经历了十分充实(
痛不欲生)的三周不一样的码代码的生活,让我对通宵oo有了新的认识。往届学长学姐诚不欺我
第一次作业
需求分析
第一次需求非常简单(相比较后两次作业而言),仅为简单多项式求导,而且仅包含幂函数项和常数项,并且没有格式检查(意味着咱可以为所欲为)。
设计思路
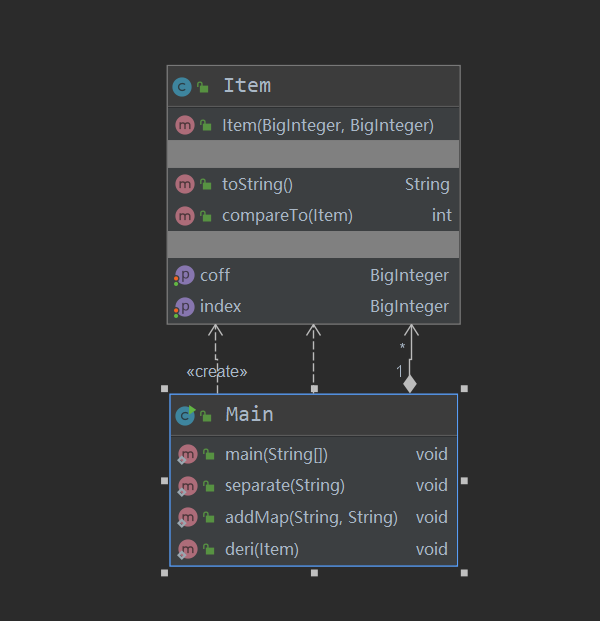
此次作业我仅开了两个类,main类和Item类,Item类为项类仅存储系数和幂函数的指数,并提供get和set方法,并重新实现tostring方法,完成最后数据的输出转化。自然而然剩下的事都交给了main类。首先在主类里读入数据之后直接暴力去空白字符以及将两个连续符号转化为一个符号等琐碎事情,剩下的表达式就规范多了。然后进入separate函数通过大正则进行匹配,后放入hashmap中实现同类项的合并,最后逐项求导,并调用tostring方法输出。同时在输出时注意细节达到进一步优化。
UML类图
程序复杂度

反思
从程序复杂度上可以看出,我的main类复杂度有点高,主要原因应该就是我的main类“舍不得放权下去”。我把解析输入、求导、综合处理每一项返回的tostring都放在了一个类里面,这确实很不应该。同时这次作业我抽象出的Item类不太合理,常数因子和幂函数因子混在了一起,这为我第二次重构埋下伏笔。而且除此之外我所做的也仅仅是将解析和求导抽出作为一个函数而已,这确实也是一大不足。
bug分析
第一次作业由于比较简单,所以我公测和互测都无伤通过。
在互测中,我hack别人的点在于+-、-+和--这种多个符号相连的的情况没处理正确。
第二次作业
需求分析
此次作业在幂函数和常数的基础上增加了简单正余弦函数的求导,同时增加了部分不符合规定输入的判断,难度在第一次的基础上增加了许多
设计思路
很当然的我重构了。
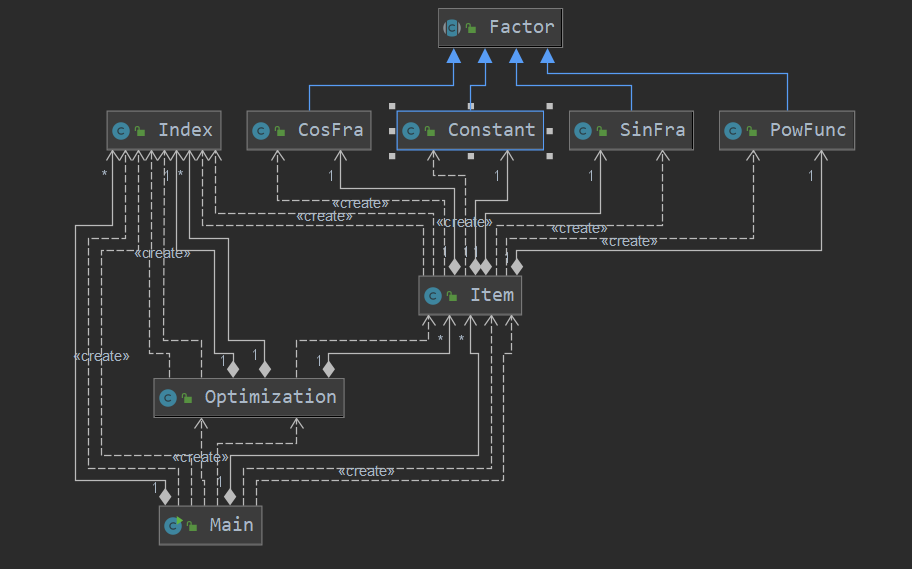
首先一个Fractor抽象类,作为Constant类、PowFunc类、CosFra类和SinFra类的父类,同时实现求导和toString两种方法,然后一个Item类里存放此四类因子,作为项级层次。然后我再一次在main类里面大杂烩了(手动捂脸)。在separateAll函数里面进行逐项匹配并同时生成单个单个的项放入hashmap中,其中幂函数指数、正余弦函数指数形成三元组作为map的key值。然后在项类实现求导,即项中每个因子分别进行求导形成多个项加入map中,即可完成求导过程。之后按项调用tostring方法,在main类进行整合之后形成输出。
对于此次的化简来说,我其实非常犹豫过是否要进行最终的化简,因为确实听到过很多化简容易tle的说法,而且对于大佬的设置熔断防止tle的做法又不太熟悉,就犹豫了很长时间。但是由于性能分20分的巨大诱惑,最终还是选择了进行简单化的优化。对
