1.基本结构:
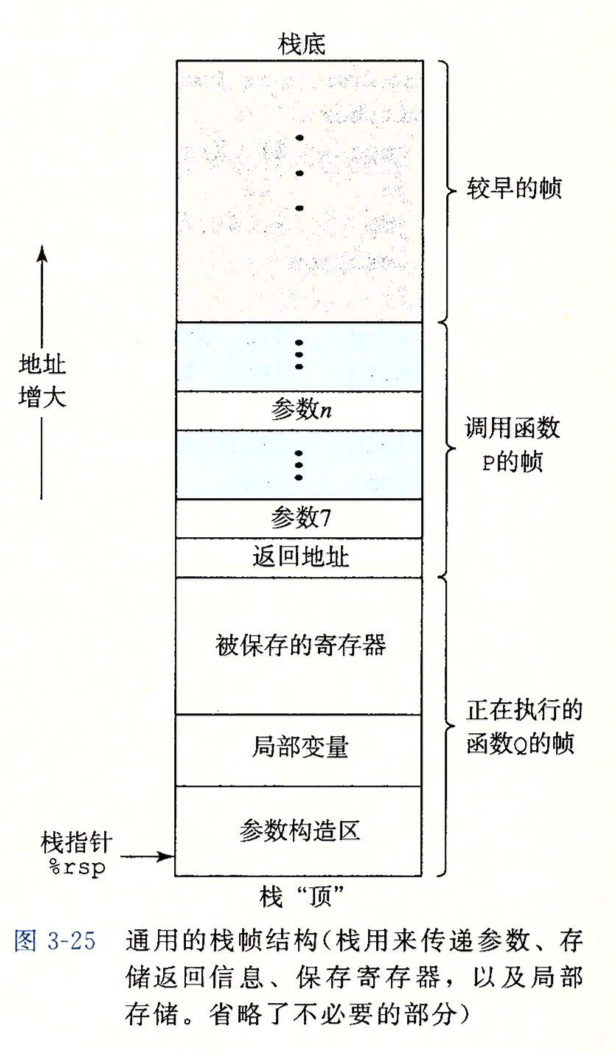
如上图所示,是通用的栈帧结构。大致分两块,调用者函数P和被调用者函数Q。
对P来说,要做的工作是把传递参数中多于6个的部分压栈,随后把Q返回时要执行的下一条指令的地址压栈。
对Q来说,要做的工作分3块,一是将要保存寄存器的值压栈,二是将要保存的局部变量压栈,三是把多余参数压栈。刚看到这里你可能不懂,没关系,接下来会分别介绍这3块。
2.参数构造部分:
首先介绍参数构造部分,其实它就对应调用者函数P的多余参数压栈操作,因为函数调用一环套一环,P调用Q,Q可能调用R,当Q调用R时,若发现要传递的参数小于等于6个,则参数会直接通过寄存器传递,多于6个的,多出的部分会被压到栈内。所以其实理解的时候没必要把P和Q分开来看,可以认为每个函数的栈帧都包含保存的寄存器,局部变量和参数构造三个部分。
大多数的栈帧都是定长的,过程开始时就分配好了。(这里发散一下,在C++中,当调用一个函数的时候,若它还没有被定义或声明(定义在调用函数下方),此时编译器会报错,会不会原因就是此时无法确定栈帧的长度呢?)
