论文题目:YOLOv4: Optimal Speed and Accuracy of Object Detection
文献地址:https://arxiv.org/pdf/2004.10934.pdf
源码地址:https://github.com/AlexeyAB/darknet

YOLOv4中谈及了一些B-Box回归损失的方法,诸如MSE(L2 loss),Smooth L1 loss,IoU loss, GIoU loss,DIoU loss,CIoU loss。本篇主要介绍目标检测任务中近几年这些损失函数的具体操作。
MAE(L1 loss),MSE(L2 loss)与Smooth L1 loss
MAE和MSE在回归任务中做损失函数早已屡见不鲜,
- MAE(L1 loss):
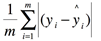
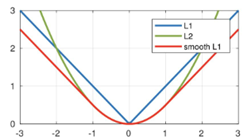
其图像是与y轴对称的折线:
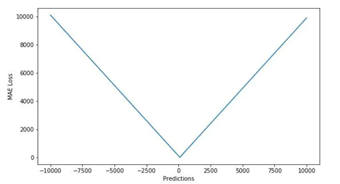
- MSE(L2 loss):
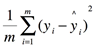
其图像为一条与y轴对称且过原点的抛物线:

对于上述两种损失函数中,L1损失函数的导数为常数,在训练后期,当损失数值变小后,如果学习率不变,损失函数会在稳定值附近波动,很难收敛到跟高的精度。L2损失函数的导数与损失有关,在训练初期,当损失较大时,其导数也很大,会造成训练的不稳定。
Smooth L1 loss便是针对MSE和MAE的这些不足。Smooth L1 loss 的提出是在Fast RCNN中:
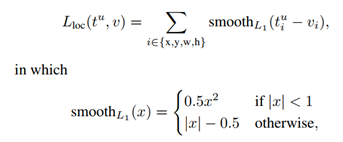
其中,vi表示ground-true 框的坐标,ti表示预测的框的坐标(其中包含x,y,w,h)。
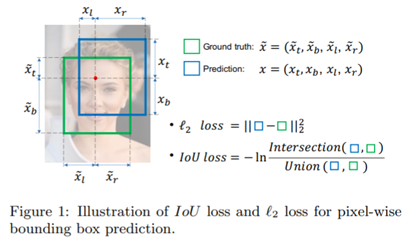
上述的三种loss方法在计算B-Box损失时,会存在一些问题:
- 将框的坐标以相对独立的方式进行损失的计算,这种做法的假设是这四个坐标相对独立,但实际上是有一定关联的。
- 不同的检测框可能有相同大小的Smooth L1 loss,不能很好的衡量检测框。
IoU loss
Smooth L1 loss不能很好的衡量预测框与ground true 之间的关系,相对独立的处理坐标之间的关系。可能出现Smooth L1 loss相同,但实际IoU不同的情况。
因此,提出IoU loss,将四个点构成的box看成一个整体进行损失的衡量。通过计算两个框的交并比,再求-ln(IoU),当然,很多时候可以直接定义IoU loss = 1-IoU。
算法流程如下:

YOLOv3中使用的便是IoU loss。
GIoU loss

文献地址:https://arxiv.org/pdf/1902.09630.pdf
源码地址:https://github.com/generalized-iou/g-darknet
IoU loss 其实并不完美,也会存在一些问题:
- IoU loss仅能衡量两个框相交的情况,而不能反应预测框与目标框不相交的情况。即当IoU(a, b) = 0时,是不能反应a, b的远近。
- 即使具有相同大小的交并比,IoU loss也不能很好的衡量两个框是如何相交的。如下图所示,具有相同的IoU=0.33,相交的情况却大不相同。
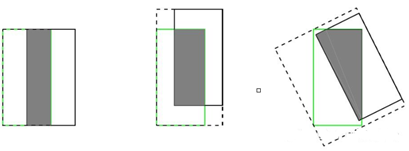
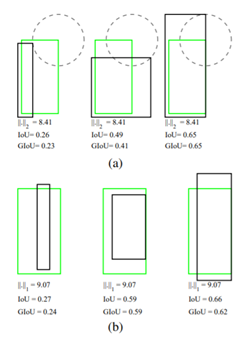
GIoU loss的提出便是针对上述问题,GIoU中对于上述三幅图,GIoU分别=0.33, 0.24, -0.1。感觉当框的对齐方向更好一些时,GIoU的值会更高一些。下图可以对比一下MSE、IOU与GIoU的区别:
GIoU的算法流程:

