第一、Mybatis介绍
MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis 。2013年11月迁移到Github。
MyBatis是一个优秀的持久层框架,它对jdbc的操作数据库的过程进行封装,使开发者只需要关注 SQL 本身,而不需要花费精力去处理例如注册驱动、创建connection、
创建statement、手动设置参数、结果集检索等jdbc繁杂的过程代码。Mybatis通过xml或注解的方式将要执行的各种statement(statement、preparedStatemnt、CallableStatement)配置起来,
并通过java对象和statement中的sql进行映射生成最终执行的sql语句,最后由mybatis框架执行sql并将结果映射成java对象并返回。
学习网址http://www.mybatis.org/mybatis-3/zh/getting-started.html
第二、使用JDBC编程总结
2.1数据库脚本
DROP TABLE IF EXISTS `orders`;
CREATE TABLE `orders` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL COMMENT '下单用户id',
`number` varchar(32) NOT NULL COMMENT '订单号',
`createtime` datetime NOT NULL COMMENT '创建订单时间',
`note` varchar(100) DEFAULT NULL COMMENT '备注',
PRIMARY KEY (`id`),
KEY `FK_orders_1` (`user_id`),
CONSTRAINT `FK_orders_id` FOREIGN KEY (`user_id`) REFERENCES `user` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
INSERT INTO `orders` VALUES ('3', '1', '1000010', '2015-02-04 13:22:35', null);
INSERT INTO `orders` VALUES ('4', '1', '1000011', '2015-02-03 13:22:41', null);
INSERT INTO `orders` VALUES ('5', '10', '1000012', '2015-02-12 16:13:23', null);
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(32) NOT NULL COMMENT '用户名称',
`birthday` date DEFAULT NULL COMMENT '生日',
`sex` char(1) DEFAULT NULL COMMENT '性别',
`address` varchar(256) DEFAULT NULL COMMENT '地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=27 DEFAULT CHARSET=utf8;
INSERT INTO `user` VALUES ('1', '王五', null, '2', null);
INSERT INTO `user` VALUES ('10', '张三', '2014-07-10', '1', '北京市');
INSERT INTO `user` VALUES ('16', '张小明', null, '1', '河南郑州');
INSERT INTO `user` VALUES ('22', '陈小明', null, '1', '河南郑州');
INSERT INTO `user` VALUES ('24', '张三丰', null, '1', '河南郑州');
INSERT INTO `user` VALUES ('25', '陈小明', null, '1', '河南郑州');
INSERT INTO `user` VALUES ('26', '王五', null, null, null);
2.2创建工程
1.创建一个maven工程
2.引入mysql依赖
<!-- mysql驱动包 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.29</version>
</dependency>
2.3jdbc编程步骤:
1、 加载数据库驱动
2、 创建并获取数据库链接
3、 创建jdbc statement对象
4、 设置sql语句
5、 设置sql语句中的参数(使用preparedStatement)
6、 通过statement执行sql并获取结果
7、 对sql执行结果进行解析处理
8、 释放资源(resultSet、preparedstatement、connection)
2.4jdbc程序
public static void main(String[] args) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
//加载数据库驱动
Class.forName("com.mysql.jdbc.Driver");
//通过驱动管理类获取数据库链接
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/mybatis?characterEncoding=utf-8", "root", "root");
//定义sql语句 ?表示占位符
String sql = "select * from user where username = ?";
//获取预处理statement
preparedStatement = connection.prepareStatement(sql);
//设置参数,第一个参数为sql语句中参数的序号(从1开始),第二个参数为设置的参数值
preparedStatement.setString(1, "王五");
//向数据库发出sql执行查询,查询出结果集
resultSet = preparedStatement.executeQuery();
//遍历查询结果集
while(resultSet.next()){
System.out.println(resultSet.getString("id")+" "+resultSet.getString("username"));
}
} catch (Exception e) {
e.printStackTrace();
}finally{
//释放资源
if(resultSet!=null){
try {
resultSet.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(preparedStatement!=null){
try {
preparedStatement.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(connection!=null){
try {
connection.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
上边使用jdbc的原始方法(未经封装)实现了查询数据库表记录的操作。
2.5JDBC问题总结
1、 数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库链接池可解决此问题。
2、 Sql语句在代码中硬编码,造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。
3、 使用preparedStatement向占有位符号传参数存在硬编码,因为sql语句的where条件不一定,可能多也可能少,修改sql还要修改代码,系统不易维护。
4、 对结果集解析存在硬编码(查询列名),sql变化导致解析代码变化,系统不易维护,如果能将数据库记录封装成pojo对象解析比较方便。
第三、MyBatis架构

1、 mybatis配置
SqlMapConfig.xml,此文件作为mybatis的全局配置文件,配置了mybatis的运行环境等信息。
mapper.xml文件即sql映射文件,文件中配置了操作数据库的sql语句。此文件需要在SqlMapConfig.xml中加载。
2、 通过mybatis环境等配置信息构造SqlSessionFactory即会话工厂
3、 由会话工厂创建sqlSession即会话,操作数据库需要通过sqlSession进行。
4、 mybatis底层自定义了Executor执行器接口操作数据库,Executor接口有两个实现,一个是基本执行器、一个是缓存执行器。
5、 Mapped Statement也是mybatis一个底层封装对象,它包装了mybatis配置信息及sql映射信息等。mapper.xml文件中一个sql对应一个Mapped Statement对象,sql的id即是Mapped statement的id。
6、 Mapped Statement对sql执行输入参数进行定义,包括HashMap、基本类型、pojo,Executor通过Mapped Statement在执行sql前将输入的java对象映射至sql中,输入参数映射就是jdbc编程中对preparedStatement设置参数。
7、 Mapped Statement对sql执行输出结果进行定义,包括HashMap、基本类型、pojo,Executor通过Mapped Statement在执行sql后将输出结果映射至java对象中,输出结果映射过程相当于jdbc编程中对结果的解析处理过程。
第四、MyBatis入门程序
4.1需求
实现以下功能:
根据用户id查询一个用户信息
根据用户名称模糊查询用户信息列表
添加用户
更新用户
删除用户
4.2工程搭建
1.创建工程
2.引入maven依赖
<dependencies>
<!-- mybatis核心包 -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.3.0</version>