这6个参数通过寄存器传递时是有顺序的,如下图:
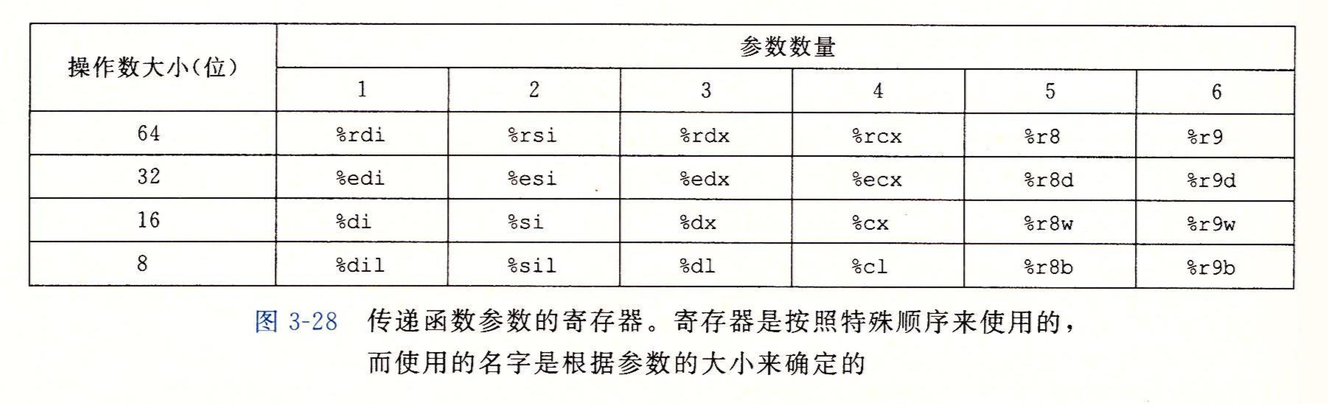
比如第一个参数是个long,放在%rdi中,第二个参数是int,则会放在%esi中。
超过6个的参数放在栈上,放的时候是从后向前放的,比如一共8个参数,则先压入第8个参数,再压入第7个参数,注意,参数构造时的压栈时不会因为参数数据类型大小不同分配不同大小的空间,比如第7个参数是long,放在8(%rsp)处,第8个参数不管是不是8字节的,都会放在(%rsp)处,也就是说,通过栈传递参数时,所有数据大小都向8的倍数看齐。
例子如下:



a,b图分别代表函数proc对应的C语言和汇编代码,进入proc时肯定是因为有函数调用了它,把proc当被调用函数看,此时传了8个参数进来,调用它的函数已经把超出的2个参数(a4和a4p)压进了栈,a1-a3p被按顺序分别放在了上面说的6个寄存器内,从代码中得到一个重要结论:栈中存的数据字节是向地址递增的方向存的,比如a4p,8个字节,存在16(%rsp)到24(%rsp)间,而不是16(%rsp)到8(%rsp)间。(注意,8(%rsp)到(%rsp)间存了调用函数的返回地址),如图3-30所示。
另外,要注意,第6行代码在取得a4时,是先取4字节放到了%edx里,再取其中低位的1字节与(%rax)的*a4p相加。我不大清楚为什么会这么做,在我看来,第6行代码换成只取1字节放到%dl里,即movb 8(%rsp),%dl ,似乎也没问题。
3.局部变量部分:
正常情况下,函数内的局部变量可用寄存器来存,但若出现一些特定情况时,需要把这些局部变量存到栈上,如图3-25所示,局部变量的存放要早于参数构造的存放。特定情况包含如下:一,寄存器不足够存放所有本地数据。二,对一个局部变量使用地址运算符&,此时是需要得到变量的地址的,那么显然变量就不能存在寄存器中,只能放栈上。三,当局部变量是数组或结构时。
举个例子:


图(a)和(b)分别是对应的c++和汇编代码(只实现了caller函数),分析之前需要再强调之前说的一点,区分调用者函数和被调函数是没啥意义的,这里caller似乎是调用者函数,所以按图3-25看就应该只有参数构造,可以这样理解么?显然不是这样。caller真的起作用时肯定是被某个函数调用的,所以那时它也算是被调函数,所以,当符合条件时,它是有局部变量和寄存器的压栈的环节的,所以我干脆就理解成被调函数和调用者函数都会有这三个环节,视情况会启用其中的某一部分,图3-25只是简化了调用函数而已。
继续分析,首先看有没有局部变量的压栈需求,发现caller中有两个局部变量arg1和arg2,它们在传递时需要取地址,说明它们必须存在栈上,那么先存哪个?从右侧的汇编代码可以看到,局部变量也是按倒序来存的,%rsp先减16腾出16字节的空间,arg2(1057)存在高地址,arg1(534)存在低地址,如下图所示:
传递参数时,arg1的地址被放在%rdi中,arg2的地址被放在%rsi中,刚好印证图3-28对应的寄存器调用顺序。