a*cos(x)**2和a*sin(x)**2;
a*cos(x)**2和a;
a*sin(x)**2和a;
这三种情况进行了一次遍历性的搜索,即总是匹配当前遍历所存在的可合并的情况,并且判断合并是否能够减少长度,是则合并,否则继续遍历。虽然这是个及其一般的方法,但终究还是让我抢了点性能分。
UML类图
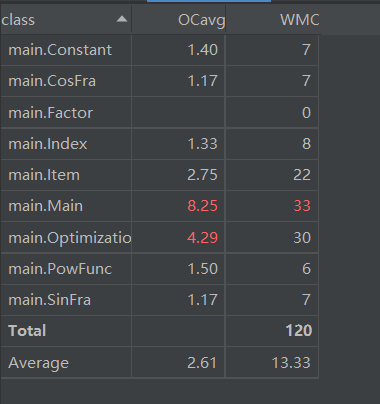
程序复杂度
反思
还是由于我在main类里面进行了大杂烩,而且每个函数都带点循环,所以main类依旧持续飘红(保证以后改掉.jpg)其次由于优化是最后加进去的单独类,其次优化的逻辑很一般,导致优化类也呈现刺眼的红色。
bug分析
很幸运此次我在公测和互测中也无伤通过。但是其实在写的时候,除优化外的程序部分由于写的比较细致,所以写完第一版的时候基本就没什么bug,但是在我加完抢分的优化类之后就出现了各种bug,比如hashmap里的项就单纯的加了进去,导致遇上同类项等就直接崩掉了等,其余很多不该出现的bug。不过幸好在中测结束前都找出了这些bug。
互测中我hack的bug,后来了解到,被hack的人的bug全部出现在优化部分,这提醒我们不能太贪?(手动捂脸)
第三次作业
需求分析
在第二次的需求上,新增加了多种函数的组合形式,以及加强了wf的判断。
设计思路
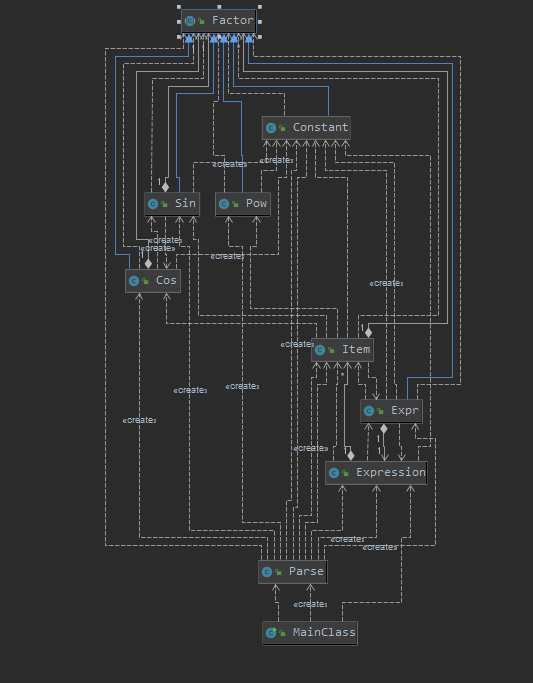
沿用第二次的框架,但是重新修改了解析输入部分,并为此单独开了一个类,其次新增Expr类作为表达式因子类,新增Expression类作为表达式类,内部存放多个Item对象。求导是,对总的表达式进行求导,而表达式又调用项的求导,项继续调用每个因子的求导,逐层调用求导,最后逐层返回,最后形成一个新的表达式。输出时,同样逐层调用tostring函数,逐层整合之后返回(最大限度缩短字符串输出),最后得到能够输出的字符串。
UML类图
程序复杂度
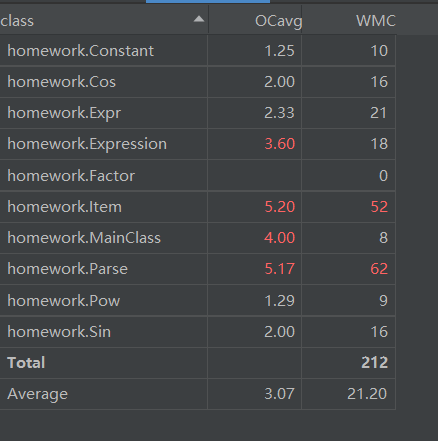
反思
首先是解析输入的方法我认为自己写的很差,一直想找一个比较清晰一点的解析方法,但是最后依然跟随了自己最初混乱不堪的解析思想,完成了解析,但是确实有点最后给这个类打补丁的嫌疑。其次当初没想着怎么优化就采用了Arraylist的形式存储因子和项,导致最后想要进行同类项合并的时候被迫遍历循环,于是就有了上面的几个飘红的点。
其次,我虽然实现了继承这个方法,但是课上所讲的工厂模式,我并没有很好的运用起来,顶多算个简单工厂模式,随用随new一个。
对于此次的化简,由于我这么分层的框架,要想达到最优的效果,就必须在每一层就进行一定的优化,比如解析表达式因子是,如果内层仍是表达式因子,那么就直接调用方法继续解析,在此吃掉一层括号,以及如果最终解析出来仅含一个因子的话就不返回表达式因子,而返回对应类型的因子等,必须逐层优化才可以达到最优。