</dependency>
<!-- mysql驱动包 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.29</version>
</dependency>
<!-- junit测试包 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
4.log4j.properties
在classpath下创建log4j.properties
# Global logging configuration
log4j.rootLogger=DEBUG, stdout
# Console output...
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
mybatis默认使用log4j作为输出日志信息。
5.SqlMapConfig.xml
在classpath下创建SqlMapConfig.xml,如下:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- 和spring整合后 environments配置将废除-->
<environments default="development">
<environment id="development">
<!-- 使用jdbc事务管理-->
<transactionManager type="JDBC" />
<!-- 数据库连接池-->
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?characterEncoding=utf-8" />
<property name="username" value="root" />
<property name="password" value="root" />
</dataSource>
</environment>
</environments>
</configuration>
SqlMapConfig.xml是mybatis核心配置文件,上边文件的配置内容为数据源、事务管理。
6.PO类
Po类作为mybatis进行sql映射使用,po类通常与数据库表对应,User.java如下:
Public class User {
private int id;
private String username;// 用户姓名
private String sex;// 性别
private Date birthday;// 生日
private String address;// 地址
}
7.sql映射文件
在classpath下的sqlmap目录下创建sql映射文件Users.xml:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="test">
</mapper>
namespace :命名空间,用于隔离sql语句。
8.加载映射文件
mybatis框架需要加载映射文件,将Users.xml添加在SqlMapConfig.xml,如下:
<mappers>
<mapper resource="sqlmap/User.xml"/>
</mappers>
4.3根据ID查询
1.映射文件
在user.xml中添加:
<!-- 根据id获取用户信息 -->
<select id="findUserById" parameterType="int" resultType="cn.itcast.mybatis.po.User">
select * from user where id = #{id}
</select>
parameterType:定义输入到sql中的映射类型,#{id}表示使用preparedstatement设置占位符号并将输入变量id传到sql。
resultType:定义结果映射类型。
2.测试环境
public class Mybatis_first {
//会话工厂
private SqlSessionFactory sqlSessionFactory;
@Before
public void createSqlSessionFactory() throws IOException {
// 配置文件
String resource = "SqlMapConfig.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
// 使用SqlSessionFactoryBuilder从xml配置文件中创建SqlSessionFactory
sqlSessionFactory = new SqlSessionFactoryBuilder()
.build(inputStream);
}
// 根据 id查询用户信息
@Test
public void testFindUserById() {
// 数据库会话实例
SqlSession sqlSession = null;
try {
// 创建数据库会话实例sqlSession
sqlSession = sqlSessionFactory.openSession();
// 查询单个记录,根据用户id查询用户信息
User user = sqlSession.selectOne("test.findUserById", 10);
// 输出用户信息
System.out.println(user);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (sqlSession != null) {
sqlSession.close();
}
}
}
}
4.4根据用户名查询用户信息
1.映射文件
在user.xml中添加:
<!-- 自定义条件查询用户列表 -->
<select id="findUserByUsername" parameterType="java.lang.String"
resultType="cn.itcast.mybatis.po.User">
select * from user where username like '%${value}%'
</select>
parameterType:定义输入到sql中的映射类型,${value}表示使用参数将${value}替换,做字符串的拼接。
注意:如果是取简单数量类型的参数,括号中的值必须为value
resultType:定义结果映射类型。
2.测试环境
// 根据用户名称模糊查询用户信息
@Test
public void testFindUserByUsername() {
// 数据库会话实例
SqlSession sqlSession = null;
try {
// 创建数据库会话实例sqlSession
sqlSession = sqlSessionFactory.openSession();
// 查询单个记录,根据用户id查询用户信息
List<User> list = sqlSession.selectList("test.findUserByUsername", "张");
System.out.println(list.size());
} catch (Exception e) {
e.printStackTrace();
} finally {
if (sqlSession != null) {
sqlSession.close();
}
}
}
4.5小结
1.#{}和${}区别
#{}表示一个占位符号,通过#{}可以实现preparedStatement向占位符中设置值,自动进行java类型和jdbc类型转换,#{}可以有效防止sql注入。
#{}可以接收简单类型值或pojo属性值。 如果parameterType传输单个简单类型值,#{}括号中可以是value或其它名称。
${}表示拼接sql串,通过${}可以将parameterType 传入的内容拼接在sql中且不进行jdbc类型转换, ${}可以接收简单类型值或pojo属性值,
如果parameterType传输单个简单类型值,${}括号中只能是value。
2.parameterType和resultType
parameterType:指定输入参数类型,mybatis通过ognl从输入对象中获取参数值拼接在sql中。
resultType:指定输出结果类型,mybatis将sql查询结果的一行记录数据映射为resultType指定类型的对象。
3.selectOne和selectList
selectOne查询一条记录,如果使用selectOne查询多条记录则抛出异常:
org.apache.ibatis.exceptions.TooManyResultsException: Expected one result (or null) to be returned by selectOne(), but found: 3
at org.apache.ibatis.session.defaults.DefaultSqlSession.selectOne(DefaultSqlSession.java:70)