另外,从11行代码可以看到,函数返回值是放在寄存器%rax中来返回的。
可能你会疑惑,那图3-25对应的存储返回地址在哪里?其实都隐藏在call swap_add这条指令里,编译器碰到这条指令会自动把它后面一条指令的地址压入栈中(注意,call自动调用的压栈是push指令,而push指令会自动减小%rsp,因此图b中只用了subq $16 %rsp,无需特意为返回地址留出空间),并把程序计数器下一条指令设置为swap_add函数的起始指令。这也就是为什么图3-29对应的汇编代码,取a4和a4p要从8(%rsp)和16(%rsp)取,因为返回地址被存在了栈顶。
那么如果同时发生需要存局部变量到栈上,以及需要构造大于6个参数的情况时,该怎么处理?见下图:


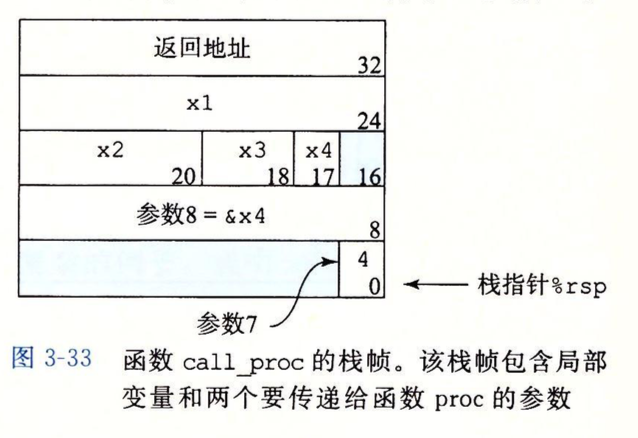
左边为c++代码,右边为对应的汇编代码。一样,先看局部变量是否需要存在栈上,传递时用了&x1,&x2,&x3,&x4,所以它们4个必须存在栈上,此外,x4和&x4是超出的两个参数,也要存栈上,那么一共有6个参数要存,为什么图b第一行是subq $32,%rsp呢?因为为局部变量存储的内存分配方式和为参数构造的内存分配方式不同!!!如之前所述,参数构造时的压栈时不会因为参数数据类型大小不同分配不同大小的空间,为了实现字节对齐,固定8个字节,而局部变量是按正常数据类型大小来分配的,这里x1,x2,x3,x4分别对应8,4,2,1个字节,而参数构造要8*2=16个字节,还要考虑字节对齐,一共32个字节,具体看图3-33一目了然。
当然,这里有个我想不通的问题,按照之前的结论,先进行局部变量的存储,再进行参数构造的存储,且参数构造时,存储顺序是反向的,这点在图3-33也印证了,但是按照图3-31得出的结论,局部变量存储的时候应该也是反向的,那么不是应该先存x4,再x3,x2,x1么?而图3-33显示的顺序显然是正向的,有点无法理解。
4.被保存的寄存器部分
其实这一部分可以被归属到局部变量的存储中,之前说过,当被调用函数使用的局部变量满足三个条件之一时,就需要存放在栈上,若用的局部变量不满足任一条件,其实是把它用寄存器存放起来的。假若现在P调用了Q,而Q自己定义并使用了局部变量,而且那个局部变量是用寄存器存的,那么我用哪个寄存器来存它呢?之前讲了参数传递时有6个寄存器是用来传参的,即使这次调用传的参数很少,肯定也不能用那6个寄存器。
根据惯例,我们会用%rbx,%rbp和%r12~%r15来保存这些不满足条件的局部变量,这些寄存器叫做被调用者保存寄存器。那么问题来了,假如在P调用Q之前,P自己定义了一些局部变量,调用Q并返回后,P想用Q返回的结果和自己的局部变量作运算,而P自己定义的局部变量也用了一些寄存器,假如这些寄存器和Q内部使用的寄存器冲突,导致P的局部变量被Q的局部变量覆盖怎么办?
因此,在被调函数中,对于这些不满足条件的局部变量,虽然不会被直接压到栈中,但在它们被存到寄存器之前,会先将要用的寄存器的值压到栈上,等返回的时候,再把值从栈上弹回到对应的寄存器中。这些寄存器的使用顺序是怎样的呢?和之前传参对应的6个寄存器一样,局部变量也是依次使用这6个寄存器的,比如只有一个不满足条件局部变量,则会存在%rbx中,在此之前,在被调函数中先把%rbx压栈即可。
