方法一:每次取出两个不同的数,剩下的数字中重复出现次数超过一半的数字肯定,将规模缩小化。如果每次删除两个不同的数,这里当然不是真的把它们踢出数组,而是对于候选数来说,出现次数减一,对于其他数来说,循环遍历就行。在剩余的数字里,原最高频数出现的频率一样超过了50%,不断重复这个过程,最后剩下的将全是同样的数字,即最高频数。此算法避免了排序,时间复杂度只有O(n).
程序示例如下:
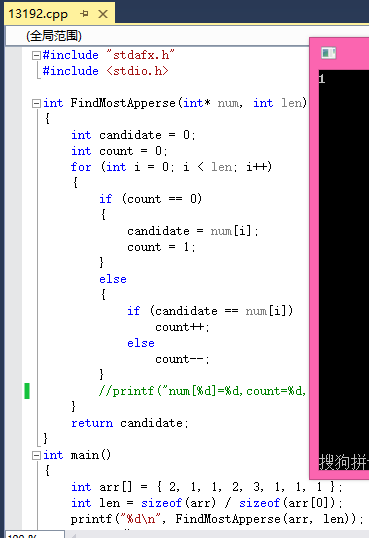
#include "stdafx.h"
#include <stdio.h>
int FindMostApperse(int* num, int len)
{
int candidate = 0;
int count = 0;
for (int i = 0; i < len; i++)
{
if (count == 0)
{
candidate = num[i];
count = 1;
}
else
{
if (candidate == num[i])
count++;
else
count--;
}
printf("num[%d]=%d,count=%d,candidate=%d
", i, num[i], count, candidate);
}
return candidate;
}
int main()
{
int arr[] = { 2, 1, 1, 2, 3, 1, 1, 1 };
int len = sizeof(arr) / sizeof(arr[0]);
printf("%d
", FindMostApperse(arr, len));
getchar();
return 0;
}
效果如图:
方法二:Hash法。首先创建一个hash_map,其中key为数组元素值,value为此数出现的次数。遍历一遍数组,用hash_map统计每个数出现的次数,并用两个值存储目前出现次数最多的数和对应出现的次数,此时的时间复杂度为O(n),空间复杂度为O(n),满足题目的要求。
方法三:原创,用map,不知时间复杂度是否符合要求,代码如下:
#include "stdafx.h"
#include <iostream>
#include <map>
using namespace std;
bool findOverHalf(int *a, int size, int &val)
{
if (a == NULL || size <= 0)
return false;
map<int, int> m;
for (int i=0; i < size; i++)
{
m[a[i]]++;
if (m[a[i]]>size / 2)
{
val = a[i];
return true;
}
}
return false;
}
int main()
{
int val = 0;
int a[] = { 1, 5, 4, 3, 4, 4, 0, 5, 5, 5, 5 };
if (findOverHalf(a, 11, val))
cout << val << endl;
else
cout << "无出现次数过半的数" << endl;
getchar();
return 0;
}