selectList可以查询一条或多条记录。
4.6添加用户
1.映射文件
在SqlMapConfig.xml中添加:
<!-- 添加用户 -->
<insert id="insertUser" parameterType="cn.itcast.mybatis.po.User">
insert into user(username,birthday,sex,address)
values(#{username},#{birthday},#{sex},#{address})
</insert>
2.测试程序
// 添加用户信息
@Test
public void testInsert() {
// 数据库会话实例
SqlSession sqlSession = null;
try {
// 创建数据库会话实例sqlSession
sqlSession = sqlSessionFactory.openSession();
// 添加用户信息
User user = new User();
user.setUsername("张小明");
user.setAddress("河南郑州");
user.setSex("1");
user.setPrice(1999.9f);
sqlSession.insert("test.insertUser", user);
//提交事务
sqlSession.commit();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (sqlSession != null) {
sqlSession.close();
}
}
}
3.mysql自增主键返回
通过修改sql映射文件,可以将mysql自增主键返回:
<insert id="insertUser" parameterType="cn.itcast.mybatis.po.User">
<!-- selectKey将主键返回,需要再返回 -->
<selectKey keyProperty="id" order="AFTER" resultType="java.lang.Integer">
select LAST_INSERT_ID()
</selectKey>
insert into user(username,birthday,sex,address)
values(#{username},#{birthday},#{sex},#{address});
</insert>
添加selectKey实现将主键返回
keyProperty:返回的主键存储在pojo中的哪个属性
order:selectKey的执行顺序,是相对与insert语句来说,由于mysql的自增原理执行完insert语句之后才将主键生成,所以这里selectKey的执行顺序为after
resultType:返回的主键是什么类型
LAST_INSERT_ID():是mysql的函数,返回auto_increment自增列新记录id值。
或者:
<insert id="insertUser" parameterType="cn.itcast.mybatis.po.User" useGeneratedKeys="true" keyProperty="id">
insert into user(username,birthday,sex,address)
values(#{username},#{birthday},#{sex},#{address});
</insert>
(仅对 insert 和 update 有用)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系数据库管理系统的自动递增字段),默认值:false。
4. Mysql使用 uuid实现主键
需要增加通过select uuid()得到uuid值
<insert id="insertUser" parameterType="cn.itcast.mybatis.po.User">
<selectKey resultType="java.lang.String" order="BEFORE"
keyProperty="id">
select uuid()
</selectKey>
insert into user(id,username,birthday,sex,address)
values(#{id},#{username},#{birthday},#{sex},#{address})
</insert>
注意这里使用的order是“BEFORE”
4.7删除用户
1.映射文件
<!-- 删除用户 -->
<delete id="deleteUserById" parameterType="int">
delete from user where id=#{id}
</delete>
2.测试程序
// 根据id删除用户
@Test
public void testDelete() {
// 数据库会话实例
SqlSession sqlSession = null;
try {
// 创建数据库会话实例sqlSession
sqlSession = sqlSessionFactory.openSession();
// 删除用户
sqlSession.delete("test.deleteUserById",18);
// 提交事务
sqlSession.commit();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (sqlSession != null) {
sqlSession.close();
}
}
}
4.8修改用户
1.映射文件
<!-- 更新用户 -->
<update id="updateUser" parameterType="cn.itcast.mybatis.po.User">
update user set username=#{username},birthday=#{birthday},sex=#{sex},address=#{address}
where id=#{id}
</update>
2.测试程序
// 更新用户信息
@Test
public void testUpdate() {
// 数据库会话实例
SqlSession sqlSession = null;
try {
// 创建数据库会话实例sqlSession
sqlSession = sqlSessionFactory.openSession();
// 添加用户信息
User user = new User();
user.setId(16);
user.setUsername("张小明");
user.setAddress("河南郑州");
user.setSex("1");
user.setPrice(1999.9f);
sqlSession.update("test.updateUser", user);
// 提交事务
sqlSession.commit();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (sqlSession != null) {
sqlSession.close();
}
}
}
4.9Mybatis解决jdbc编程的问题
1、 数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库链接池可解决此问题。
解决:在SqlMapConfig.xml中配置数据链接池,使用连接池管理数据库链接。
2、 Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。
解决:将Sql语句配置在XXXXmapper.xml文件中与java代码分离。
3、 向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需要和参数一一对应。
解决:Mybatis自动将java对象映射至sql语句,通过statement中的parameterType定义输入参数的类型。
4、 对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便。
解决:Mybatis自动将sql执行结果映射至java对象,通过statement中的resultType定义输出结果的类型。
4.10、MyBatis 的工作流程分析
1、获取SqlSessionFactory对象
解析配置文件保存到Configuration对象里面,返回包含Confuguration的DefaultSqlSessionFactory对象;
注意:【MapperStatement】:代表一个增删查改的详细信息
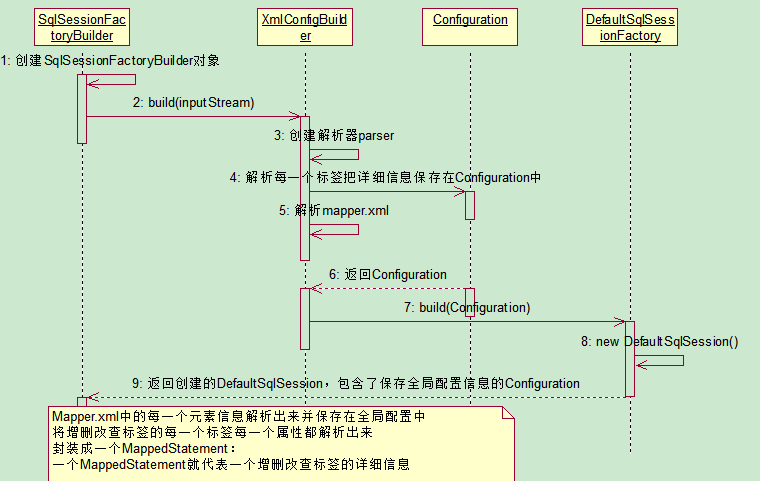
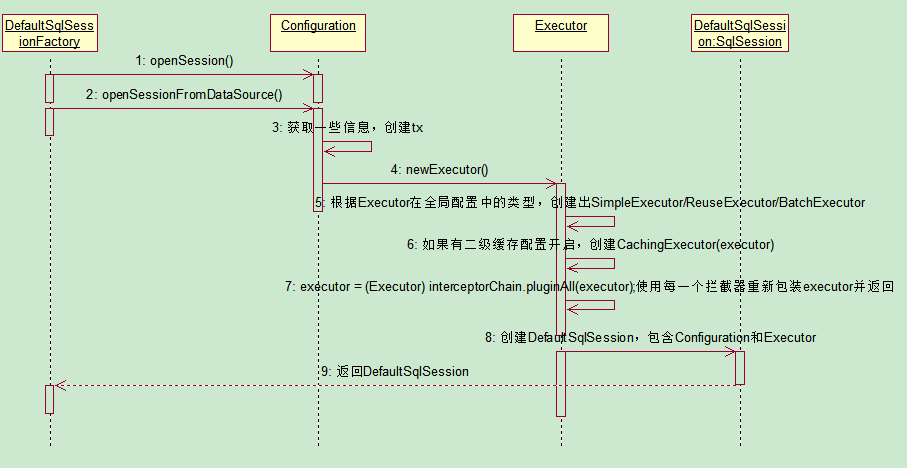
2、获取SqlSession对象