看例子:

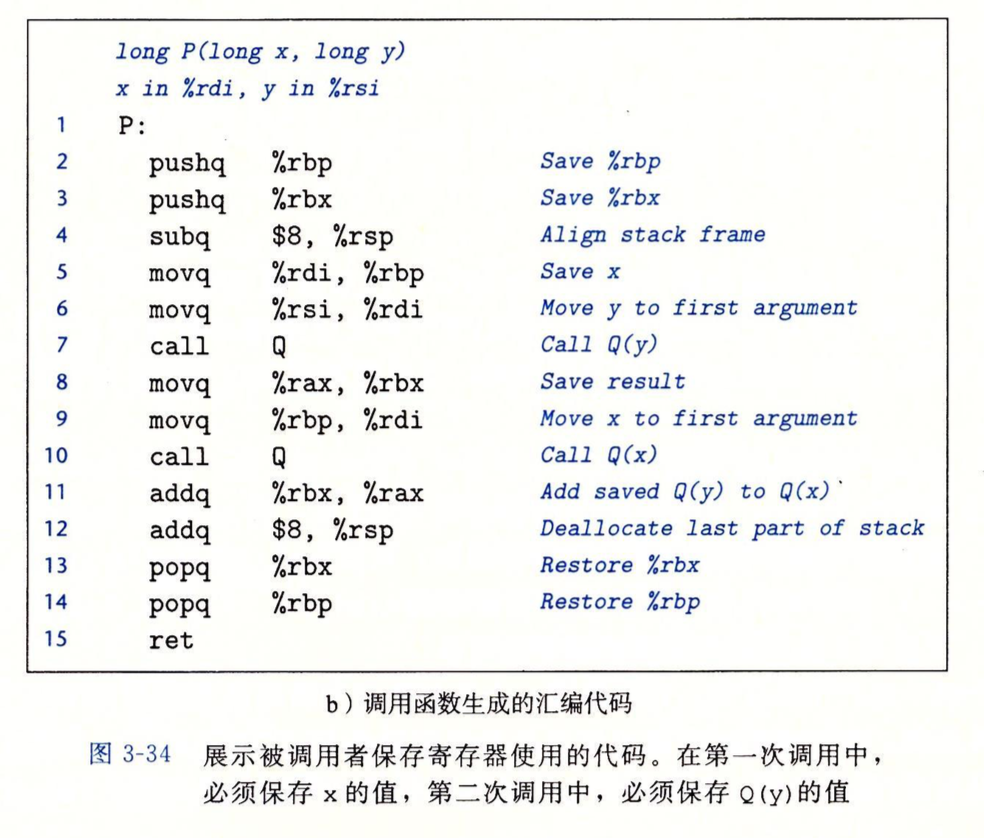
u,v就是不满足任何条件的局部变量,它们分别需要用一个寄存器存,因此按顺序用了%rbx和%rbp,当然这里%rbp没有被用来存v,v被%rax返回后直接与%rbx里的u相加并返回了,这里的%rbp被用来存放x了,因为传参的时候每次都只有一个参数,按传参寄存器的顺序,用的都是%rdi,而一开始P函数拥有的两个参数中,x就存在%rdi中,调用Q时要把参数放到%rdi中,为了保证x不被覆盖,必须先有一个寄存器暂存x的值。
所以要修正下之前的说法,不是说有几个不满足条件的局部变量就要用到几个上面的寄存器,而是根据被调函数中的操作,发现要用几个寄存器就用几个,只不过用之前要先把用到的寄存器的值压到栈上,免得干扰调用者函数的运行。
其实这里面也有个很奇怪的地方,就是第4行代码,subq $8 , %rsp,因为pushq操作会自动对%rsp操作,而保存返回地址的操作又被call包办了,它也自带对%rsp的减操作,所以我不懂这里为什么要人为使%rsp腾出8个字节来。我觉得可能和后面章节的变长栈帧有关,看完了如果有结论就填坑。
看一个例题:

例题不难,A的答案是x,x+1,x+2,x+3,x+4,x+5,B的答案是x+6和x+7,C的答案是因为存满了。。。。
有意思的是里面能得出的新的结论:当局部变量多于6个时,这时候被调用者保存寄存器已经不够了,因此会把多余的存到栈上,显然这里先存的x+7,再存的x+6,如果局部变量定义的顺序是从x一直到x+7的话,这代表局部变量压栈时确实是反向存的,这就更显得图3-33无法理解了。
另外这里有subq $24,%rsp,明明只用了16个字节的栈存储空间,却腾出了24个字节,这个问题和图3-34展示出的是一样的,等我回来填坑吧。。。
对了,补充一个很有意思的事:显然对被调用者寄存器的使用取决于函数内部实际的操作,有时从c++代码看上去需要使用被调用者寄存器的时候,转成汇编代码后,发现其实并不用哦,显然这是编译器优化的结果。想想写编译器的那帮人还真是厉害呢。比如回过头看图3-31,有long sum=swap_add(&arg1,&arg2),正常可能这里会用个寄存器存放sum,而实际我们看到它是直接利用了%rax中的返回值,直接将sum进行后续的sum*diff操作,节省了寄存器的使用。
这节剩下的递归方面的东西不难,一遍看下去没有卡壳,就不记了。
所有总结只要看图3-25就行了,只要记住,栈帧压栈的顺序是先看有没有需要保存的被调用者寄存器,有的话压栈,随后看有没有多余的不满足条件的局部变量,有的话压栈,随后看有没有满足条件的局部变量,有的话压栈,随后看有没有多余的需要构造的参数,有的话压栈,随后用call来调用函数并保存返回地址,函数返回后继续运行,运行到最后时,若之前有需要保存的被调用者寄存器,则把值从栈中弹回到对应的寄存器。
结束!