bug分析
很遗憾,在此次强测wa了一个点,一个wf的情况没有判断出来。由于前两次空白字符都不怎么影响,所以我想这次在解析之前,先去掉空白字符再沿用以前的逻辑。然后事实告诉我,我最担心的考虑不完情况的事还是发生了。(以后一定不这么莽了,按照官方的表达式的正则解析来做) 然后由于互测无法提交wf的数据,所以我无伤通过。
互测中,我hack了两个人的程序,不该wf的数据却输出了wf,以及一个人的程序产生了tle,以此来看,wf的判断确实也是一个难点,以及逻辑复杂度在写程序的时候也一定要考虑到。
综合反思
测试方面:
此处感谢冯ty和乔sy大佬在第一次作业时提出的评测机思路,于是我拥有了人生中第一台自己写的“评测姬”,让自己的程序在第一次作业中错误率大幅下降。
我的测试思路,以黑盒测试为主,辅以手动数据。在理解指导书的情况下,自己手动出一些极端数据进行测试,以及我的评测机并不能测试wf的情况,所以必须手动出wf的数据以进行覆盖。(然鹅,事实证明,我手动出数据的能力还是不够orz)
对于互测阶段,对于能够容易读的代码,就好好读一读,借鉴思路,并辅以个别手动数据;对于实在无法分析的代码,我只能以黑盒测试为主。以及互测时,我秉承不提交同质bug的思想,在hack一个bug之后,之后能够再找到明确的非同质bug才会提交,否则不进行提交,所以我一般在互测时仅提交1-2个bug。
创建模式和重构的思考
对于继承、接口和多态,我使用了继承来整合因子部分,但是没有深入理解工厂模式,所以并没有在本单元作业中使用工厂模式,希望自己能够通过多多阅读大佬的优秀代码,继续深入的理解工厂模式的优点并加以利用。
对于重构部分,第一次作业可以说仍是一份面向过程的代码,在当时构思时其实并没有为以后的扩展留下空间和可能性,这确实是前期构思的缺陷。第二次重构时,我采用了继承的方法统合了因子类,也算是为第三次的扩展留下了接口。但是在解析输入和优化部分我并没有考虑到扩展和迭代,导致优化和解析部分,几乎每次作业都在重写。这也是我思路的不足之处。虽然我经历的第一单元作业的洗礼,但是我不得不承认,我在迭代和可扩展性方面仍然不是很能够理解。
心得体会
架构是一个程序最重要的东西,有了架构代码写起来会非常顺手,相反,写代码就会随想随写然后无数次删除重来。但是同样想要设计一个好的架构是一件不容易的事情。此处感谢讨论区的大佬们的思路分享让我受益颇多。
高内聚低耦合的思想,对代码的维护和错误的定位非常重要。由于我的代码相互之间耦合度太搞,所以每次debug就要从头开始一步一步会查找,效率极低。
写程序时一定注意细节问题,否则往往会debug到自闭然后再一次见识到自己的愚蠢。
最后,(开头请一定不能当真hhh)通过三周的oo学习,我真的收获颇丰
(特别是认识到自己的代码有多丑陋),希望自己能够在后面的学习中,学习更多的思想和方法使自己的代码有能够见人的一天。