返回的是默认的sqlSessfaion对象,包含了Eexcutor对象和Configuration对象,事物也是在这步骤创建的
返回Eexcutor对象
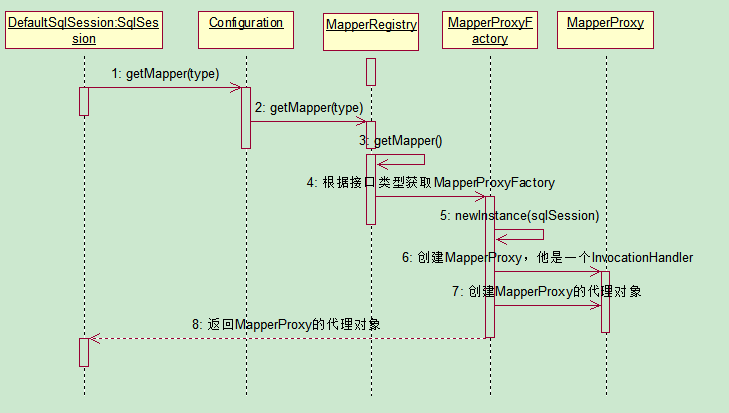
3、获取接口代理对象(MapperProxy)
getMapper,使用MapperProxyFactory工厂创建了一个MapperProxy的代理对象
代理对象里面包含了,DefaultSqlSession(Executor)
4、执行增删查改方法
查询流程:
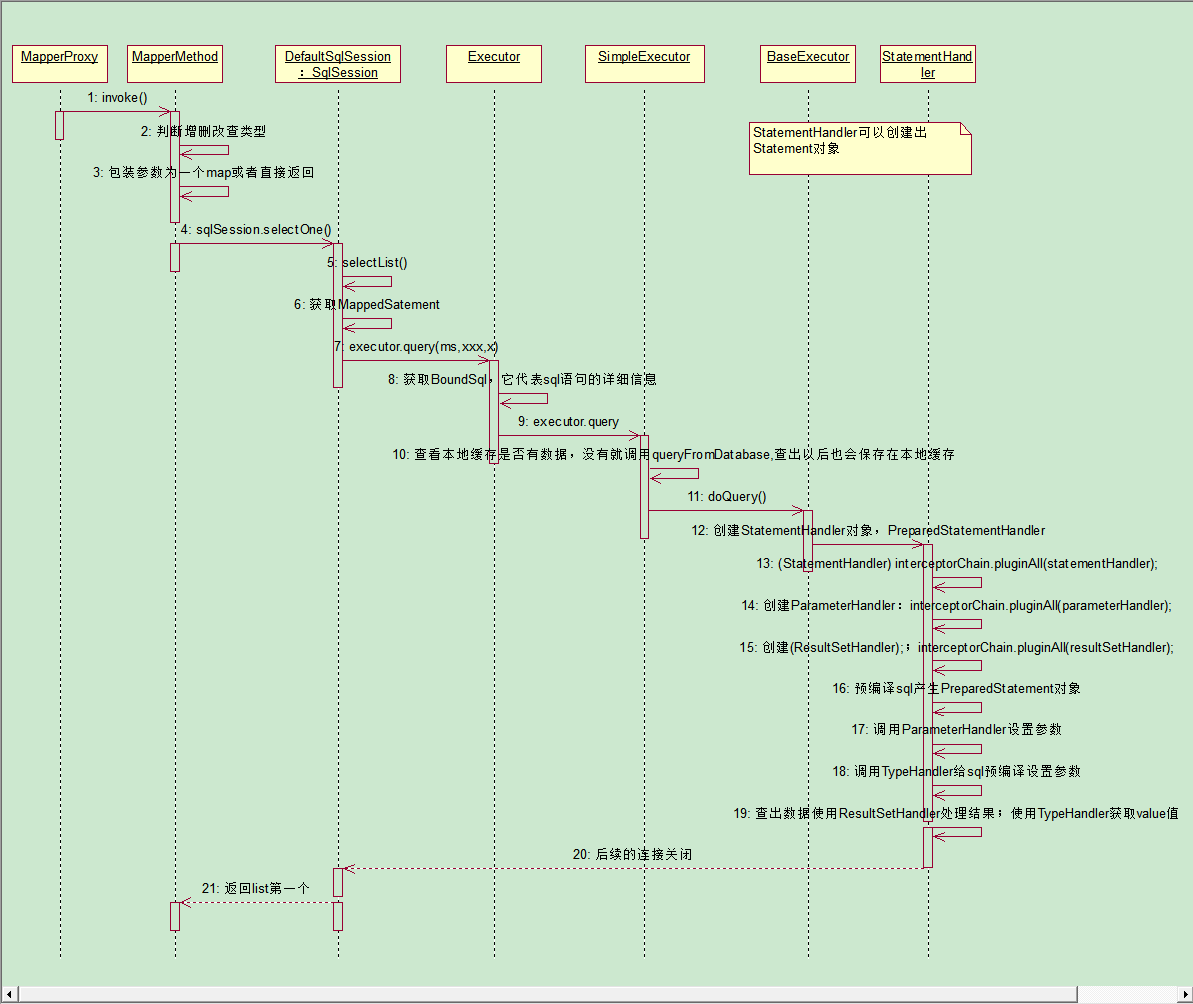
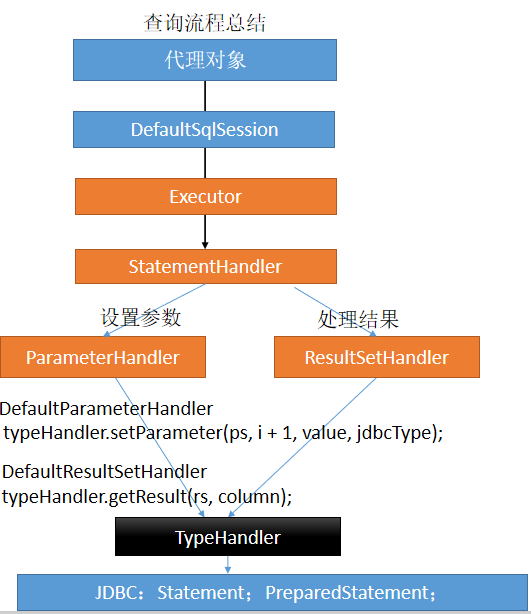
四大对象:
Executor:执行sql
StatementHandler:处理sql语句预编译,设置参数等相关工作;
ParameterHandler:设置预编译参数用的
ResultHandler:处理结果集
处理类型的对象:
TypeHandler:在整个过程中,进行数据库类型和javaBean类型的映射
4.11、myabatis执行流程总结
1、根据配置文件(全局,sql映射)初始化Configuration对象
2、创建一个默认的DefaultSqlSession对象
里面包含了Configuration以及Executor(根据全局配置文件中的defaultExecutorType创建出对应的Executor)
3、DefaultSqlSession.getMapper():拿到Mapper接口对应的MapperProxy;
4、MapperProxy里面有(DefaultSqlSession);
5、执行增删改查方法:
1)调用DefaultSqlSession执行的增删改查的Executor对象
2)会创建一个StatementHandler对象
(同时也会创建出ParameterHandler和ResultSetHandler)
3)调用StatementHandler预编译参数以及设置参数值;
使用ParameterHandler来给sql设置参数
4)调用StatementHandler的增删改查方法;
5)ResultSetHandler封装结果
注意:
四大对象每个创建的时候都有一个interceptorChain.pluginAll(parameterHandler);
4.12、mybatis与hibernate不同
Mybatis和hibernate不同,它不完全是一个ORM框架,因为MyBatis需要程序员自己编写Sql语句,不过mybatis可以通过XML或注解方式灵活配置要运行的sql语句,
并将java对象和sql语句映射生成最终执行的sql,最后将sql执行的结果再映射生成java对象。 Mybatis学习门槛低,简单易学,程序员直接编写原生态sql,可严格控制sql执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发,例如互联网软件、企业运营类软件等,
因为这类软件需求变化频繁,一但需求变化要求成果输出迅速。但是灵活的前提是mybatis无法做到数据库无关性,如果需要实现支持多种数据库的软件则需要自定义多套sql映射文件,工作量大。 Hibernate对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件(例如需求固定的定制化软件)如果用hibernate开发可以节省很多代码,提高效率。
但是Hibernate的学习门槛高,要精通门槛更高,而且怎么设计O/R映射,在性能和对象模型之间如何权衡,以及怎样用好Hibernate需要具有很强的经验和能力才行。 总之,按照用户的需求在有限的资源环境下只要能做出维护性、扩展性良好的软件架构都是好架构,所以框架只有适合才是最好。
第五Dao开发方法
使用Mybatis开发Dao,通常有两个方法,即原始Dao开发方法和Mapper接口开发方法。
5.1需求
将下边的功能实现Dao:
根据用户id查询一个用户信息
根据用户名称模糊查询用户信息列表
添加用户信息
5.2SqlSession的使用范围
SqlSession中封装了对数据库的操作,如:查询、插入、更新、删除等。
通过SqlSessionFactory创建SqlSession,而SqlSessionFactory是通过SqlSessionFactoryBuilder进行创建。
1.SqlSessionFactoryBuilder
SqlSessionFactoryBuilder用于创建SqlSessionFacoty,SqlSessionFacoty一旦创建完成就不需要SqlSessionFactoryBuilder了,
因为SqlSession是通过SqlSessionFactory生产,所以可以将SqlSessionFactoryBuilder当成一个工具类使用,最佳使用范围是方法范围即方法体内局部变量。
2.SqlSessionFactory
SqlSessionFactory是一个接口,接口中定义了openSession的不同重载方法,SqlSessionFactory的最佳使用范围是整个应用运行期间,
一旦创建后可以重复使用,通常以单例模式管理SqlSessionFactory。
3.SqlSession
SqlSession是一个面向用户的接口, sqlSession中定义了数据库操作方法。
每个线程都应该有它自己的SqlSession实例。SqlSession的实例不能共享使用,它也是线程不安全的。因此最佳的范围是请求或方法范围。
绝对不能将SqlSession实例的引用放在一个类的静态字段或实例字段中。
打开一个 SqlSession;使用完毕就要关闭它。通常把这个关闭操作放到 finally 块中以确保每次都能执行关闭。如下:
SqlSession session = sqlSessionFactory.openSession();
try {
// do work
} finally {
session.close();
}
5.3原始的Dao开始
原始Dao开发方法需要程序员编写Dao接口和Dao实现类。
1.映射文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="test">
<!-- 根据id获取用户信息 -->
<select id="findUserById" parameterType="int" resultType="cn.itcast.mybatis.po.User">
select * from user where id = #{id}
</select>
<!-- 添加用户 -->
<insert id="insertUser" parameterType="cn.itcast.mybatis.po.User">
<selectKey keyProperty="id" order="AFTER" resultType="java.lang.Integer">
select LAST_INSERT_ID()
</selectKey>
insert into user(username,birthday,sex,address)
values(#{username},#{birthday},#{sex},#{address})
</insert>
</mapper>
2.Dao接口
Public interface UserDao {
public User getUserById(int id) throws Exception;
public void insertUser(User user) throws Exception;
}
Public class UserDaoImpl implements UserDao {
//注入SqlSessionFactory
public UserDaoImpl(SqlSessionFactory sqlSessionFactory){
this.setSqlSessionFactory(sqlSessionFactory);
}
private SqlSessionFactory sqlSessionFactory;
@Override
public User getUserById(int id) throws Exception {
SqlSession session = sqlSessionFactory.openSession();
User user = null;
try {
//通过sqlsession调用selectOne方法获取一条结果集
//参数1:指定定义的statement的id,参数2:指定向statement中传递的参数
user = session.selectOne("test.findUserById", 1);
System.out.println(user);
} finally{
session.close();
}
return user;
}
@Override
