主要功能:
1、存储:HDFS
2、分析/运算:Mapreduce
3、调度:YARN
安装配置:
useradd -m hadoop -s /bin/bash # 创建新用户hadoop
passwd hadoop
sudo hostname *** 修改主机名
vi /etc/hosts 添加集群映射名字
vi /etc/sudoers 添加hadoop用户的sudo权限(hadoop ALL=(ALL) ALL )
vi /etc/profile 添加java环境变量export JAVA_HOME=/usr/java/***
vi ~/.bashrc 添加java环境变量export JAVA_HOME=/usr/java/***
source /etc/profile 重启服务生效
source ~/.bashrc 重启服务生效
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys # 加入授权 $ chmod 600 ./authorized_keys # 修改文件权限
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@192.168.11.130 设置远程连接免密登录
$ sudo tar -zxf ~/下载/hadoop-2.6.5.tar.gz -C /usr/local # 解压到/usr/local中
$ cd /usr/local/
$ sudo mv ./hadoop-2.6.5/ ./hadoop # 将文件夹名改为hadoop
$ sudo chown -R hadoop:hadoop ./hadoop # 修改文件权限
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息
$ cd /usr/local/hadoop $ ./bin/hadoop version
存储:
hdfs分布式文件存储系统,是nosql数据库,每台节点服务器都是hdfs的部分,大数据平均分布在每个节点上,并且是以文件存储的形式,每个节点上存储的部分数据有通过块来进行数据文件的分片,形成数据块,每个数据块又在其他的节点服务器上存有备份,因此不会因为一个节点的宕机影响真个大数据,
分析运算:
Map:当需要提取大数据文件的时候,大数据分布在不用datanode,namenode制定去哪些datanode服务器读取数据,每个被分派制定要执行任务的datanode服务器就会启动一个或者map进程/线程,每个map进程会去读取本地节点的hdfs文件系统中对应的大数据在本地存储的一个块文件,进行分类,汇总,生成类似字典的结果,这样,本地节点需要读取的部分大数据形成的结果在内存中存储为字典形式的数据就会很小,占用不了多少内存,可能只有几十kb或者几兆
Reduce:reduce是另外一台服务器上的进程或者线程,当其他map节点将处理好的数据结果通过RPC或者其他网络连接的方式将数据传到本机器的时候,reduce就会对所有map发来的数据进行统计或者分类,而且本机启动多少个reduce可以根据业务需要扩展,如果只是统计数据的总和,只需要启动一个reduce,如果还需要对数据进行分类,可以启动多个reduce,每个reduce分别负责处理单一类别数据的汇总和统计
YARN:yarn负责调度各个datanode的map和reduce等等,
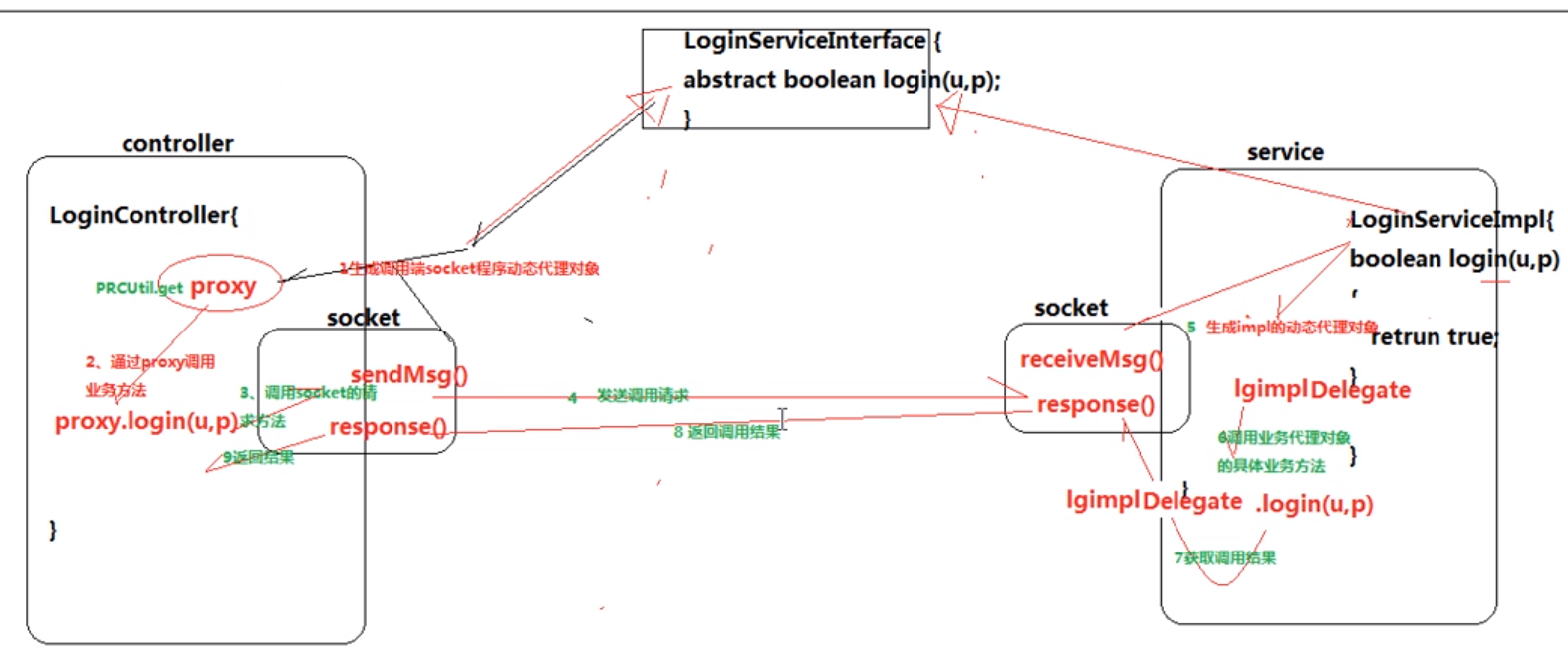
RPC远程过程调用机制:
mapreduce执行过程:

HDFS常用命令:

其他注意事项:
修改主机名:sudo hostname ***
然后重启
hadoop访问集群主机一般都是通过主机名,所以需要修改主机名,但是主机之间的访问都是通过IP地址访问的,所以需要将主机名和主机ip地址建立映射关系:vim /etc/hosts
