今天同学发了一份腾讯2013校园招聘软件开发类的笔试题(╮(╯▽╰)╭可惜是拍的图片)来给我做,我一看到就崩溃了,大部分都不会做,考查的计算机基础知识主要有C语言、算法和数据结构、计算机操作系统、计算机网络、数据库,个别一两题涉及到编译原理,分数布局是不定项选择题60分(20题)、填空题40分(7小题,10空,每空4分)、附加题(分为web前端方法和其他方向),其中web前端方法附加题有一道是这样的:编写一个javascript函数,把URL解析为一个结构与页面中的javascript location的对象相似的对象实体。
如:输入url串为 "http://www.qq.com/index.html?key1=1&key2=2&key3=3";
最后输出的对象是:
{ "protocol": "http", "hostname": "www.qq.com", "pathname": "/index.html", "query": "?key1=1&key2=2&key3=3" }
注:如果熟悉url规范,对于更复杂的url,可以尝试让解析输出的对象有更多便于使用的属性字段。
当看到题目,脑海里就立刻出现了该题大概是考查js对字符串、数组的一些操作的画面,对于location对象的一些属性,我想接触过js的人都比较熟悉,何况像我这种菜鸟,不清楚的去度娘、google搜搜都会出现一大把介绍,这里就不介绍了。题目要求是模拟location对象的实体对象只需拥有四个属性protocol、hostname、pathname、query即可,但我在实现时增加了一些属性:如port、hash、查询字符串对象来增加该实体对象的健壮性(题目注明部分的实现),由于对正则表达式不太熟悉,所以只少量使用了正则(据说正则有时效率挺高的),并且性能方面也没有进行优化,如果有更好的方案,欢迎大神们给出建议,废话不多说,下面是我的实现思路,贴上代码:
// 对形如http://www.qq.com:80/index.html?key1=1&key2=2&key3=3#hcy的url字符串进行解析,并返回类似location对象的实体对象 var parseUrl = function() { var pos1, // 保存":"字符的位置(注意是前半部分字符串里的":") pos2, // 保存"/"字符的位置 pos3, // 保存"?"字符的位置 pos4, // 保存"#"字符的位置 pos5, // 保存":"字符的位置(注意是后半部分字符串里的":") protocol, // 协议 hostname, // 主机名 port, // 端口 pathname, // 路径 queryStr, // 查询字符串 hash, // 锚标记信息 matchArr, beforeStr, // 前半部分字符串 afterStr, // 后半部分字符串 queryObj = {}, // 保存查询字符串基于名值对(key=value)的数据对象 url = arguments[0]; // 获取url字符串 matchArr = url ? url.split("//") : alert("请输入url"); // 根据"//"分隔符把字符串分隔成数组的两项 beforeStr = matchArr[0]; afterStr = matchArr[1]; // 获取相应字符位置,注意:当查找的字符串不存在时返回-1 pos1 = beforeStr.indexOf(":"); pos2 = afterStr.indexOf("/"); pos3 = afterStr.indexOf("?"); pos4 = afterStr.indexOf("#"); pos5 = afterStr.indexOf(":"); // 获取协议 protocol = pos1 > -1 ? beforeStr.slice(0, pos1) : ""; // 获取主机名 hostname = pos5 > -1 ? afterStr.slice(0, pos5) : afterStr.slice(0); // 获取端口,默认为80(输出空字符串),其他正常输出 port = pos5 > -1 ? pos2 > -1 ? afterStr.slice(pos5 + 1, pos2) : afterStr.slice(pos5 + 1) : ""; port = parseInt(port) === 80 ? "" : port; // 获取路径,注意对空值进行处理 pathname = pos3 > -1 && (pos2 > -1) ? afterStr.slice(pos2, pos3) : pos2 > -1 ? afterStr.slice(pos2) : ""; // 获取查询字符串,注意对空值进行处理 queryStr = pos4 > -1 ? (pos3 > -1) && afterStr.slice(pos3, pos4) : pos3 > -1 ? afterStr.slice(pos3) : ""; hash = pos4 > -1 ? afterStr.slice(pos4) : ""; // 获取锚(存在时直接返回,不存在时返回空字符串) // 对queryString进行处理 var arr = queryStr ? queryStr.replace(/\?*/,"").split("&") : [], item, name, value; for (var i = 0; i < arr.length; i++) { item = arr[i].split("="); name = item[0], // 获取名值对的名称 value = item[1]; // 获取名值对的值 // 把每一"名值对"构造成数据对象 queryObj[name] = value; } // 返回一个包含上述属性的对象 return { protocol: protocol, hostname: hostname, port: port, pathname: pathname, queryStr: queryStr, hash: hash, queryObj: queryObj }; };
测试代码:
// 测试 var url1 = "http://", url2 = "http://www.qq.com", url3 = "http://www.qq.com:80", url4 = "http://www.qq.com:81", url5 = "http://www.qq.com:81/index.html", url6 = "http://www.qq.com:81/index.html?key1=1&key2=2&key3=3", url7 = "http://www.qq.com:81/index.html?key1=1&key2=2&key3=3#hcy"; var entityObj = parseUrl(url7); // 获取返回的对象 for (var k in entityObj) { // 对查询字符串对象进行处理 if (typeof entityObj[k] === "object") { for (var name in entityObj[k]) { console.log(name + ":\t" + entityObj[k][name]); } } else if (entityObj.hasOwnProperty(k) || typeof k !== "function") { console.log(k + ":\t" + entityObj[k]); } }
测试结果:
1、对于url1字符串:
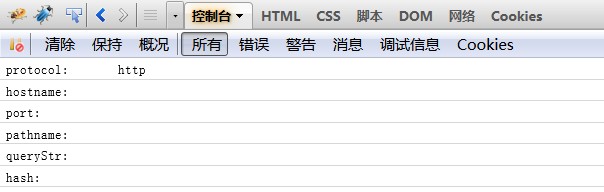
2、对于url2字符串
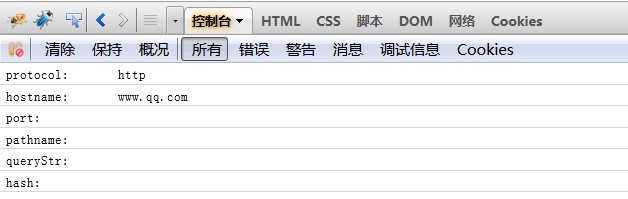
3、对于url3字符串(结果和url2的相同:因为port默认为80,且为80时输出空字符串,保持与location对象的port属性一致)
4、对于url4字符串
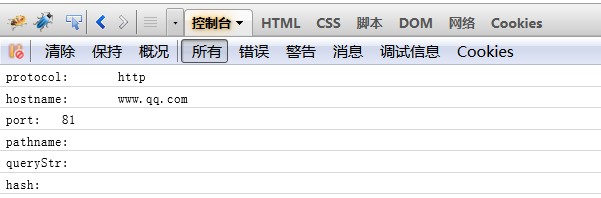
5、对于url5字符串
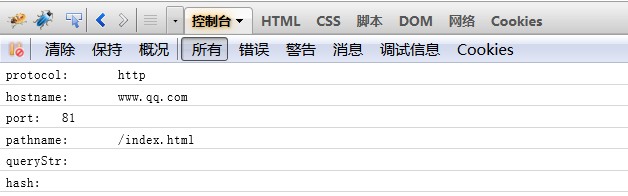
6、对于url6字符串(注意:结果把查询字符串对象也输出了)
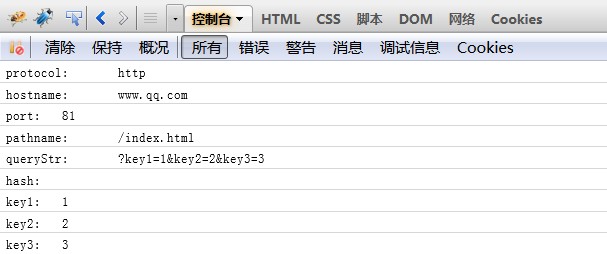
7、同理对于url7
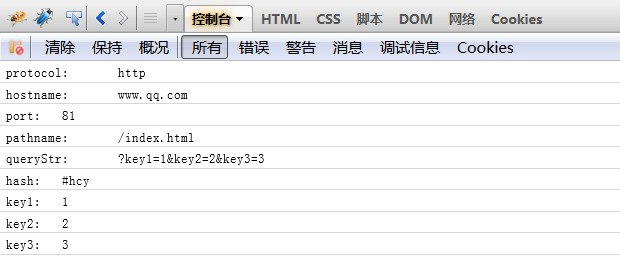
尼玛^_^,终于截完7个图了,手都软了。。。。突然发觉忘记吃饭了
结语:又花了2个多小时从编写代码到写完blog,(~ o ~)~zZ,对于该题的实现过程,可能有一些因素没考虑到,也可能有各种bug,希望得到大家的建议,不过感觉腾讯的笔试题分量真的很高,接下来的日子要好好复习计算机基础知识了,为了9月份的tencent校园招聘,哥也要奋斗了,虽然起点落后了很多,不过喜欢努力为目标奋斗的过程,做一个有梦想的人吧!good good study,day day up~