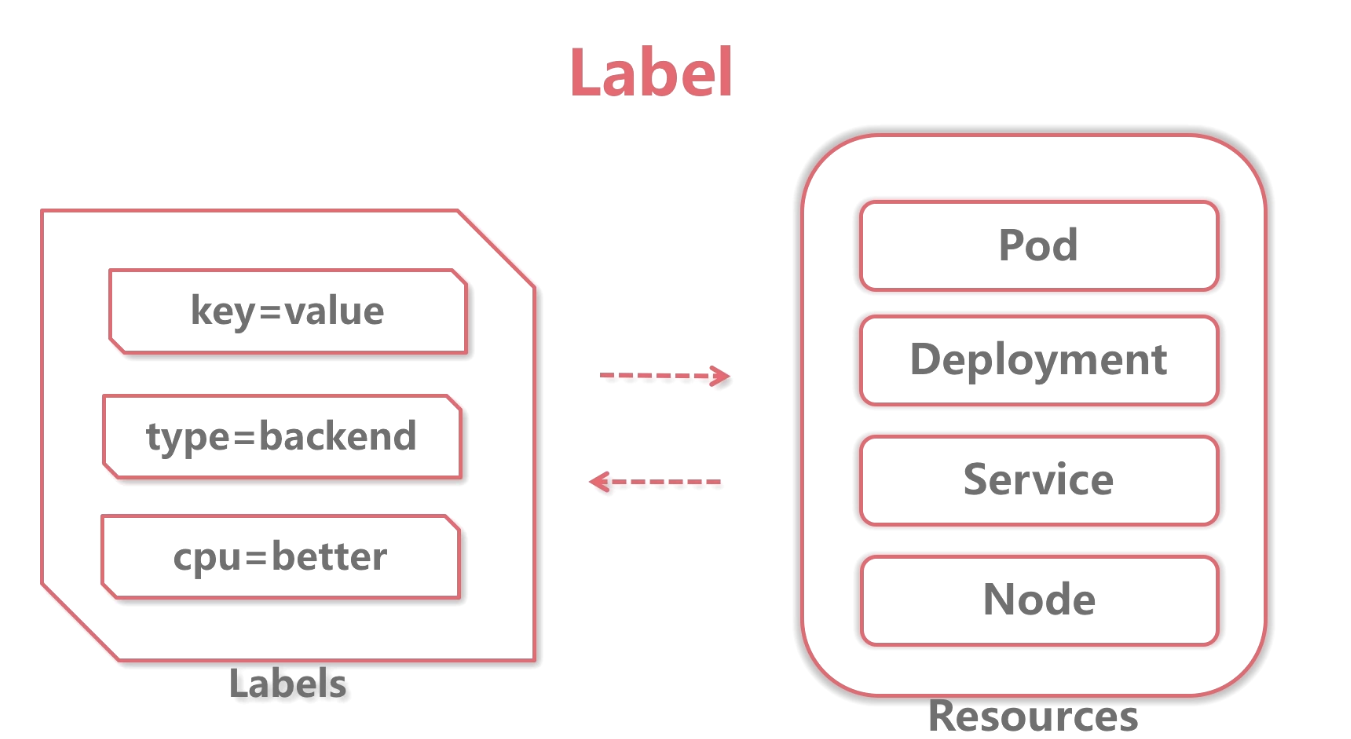
label本质是key=value键值对,可以贴到任意资源中。
deployment通过标签选择pod
apiVersion: apps/v1 kind: Deployment metadata: name: web-demo namespace: dev spec: selector: matchLabels: app: web-demo #选择pod label app=web-demo replicas: 1 template: metadata: labels: app: web-demo #定义pod label app=web-demo spec: containers: - name: web-demo image: hub.mooc.com/kubernetes/web:v1 ports: - containerPort: 8080 --- #service apiVersion: v1 kind: Service metadata: name: web-demo namespace: dev spec: ports: - port: 80 protocol: TCP targetPort: 8080 selector: app: web-demo #service 选择pod label app=web-demo type: ClusterIP
###1.6版本之前在pod之上还有rc概念,即replicas副本控制器。deployment将rc封装,deployment本质是操作副本控制器。selector与pod名称需一致,rc去调用pod。deployment label是可变的,多个同样名称的rc和pod是不冲突的,属于不同的deployment
pod通过group标签rc选中group
apiVersion: apps/v1 kind: Deployment metadata: name: web-demo namespace: dev spec: selector: matchLabels: app: web-demo matchExpressions: - {key: group, operator: In, values: [dev, test]}#定义选择组 replicas: 1 template: metadata: labels: group: dev #pod打上组标签 app: web-demo spec: containers: - name: web-demo image: hub.mooc.com/kubernetes/web:v1 ports: - containerPort: 8080
###校验pod是否是deployment需要的。
查看是否创建成功
kubectl get pods -l app=web-demo -n dev kubectl get pods -l group=dev -n dev kubectl get pods -l app=web-demo group=dev -n dev kubectl get pods -l 'group in (dev, test)' -n dev
kubectl get pods -l 'group notin (dev, test) -n dev'
container通过标签选择node
apiVersion: apps/v1 kind: Deployment metadata: name: web-demo namespace: dev spec: selector: matchLabels: app: web-demo matchExpressions: - {key: group, operator: In, values: [dev, test]} replicas: 1 template: metadata: labels: group: dev app: web-demo spec: containers: - name: web-demo image: hub.mooc.com/kubernetes/web:v1 ports: - containerPort: 8080 nodeSelector: disktype: ssd
给node打上标签
kubectl label node node-3-172.17.166.219 disktype=ssd kubectl get nodes node-3-172.17.166.219 --show-labels