Public void insertUser(User user) throws Exception {
SqlSession sqlSession = sqlSessionFactory.openSession();
try {
sqlSession.insert("insertUser", user);
sqlSession.commit();
} finally{
session.close();
}
}
}
3.Dao测试
创建一个JUnit的测试类,对UserDao进行测试
private SqlSessionFactory sqlSessionFactory;
@Before
public void init() throws Exception {
SqlSessionFactoryBuilder sessionFactoryBuilder = new SqlSessionFactoryBuilder();
InputStream inputStream = Resources.getResourceAsStream("SqlMapConfig.xml");
sqlSessionFactory = sessionFactoryBuilder.build(inputStream);
}
@Test
public void testGetUserById() {
UserDao userDao = new UserDaoImpl(sqlSessionFactory);
User user = userDao.getUserById(22);
System.out.println(user);
}
}
4.问题
原始Dao开发中存在以下问题:
Dao方法体存在重复代码:通过SqlSessionFactory创建SqlSession,调用SqlSession的数据库操作方法
调用sqlSession的数据库操作方法需要指定statement的id,这里存在硬编码,不得于开发维护。
5.4Mapper动态原理
1.开发范围
Mapper接口开发方法只需要程序员编写Mapper接口(相当于Dao接口),由Mybatis框架根据接口定义创建接口的动态代理对象,代理对象的方法体同上边Dao接口实现类方法。
Mapper接口开发需要遵循以下规范:
1、 Mapper.xml文件中的namespace与mapper接口的类路径相同。
2、 Mapper接口方法名和Mapper.xml中定义的每个statement的id相同
3、 Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同
4、 Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同
2.Mapper.xml接口
定义mapper映射文件UserMapper.xml(内容同Users.xml),需要修改namespace的值为 UserMapper接口路径。将UserMapper.xml放在classpath 下mapper目录 下。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.itcast.mybatis.mapper.UserMapper">
<!-- 根据id获取用户信息 -->
<select id="findUserById" parameterType="int" resultType="cn.itcast.mybatis.po.User">
select * from user where id = #{id}
</select>
<!-- 自定义条件查询用户列表 -->
<select id="findUserByUsername" parameterType="java.lang.String"
resultType="cn.itcast.mybatis.po.User">
select * from user where username like '%${value}%'
</select>
<!-- 添加用户 -->
<insert id="insertUser" parameterType="cn.itcast.mybatis.po.User">
<selectKey keyProperty="id" order="AFTER" resultType="java.lang.Integer">
select LAST_INSERT_ID()
</selectKey>
insert into user(username,birthday,sex,address)
values(#{username},#{birthday},#{sex},#{address})
</insert>
</mapper>
3.Mapper.java(接口文件)
/**
* 用户管理mapper
*/
Public interface UserMapper {
//根据用户id查询用户信息
public User findUserById(int id) throws Exception;
//查询用户列表
public List<User> findUserByUsername(String username) throws Exception;
//添加用户信息
public void insertUser(User user)throws Exception;
}
接口定义有如下特点:
1、 Mapper接口方法名和Mapper.xml中定义的statement的id相同
2、 Mapper接口方法的输入参数类型和mapper.xml中定义的statement的parameterType的类型相同
3、 Mapper接口方法的输出参数类型和mapper.xml中定义的statement的resultType的类型相同
4.加载UserMapper.xml文件
修改SqlMapConfig.xml文件:
<!-- 加载映射文件 -->
<mappers>
<mapper resource="mapper/UserMapper.xml"/>
</mappers>
5.测试
Public class UserMapperTest extends TestCase {
private SqlSessionFactory sqlSessionFactory;
protected void setUp() throws Exception {
//mybatis配置文件
String resource = "sqlMapConfig.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
//使用SqlSessionFactoryBuilder创建sessionFactory
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
}
Public void testFindUserById() throws Exception {
//获取session
SqlSession session = sqlSessionFactory.openSession();
//获取mapper接口的代理对象
UserMapper userMapper = session.getMapper(UserMapper.class);
//调用代理对象方法
User user = userMapper.findUserById(1);
System.out.println(user);
//关闭session
session.close();
}
@Test
public void testFindUserByUsername() throws Exception {
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
List<User> list = userMapper.findUserByUsername("张");
System.out.println(list.size());
}
Public void testInsertUser() throws Exception {
//获取session
SqlSession session = sqlSessionFactory.openSession();
//获取mapper接口的代理对象
UserMapper userMapper = session.getMapper(UserMapper.class);
//要添加的数据
User user = new User();
user.setUsername("张三");
user.setBirthday(new Date());
user.setSex("1");
user.setAddress("北京市");
//通过mapper接口添加用户
userMapper.insertUser(user);
//提交
session.commit();
//关闭session
session.close();
}
}
6.小结
selectOne和selectList
