一、PSP表格
| PSP2.1 | Personal Software Process Stages |
预计耗时 (min) |
实际耗时 (min) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 20 | 15 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 720 | 850 |
| Design Spec | 生成设计文档 | 20 | 25 |
| Design Review | 设计复审 | 30 | 25 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| Design | 具体设计 | 420 | 600 |
| Coding | 具体编码 | 600 | 1200 |
| Code Review | 代码复审 | 30 | 65 |
| Tes | 测试(自我测试,修改代码,提交修改) | 50 | 60 |
| Test Repor | 报告 | 60 | 70 |
| Size Measuremen | 计算工作量 | 10 | 12 |
| Postmortem & Process Improvement Plan |
事后总结, 并提出过程改进计划 | 30 | 15 |
| 合计 | 2000 | 2957 |
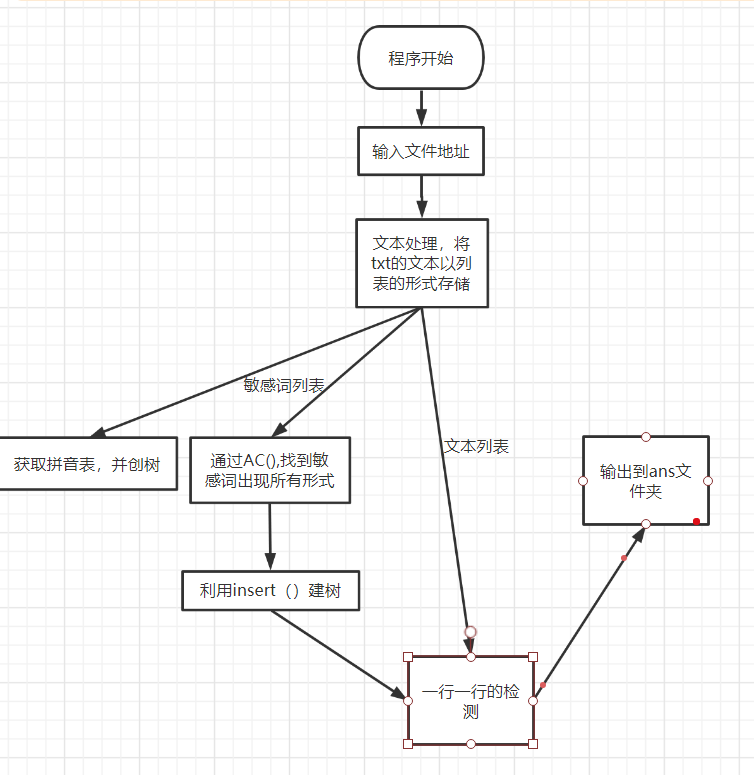
二、计算机模块接口
-
(3.1)计算机模块接口的设计与实现过程:
-
拼音直接调用库
-
四个类、四个函数,具体如下:

-
大致思路如下:
-
检测思路:
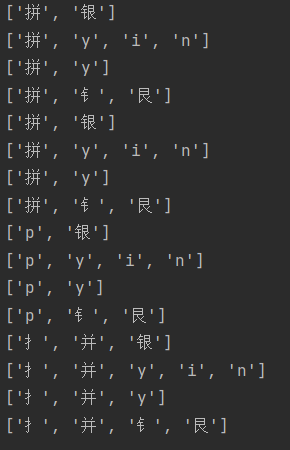
我先对敏感词进行操作,包括拆字、拼音、拼音首字母,每个汉字都建立尤其属性表(eg:['好', 'hao', 'h', '女子'],如果拆不了,就少一个拆字元素),得到一个敏感词的所有字的属性表后,通过递归,得到其敏感词出现的所有可能的形式(eg:‘拼银’,如下图),然后建立敏感词树。
