DOM是文档对象,它是把整个页面封装成一个对象。页面是由很多节点组成的,节点又包括元素,属性,文本。获取页面元素的方式有三种。
第一: getElementById,通过Id值来获取整个标签的所有属性。

第二: getElementsByTagName,通过标签名值来获取整个标签的所有属性,它获得元素会以数组方式存在,你要取用时,要用数组的方法取。

第三: getElementsByClassName,通过类名来获取整个标签的所有属性,它获得元素会以数组方式存在,你要取用时,要用数组的方法取,但他在数组中显示的和第二种有点不一样,它是一个标签名带一个类名当做一个数组值,这种兼容性太强,一般很少用。


事件:就是文档或浏览器窗口发生的一些特定交互瞬间,它有三要素:事件源,事件名称,事件处理程序。注册事件有两种,行内式,内嵌式。on是注册事件。
第一种行内式:

第二种是内嵌式:
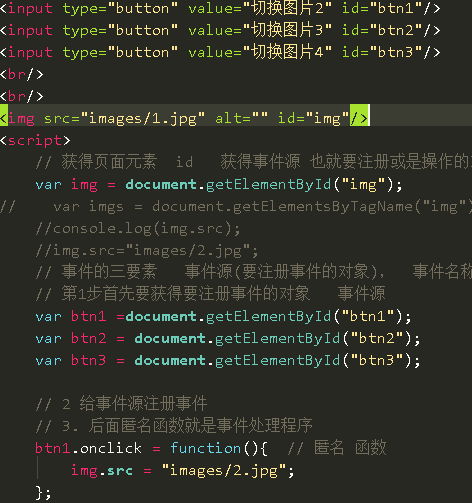
阻止a的跳转我们可以用return false。
获取页面文本的api有两种:innerText ,innerHTML.
1. 使用innerText与innerHTML都可以获得页面元素之间的内容
2. 不同的是innerText只会获取文本信息 ,而innerHTML会将标签之间的标签也获取而,而且是原样输出

innerText在早期的火狐浏览器中是不支持的,早期的火狐浏览器只支持textContent,新版本的火狐浏览器两者都支持。
innerText设置的时候,会原样输出,

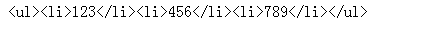
因为innerText会将程序中的大于号,小于号转义了

而innerHTML会将里面的标签渲染成正常的HTML标签 显示出来