动态代理对象调用sqlSession.selectOne()和sqlSession.selectList()是根据mapper接口方法的返回值决定,如果返回list则调用selectList方法,如果返回单个对象则调用selectOne方法。
namespace
mybatis官方推荐使用mapper代理方法开发mapper接口,程序员不用编写mapper接口实现类,使用mapper代理方法时,输入参数可以使用pojo包装对象或map对象,保证dao的通用性。
5.5SqlMapConfig.xml配置文件
1.配置内容
SqlMapConfig.xml中配置的内容和顺序如下:
properties(属性)
settings(全局配置参数)
typeAliases(类型别名)
typeHandlers(类型处理器)
objectFactory(对象工厂)
plugins(插件)
environments(环境集合属性对象)
environment(环境子属性对象)
transactionManager(事务管理)
dataSource(数据源)
mappers(映射器)
2. properties(属性)
SqlMapConfig.xml可以引用java属性文件中的配置信息如下:
在classpath下定义db.properties文件
jdbc.driver=com.mysql.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/mybatis?characterEncoding=utf-8
jdbc.username=root
jdbc.password=root
SqlMapConfig.xml引用如下:
<properties resource="db.properties"/>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</dataSource>
</environment>
</environments>
3. typeAliases(类型别名)
mybatis支持别名
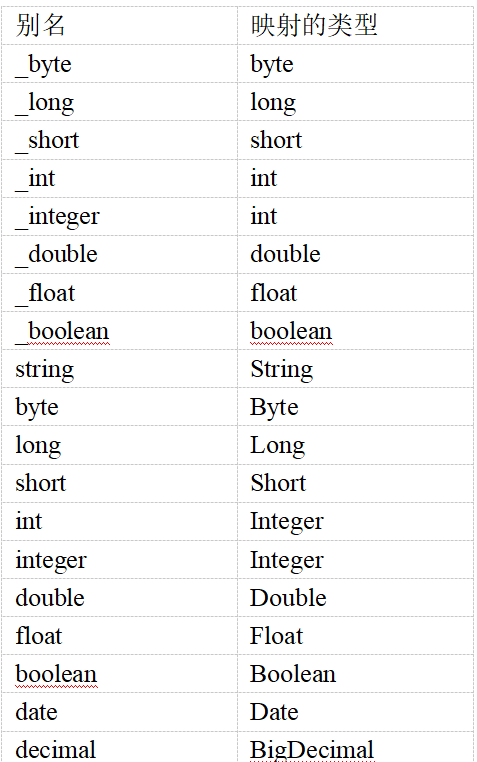
自定义别名:
在SqlMapConfig.xml中配置:
<typeAliases>
<!-- 单个别名定义 -->
<typeAlias alias="user" type="cn.itcast.mybatis.po.User"/>
<!-- 批量别名定义,扫描整个包下的类,别名为类名(首字母大写或小写都可以) -->
<package name="cn.itcast.mybatis.po"/>
<package name="其它包"/>
</typeAliases>
4.mappers(映射器)
Mapper配置的几种方法:
<mapper resource=" " />
使用相对于类路径的资源
如:<mapper resource="sqlmap/User.xml" />
<mapper class=" " />
使用mapper接口类路径
如:<mapper class="cn.itcast.mybatis.mapper.UserMapper"/>
注意:此种方法要求mapper接口名称和mapper映射文件名称相同,且放在同一个目录中。
<package name=""/>
注册指定包下的所有mapper接口
如:<package name="cn.itcast.mybatis.mapper"/>
注意:此种方法要求mapper接口名称和mapper映射文件名称相同,且放在同一个目录中。
第六输入输出类型
Mapper.xml映射文件中定义了操作数据库的sql,每个sql是一个statement,映射文件是mybatis的核心。
6.1 parameterType(输入类型)
1.传入简单类型
参考上面的代码
2.传递pojo对象
Mybatis使用ognl表达式解析对象字段的值,#{}或者${}括号中的值为pojo属性名称。
传递pojo包装对象
开发中通过pojo传递查询条件 ,查询条件是综合的查询条件,不仅包括用户查询条件还包括其它的查询条件(比如将用户购买商品信息也作为查询条件),这时可以使用包装对象传递输入参数。
Pojo类中包含pojo。
需求:根据用户名查询用户信息,查询条件放到QueryVo的user属性中。
QueryVo
public class QueryVo {
private User user;
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
}
Sql语句
SELECT * FROM user where username like '%刘%'
Mapper文件
<!-- 使用包装类型查询用户
使用ognl从对象中取属性值,如果是包装对象可以使用.操作符来取内容部的属性
-->
<select id="findUserByQueryVo" parameterType="queryvo" resultType="user">
SELECT * FROM user where username like '%${user.username}%'
</select>

测试方法
@Test
public void testFindUserByQueryVo() throws Exception {
SqlSession sqlSession = sessionFactory.openSession();
//获得mapper的代理对象
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
//创建QueryVo对象
QueryVo queryVo = new QueryVo();
//创建user对象
User user = new User();
user.setUsername("刘");
queryVo.setUser(user);
//根据queryvo查询用户
List<User> list = userMapper.findUserByQueryVo(queryVo);
System.out.println(list);
sqlSession.close();
}
6.2 resultType(输出类型)
1.输出简单类型
参考getnow输出日期类型,看下边的例子输出整型:
Mapper.xml文件
<!-- 获取用户列表总数 -->
<select id="findUserCount" parameterType="user" resultType="int">
select count(1) from user
</select>
Mapper接口:
public int findUserCount(User user) throws Exception;
调用
Public void testFindUserCount() throws Exception{
//获取session
SqlSession session = sqlSessionFactory.openSession();
//获取mapper接口实例
UserMapper userMapper = session.getMapper(UserMapper.class);
User user = new User();
user.setUsername("管理员");
//传递Hashmap对象查询用户列表
int count = userMapper.findUserCount(user);
//关闭session
session.close();
}
输出简单类型必须查询出来的结果集有一条记录,最终将第一个字段的值转换为输出类型。
使用session的selectOne可查询单条记录。
2.输出pojo
参考上面的代码
6.3resultMap
resultType可以指定pojo将查询结果映射为pojo,但需要pojo的属性名和sql查询的列名一致方可映射成功。
如果sql查询字段名和pojo的属性名不一致,可以通过resultMap将字段名和属性名作一个对应关系 ,resultMap实质上还需要将查询结果映射到pojo对象中。
resultMap可以实现将查询结果映射为复杂类型的pojo,比如在查询结果映射对象中包括pojo和list实现一对一查询和一对多查询。
1.Mapper.xml定义
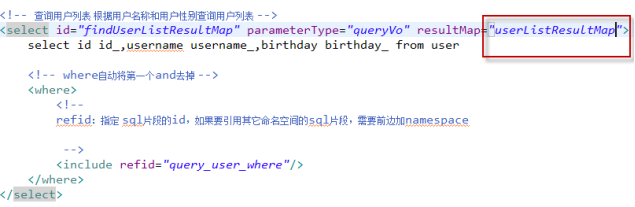
2.定义resultMap
由于上边的mapper.xml中sql查询列和Users.java类属性不一致,需要定义resultMap:userListResultMap将sql查询列和Users.java类属性对应起来

<id />:此属性表示查询结果集的唯一标识,非常重要。如果是多个字段为复合唯一约束则定义多个<id />。
Property:表示User类的属性。
Column:表示sql查询出来的字段名。
Column和property放在一块儿表示将sql查询出来的字段映射到指定的pojo类属性上。