然后就是文本处理,文本读入存为表,然后遍历表,进行去首尾空格操作,若为空,跳过此行的检测。
对于要检测的文本,我通过调用pypinyin库和zhconv库,对整行文本进行小写化和繁体字转简体字,转换结果另存,不能影响原文本。
第一个字读入,如果在树根查询得到,进入下一层,并做标记(表明匹配状态ing,记录起点),一直查询,直到某个词查不到,且此时‘end’=1,表明为敏感字,记录下来,状态和起点标记重置。
当读到无关字符时,要分情况,如果状态标志为1,且‘end’=1,为敏感词,记录下来,重置状态的起点标志,若其他情况,跳过这个无意义符号,继续往下搜。
当读到其他字时,判断它是不是谐音,这时候就用到敏感词拼音表了,如果不是谐音,搜索失败,若是,以其拼音进入树查询。如过不是谐音或以其拼音查询失败,判断此时‘end’是否=1,若=1,说明已经找到敏感词了,记录下来,重置,若拼音查询成功,就继续查询。
搜到最后一个词时,没词了,若‘end’=1,记录下来,重置。
此时已经寻完一遍了,但这个是最长敏感词长度搜索(eg:法*功,当文本中出现flgong,找到第一个g时,其实‘end’已经=1,但这不够,所以继续搜直到第二个g,而且文本若出现flgon,按照上面的搜索方式,是找不到的,所以要再搜一遍)。
最后就是最短敏感词搜索,方法同上,(但前面找到的地方打标记,当其标志为1,不进入树查询)就是多了个条件,当某个字符进入树查询时,若查询成功,判断‘end'是否为1,若为1,直接记录,状态和起点重置。 -
运行结果:

-
-
(3.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。
- 按函数花费时间排序:
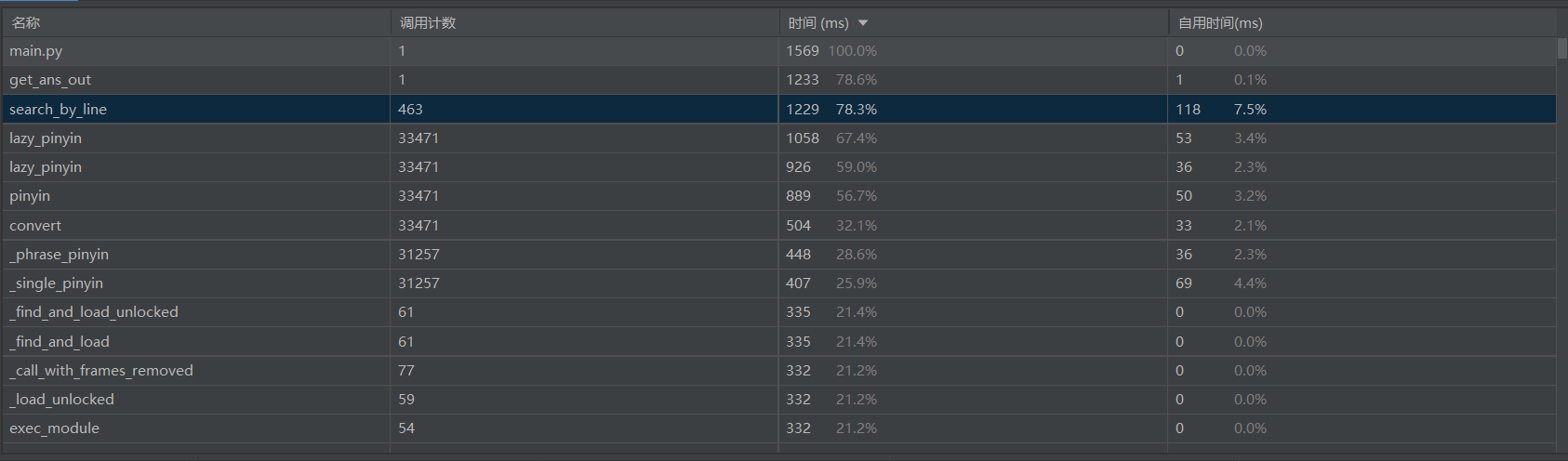
- 可以看出来,最耗时的是search_by_line()函数以及第三方类库pypinyin中lazy_pinyin()的调用:
- pypinyin可以支持简繁体中文,实现汉字到拼音的转换,这个目前没法替换。
- 至于search_by_line(),这个我认为是可以优化的,但时间不足,日后找时间再优化吧!