通过上述算法流程可以看出,GIoU≤IoU; 并且,LGIoU = 1-GIoU。
C表示可以将A,B包含在内的最小的封闭形状,这样就可以衡量预测框与真实框不相交的情况。添加了C中非A、B区域部分占C的比例,从而添加不想交和相交情况的约束。
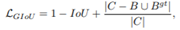
具体的计算方式:

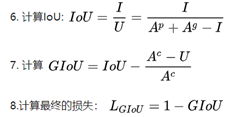
DIoU loss

文献地址:https://arxiv.org/pdf/1911.08287.pdf
DIoU可以使YOLOv3涨近3个百分点。https://github.com/Zzh-tju/DIoU-darknet
GIoU同样也不是完美的,DIoU loss的作者发现当预测框被目标框完全包裹的时候,IoU和GIoU是一样的,并不能区分此时的位置关系,此时GIoU退化为IoU。
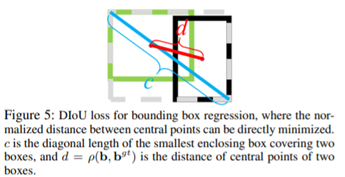
因此,作者提出的DIoU引入了中心点归一化距离的操作。如下图所示,绿色框表示目标框,红色框表示预测框。从下图可以略微感觉到,DIoU loss的计算会包含中心点的指引。
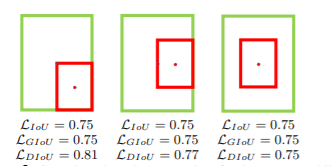
在上述完全包裹的情况下,C的计算是一样的,导致在优化时,对于不同的情况,并不能给予合适的惩罚项,导致放慢了收敛速度。
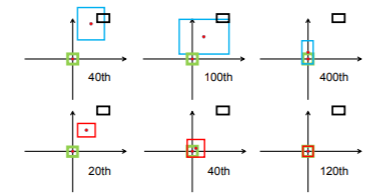
作者也给出了在不同代数下,DIoU和GIoU收敛情况的可视化。如下图所示,第一行为GIoU的各代收敛情况;第二行为DIoU的各代收敛情况。绿色框为真实框,黑色框为anchor box,蓝色框为GIoU loss 产生的预测框,红色框为DIoU loss产生的预测框。可以看出,在DIoU loss 的指引下,仅需要120代,预测框便可以很好的满足真实框。【损失函数其实就是你想让它按照怎样的方式去学习,指引的越好,收敛速度越快】
DIoU loss 的求取:
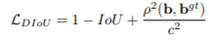
这个损失函数中,b和b(gt)表示anchor框和目标框的中心点,ρ表示两个中心点的欧式距离(如下图标记d)。c代表的是可以同时覆盖Anchor框和目标框的最小矩形的对角线距离(如下图标记c)。因此DIoU中对Anchor框和目标框之间的归一化距离进行了建模。
使用中心点间距离d和覆盖矩形对角线距离c的比值衡量彼此之间的关系,即可以对不相交有约束,也可以对包含有约束。这样的指引,可以提供移动方向,加快收敛速度。
CIoU loss
DIoU loss 文章中还提出了一种CIoU loss(Complete IoU loss),作者归纳了一个好的目标框回归损失应该考虑三个重要的几何因素:重叠面积、中心点距离和长宽比。
- GIoU loss 解决了IoU为0时,无法优化的问题;
- DIoU loss 在GIoU Loss的基础上考虑了边界框的重叠面积和中心点距离。
所以,还没有考虑长宽比一致性的约束,即CIoU loss 在DIoU loss的基础上添加了长宽比的约束αv:
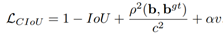
其中,α作为一个trade-off参数:
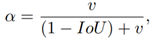
参数v用于衡量长宽比一致性:
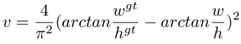
下图展示了DIoU和CIoU在YOLOv3性能上的提升。
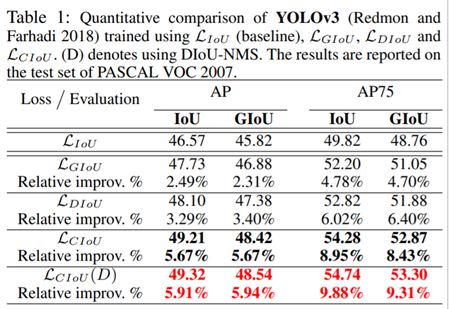
YOLOv4中使用的便是DIoU loss!
AlexyAB大神在源码的维护中添加了CIoU loss,使用CIoU loss可以进一步提升模型的精度!
yolov3/-tiny同样可以修改原先的IoU loss为CIoU loss,也可以为yolov3/-tiny提升精度!