<result />:普通结果,即pojo的属性。
3.Mapper定义的接口
public List<User> findUserListResultMap() throws Exception;
第七·.动态sql
7.1IF
<!-- 传递pojo综合查询用户信息 -->
<select id="findUserList" parameterType="user" resultType="user">
select * from user
where 1=1
<if test="id!=null">
and id=#{id}
</if>
<if test="username!=null and username!=''">
and username like '%${username}%'
</if>
</select>
注意要做不等于空字符串校验。
7.2WHERE
<select id="findUserList" parameterType="user" resultType="user">
select * from user
<where>
<if test="id!=null and id!=''">
and id=#{id}
</if>
<if test="username!=null and username!=''">
and username like '%${username}%'
</if>
</where>
</select>
<where />可以自动处理第一个and。
7.3foreach
向sql传递数组或List,mybatis使用foreach解析,如下:
需求
传入多个id查询用户信息,用下边两个sql实现:
SELECT * FROM USERS WHERE username LIKE '%张%' AND (id =10 OR id =89 OR id=16)
SELECT * FROM USERS WHERE username LIKE '%张%' id IN (10,89,16)
在pojo中定义list属性ids存储多个用户id,并添加getter/setter方法
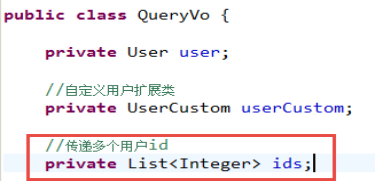
mapper.xml
<if test="ids!=null and ids.size>0">
<foreach collection="ids" open=" and id in(" close=")" item="id" separator="," >
#{id}
</foreach>
</if>
测试代码
List<Integer> ids = new ArrayList<Integer>();
ids.add(1);//查询id为1的用户
ids.add(10); //查询id为10的用户
queryVo.setIds(ids);
List<User> list = userMapper.findUserList(queryVo);
7.4sql片段
Sql中可将重复的sql提取出来,使用时用include引用即可,最终达到sql重用的目的,如下:
<!-- 传递pojo综合查询用户信息 -->
<select id="findUserList" parameterType="user" resultType="user">
select * from user
<where>
<if test="id!=null and id!=''">
and id=#{id}
</if>
<if test="username!=null and username!=''">
and username like '%${username}%'
</if>
</where>
</select>
将where条件抽取出来:
<sql id="query_user_where">
<if test="id!=null and id!=''">
and id=#{id}
</if>
<if test="username!=null and username!=''">
and username like '%${username}%'
</if>
</sql>
使用include引用:
<select id="findUserList" parameterType="user" resultType="user">
select * from user
<where>
<include refid="query_user_where"/>
</where>
</select>
注意:如果引用其它mapper.xml的sql片段,则在引用时需要加上namespace,如下:
<include refid="namespace.sql片段”/>
第八.关联查询
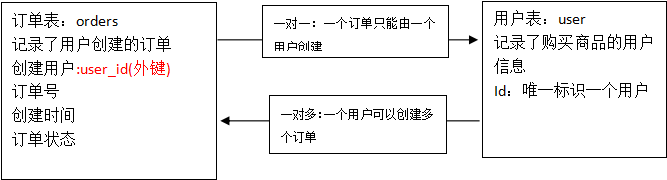
8.1商品订单数据模型
8.2一对一查询
案例:查询所有订单信息,关联查询下单用户信息。
注意:因为一个订单信息只会是一个人下的订单,所以从查询订单信息出发关联查询用户信息为一对一查询。如果从用户信息出发查询用户下的订单信息则为一对多查询,因为一个用户可以下多个订单。
1.方法一
使用resultType,定义订单信息po类,此po类中包括了订单信息和用户信息:
Sql语句
SELECT
orders.*,
user.username,
userss.address
FROM
orders,
user
WHERE orders.user_id = user.id
定义pojo类
Po类中应该包括上边sql查询出来的所有字段,如下:
public class OrdersCustom extends Orders {
private String username;// 用户名称
private String address;// 用户地址
OrdersCustom类继承Orders类后OrdersCustom类包括了Orders类的所有字段,只需要定义用户的信息字段即可。
Mapper.xml
<!-- 查询所有订单信息 -->
<select id="findOrdersList" resultType="cn.itcast.mybatis.po.OrdersCustom">
SELECT
orders.*,
user.username,
user.address
FROM
orders, user
WHERE orders.user_id = user.id
Mapper接口
public List<OrdersCustom> findOrdersList() throws Exception;
测试:
Public void testfindOrdersList()throws Exception{
//获取session
SqlSession session = sqlSessionFactory.openSession();
//获限mapper接口实例
UserMapper userMapper = session.getMapper(UserMapper.class);
//查询订单信息
List<OrdersCustom> list = userMapper.findOrdersList();
System.out.println(list);
//关闭session
session.close();
}
2.方法二
使用resultMap,定义专门的resultMap用于映射一对一查询结果
SQL语句
SELECT
orders.*,
user.username,
user.address
FROM
orders,
user
WHERE orders.user_id = user.id
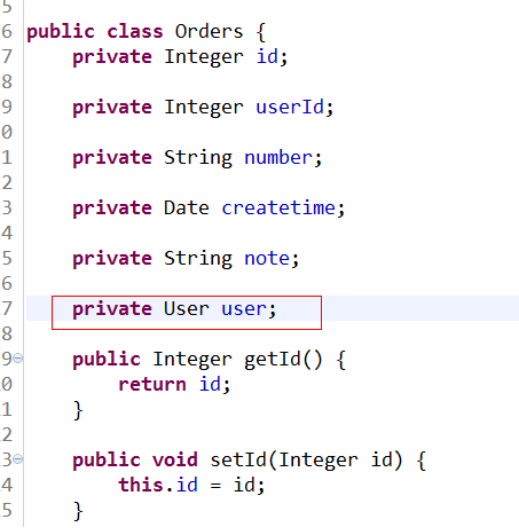
定义PO类
在Orders类中加入User属性,user属性中用于存储关联查询的用户信息,因为订单关联查询用户是一对一关系,所以这里使用单个User对象存储关联查询的用户信息。
Mapper.xml
<!-- 查询订单关联用户信息使用resultmap -->
<resultMap type="Orders" id="orderUserResultMap">
<id column="id" property="id"/>
<result column="user_id" property="userId"/>
<result column="number" property="number"/>
<result column="createtime" property="createtime"/>
<result column="note" property="note"/>
<!-- 一对一关联映射 -->
<!--
property:Orders对象的user属性
javaType:user属性对应 的类型
-->
<association property="user" javaType="cn.itcast.po.User">