- 按函数花费时间排序:
-
(3.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。
- 部分单元测试代码如下:

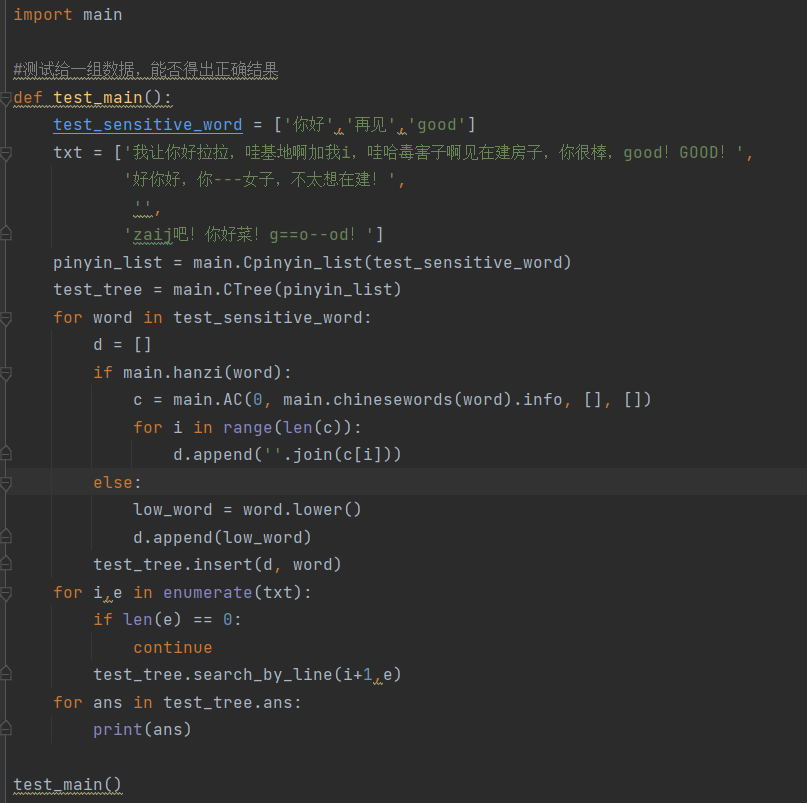
- 覆盖率截图如下:

- 部分单元测试代码如下:
-
(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
- 参数传递错误:参数传递错误时结束程序
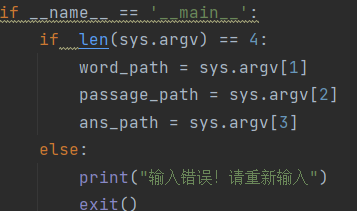
- 参数传递错误:参数传递错误时结束程序
三、心得
- (4.1)在完成本次作业过程的心得体会
在知道作业是要做敏感词检测的时候,脑袋是蒙的(内心os:这是什么东西?这叫做刚刚开始,不想给我们打击,选个简单的题?上贼船了!糟啦!)刚开始做的时候,打算在GitHub直接找开源代码,想着做代码的搬运工,但找了好几天,都没找到我想要的。后面就放弃了,又想着等其他人做完,然后抄过来就完事了,但这又会让我内心难安(被查出来算0分,还丢人,实在不敢)。在完成这个题目的期间,我速成了python。只能说,柯逍yyds,他的作业总是会让人自愧不如,然后产生学习的冲动。在完成项目的过程,我的算法知识和敲代码能力蹭蹭的往上涨,这个我是真的能确实的感受到。(这每天敲代码敲到半夜三四点,床上躺着都得想算法,这能力不提高,就太失败了!)我本人认为,我的检测敏感词的算法不是最好的也不是最准确的,但是我能想到的最深了,想了各种敏感词能出现的形式,我已经尽力了。最后感谢测评组,让ddl延后了,不然我就无了(当然,也得感谢柯神的宽宏大量!)。总而言之,这次作业,我确实收获了挺多的。