要使一般用户具有sudo功能,需要修改/etc/sudoers文件,添加在root下面添加用户,如hadoop,其他参数不变
添加java环境变量,vim /etc/profile
然后重启服务source /etc/profile
hadoop安装:
解压压缩文件,修改etc目录下的配置文件,如,core_site.xml,hdfs-site.xml等
replication 副本
jps 查看系统java进程
licene知识点
1、scp ssh拷贝公钥文件到目标机
2、在目标机上的home目录下有authorized_keys文件,没有就新建一个是600权限的
3、追加公钥到authorized_keys文件里面 cat 公钥 >> authorized_keys
4、本地ssh登录,可以将本地的公钥追加到本地的authorized_keys文件中
1、客户端上传文件时,nn首先往editslog日志文件记录元数据操作日志,
2、客户端开始上传文件,成功完成数据在dn上的写操作后返回成功信息给nn,nn就在内存中写入这次这次上传操作的新产生的元数据信息
3、每当editslog写满时,需要将这段时间的新的元数据刷到fsimage里面,是将editslog和fsimage合并,然后edits清空
4、但是元数据合并的时候不是由本程序执行的,而是由snn执行
a、当editslog满了,nn会通知snn进行合并checkpoint操作
b、snn会通知nn停止写入editslog日志,
c、nn收到消息后会新建一个neweditslog,snn通过http将fsimage和edits下载到本地,进行checkpoint操作
d、操作完成后,生成checkpoint.chk文件,并且返回消息给nn,把合并的new fsimage上传给nn,
e、nn接受新的fsimage替换掉旧的,然后把editslog文件删除,将new edislog修改为editslog
文件存储:
1、客户端连接nn,申请上传/下载文件,
2、nn返回dn多个节点
3、客户端向多个dn写入数据,
4、dn写入成功后,返回信息给客户,客户告诉nn,然后nn将操作记录添加到元数据
5、如果写入失败,将失败节点消息返回给nn,nn重新制定dn,并记录修改操作,返回给客户,客户在与dn通信,直到文件写入成功
YARM调度任务执行过程:
1、客户jar包运行,会连接上YARM框架(也是nn服务器),然后yarn会返回jobid和相关资源,并且指定jar包运行的舞台staging-dir
2、客户收到yarn返回的信息后,会提交资源到HDFS文件系统的/tmp/xx/xx/yrn-staging/jobID/类似的目录下,
3、第二部操作成功后,会返回给nn提交结果,
4、yarn调度会将需要哪些dn运行jar包放到任务队列(任务队列也是在本机器上)
5、dn会以心跳检查的形式定期汇报数据给yarn,同时会去yarn上的任务队列获取信息,是否有需要本dn执行的任务,
如果有,那就调取相关任务,
6、取得任务后,会在本地的dn上启动一个容器,分配一定的内存等资源来运行jar包,并且在第一步的HDFS上取得资源
7、yarn会同时启动dn节点上的MRAppMaster(选择随机的dn节点启动mrappmaster)
8、一旦MRAppMaster启动,就会向yarn注册信息,同时获取需要mapreduce的节点和数据信息
9、在需要执行jar包的节点上,会分配其中一个dn一个MRAppMaster,其他dn节点启动maptask,而且是由
MRAppMaster去启动map task,一直接受maptask的任务执行情况,如果有失败的map,,会在分配一个
dn执行map task,
10、MRAPPmaster节点会负责在另外一个新的dn节点上启动reduce程序,然后reduce运行完成后
mrappmaster会向yarn汇报并注销自己
错误提示解决办法:
错误: 找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
先执行hadoop classpath,获取classpath中的内容,并将该内容设置到yarn-siet.xml中yarn.application.classpath的value中
环境配置:
1、在hadoop-env.sh脚本文件中配置JAVA_HOME标量:export JAVA_HOME=/usr/java/jdk1.8.0_211
2、启动hadoop namenode -format时出现用户错误时:
是因为缺少用户定义造成的,所以分别编辑开始和关闭脚本
$ vim sbin/start-dfs.sh
$ vim sbin/stop-dfs.sh
在顶部空白处添加内容:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
3、启动start-yarn.sh的时候出现用户验证错误:
vim sbin/start-yarn.sh
vim sbin/stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
4、当第二次以后格式化hadoop时,需要把data目录清空,避免datanode的id找不到namenode的id
5、配置ssh远程连接允许无密码登录,vim /etc/ssh/sshd_config文件
ssh-keygen -t rsa
cat id_rsa.pub >> authorized_keys
scp id_rsa.pub worker01:/home/
chmod 600 authorized_keys
6、将hadoop.sh配置为全局命令,ln -s /home/xxx/hadoop/bin/hadoop.sh /usr/bin/hadoop
配置文件设置
【core-site.xml配置】
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/srv/bigdata/data/</value>
</property>
</property>
</configuration>
【hdfs-site.xml配置】
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/srv/bigdata/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/srv/bigdata/data</value>
</property>
</configuration>
【mapred-site.xml配置】
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
【yarn-site.xml配置】
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
【workers配置文件加上本地主机名】
创建namenode空间:
bin/hadoop namenode -format
会在core-site.xml配置文件中配置的hdfs文件存放目录下面创建iframe等文件
启动集群(所以节点进行操作) /sbin/start-all.sh
浏览:http://h128:9870/
hadoop3.10以及把50070的默认端口修改为9870
上传文件:hadoop fs -put hadoop-3.1.2.tar.gz hdfs://worker01:9000/