<!-- column:user表的主键对应的列 property:user对象中id属性-->
<id column="user_id" property="id"/>
<result column="username" property="username"/>
<result column="address" property="address"/>
</association>
</resultMap>
<select id="findOrdersWithUserResultMap" resultMap="orderUserResultMap">
SELECT
o.id,
o.user_id,
o.number,
o.createtime,
o.note,
u.username,
u.address
FROM
orders o
JOIN `user` u ON u.id = o.user_id
</select>
这里resultMap指定orderUserResultMap。
association:表示进行关联查询单条记录
property:表示关联查询的结果存储在cn.itcast.mybatis.po.Orders的user属性中
javaType:表示关联查询的结果类型
<id property="id" column="user_id"/>:查询结果的user_id列对应关联对象的id属性,这里是<id />表示user_id是关联查询对象的唯一标识。
<result property="username" column="username"/>:查询结果的username列对应关联对象的username属性。
Mapper接口
public List<Orders> findOrdersListResultMap() throws Exception;
测试
Public void testfindOrdersListResultMap()throws Exception{
//获取session
SqlSession session = sqlSessionFactory.openSession();
//获限mapper接口实例
UserMapper userMapper = session.getMapper(UserMapper.class);
//查询订单信息
List<Orders> list = userMapper.findOrdersList2();
System.out.println(list);
//关闭session
session.close();
}
小结
使用association完成关联查询,将关联查询信息映射到pojo对象中。
8.3一对多查询
案例:查询所有用户信息及用户关联的订单信息。
用户信息和订单信息为一对多关系。
使用resultMap实现如下:
SQL语句
SELECT
u.*, o.id oid,
o.number,
o.createtime,
o.note
FROM
`user` u
LEFT JOIN orders o ON u.id = o.user_id
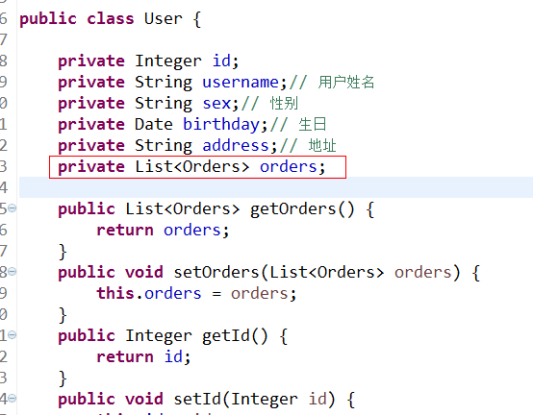
定义PO类
在User类中加入List<Orders> orders属性
Mapper.xml
<resultMap type="user" id="userOrderResultMap">
<!-- 用户信息映射 -->
<id property="id" column="id"/>
<result property="username" column="username"/>
<result property="birthday" column="birthday"/>
<result property="sex" column="sex"/>
<result property="address" column="address"/>
<!-- 一对多关联映射 -->
<collection property="orders" ofType="orders">
<id property="id" column="oid"/>
<!--用户id已经在user对象中存在,此处可以不设置-->
<!-- <result property="userId" column="id"/> -->
<result property="number" column="number"/>
<result property="createtime" column="createtime"/>
<result property="note" column="note"/>
</collection>
</resultMap>
<select id="getUserOrderList" resultMap="userOrderResultMap">
SELECT
u.*, o.id oid,
o.number,
o.createtime,
o.note
FROM
`user` u
LEFT JOIN orders o ON u.id = o.user_id
</select>
collection部分定义了用户关联的订单信息。表示关联查询结果集
property="orders":关联查询的结果集存储在User对象的上哪个属性。
ofType="orders":指定关联查询的结果集中的对象类型即List中的对象类型。此处可以使用别名,也可以使用全限定名。
<id />及<result/>的意义同一对一查询。
Mapper接口
List<User> getUserOrderList();
测试
@Test
public void getUserOrderList() {
SqlSession session = sqlSessionFactory.openSession();
UserMapper userMapper = session.getMapper(UserMapper.class);
List<User> result = userMapper.getUserOrderList();
for (User user : result) {
System.out.println(user);
}
session.close();
}
第九、缓存
MyBatis 也有一级缓存和二级缓存,并且预留了集成第三方缓存的接口。
9.1缓存介绍
“装饰者模式(Decorator Pattern)是指在不改变原有对象的基础之上,将功能附加到对象上,提供了比继承更有弹 性的替代方案(扩展原有对象的功能)。”
9.2一级缓存
9.2.1一级缓存介绍
一级缓存也叫本地缓存,MyBatis 的一级缓存是在会话(SqlSession)层面进行缓存的。MyBatis 的一级缓存是默认开启的,不需要任何的配置。
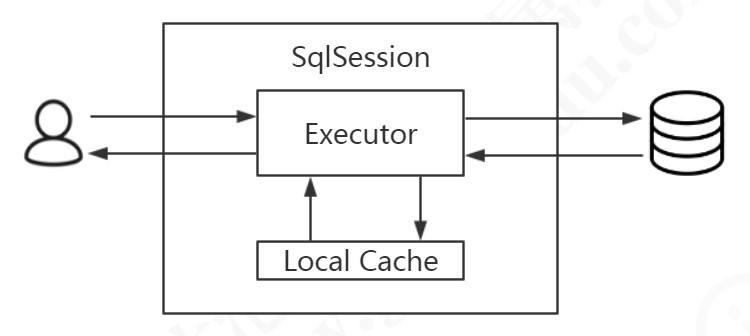
9.2.2一级缓存的验证
判断是否命中缓存:如果再次发送 SQL 到数据库执行,说明没有命中缓存;如果直接打印对象,说明是从内存缓存中取到了结果。
1、同一个Session共享
BlogMapper mapper = session.getMapper(BlogMapper.class); System.out.println(mapper.selectBlog(1)); System.out.println(mapper.selectBlog(1));
2、不同的Session共享
SqlSession session1 = sqlSessionFactory.openSession();
BlogMapper mapper1 = session1.getMapper(BlogMapper.class);
System.out.println(mapper.selectBlog(1));
一级缓存在 BaseExecutor 的 query()——queryFromDatabase()中存入。在queryFromDatabase()之前会 get()。
3、同一个会话中,update(包括 delete)会导致一级缓存被清空
mapper.updateByPrimaryKey(blog); session.commit(); System.out.println(mapper.selectBlogById(1));
一级缓存是在 BaseExecutor 中的 update()方法中调用 clearLocalCache()清空的(无条件),query 中会判断。
4、如果跨域,其他会话更新了数据,导致读取到脏数据(一级缓存不能跨会话共享)
// 会话 2 更新了数据,会话 2 的一级缓存更新
BlogMapper mapper2 = session2.getMapper(BlogMapper.class);
mapper2.updateByPrimaryKey(blog); session2.commit(); // 会话 1 读取到脏数据,因为一级缓存不能跨会话共享 System.out.println(mapper1.selectBlog(1));
9.2.3一级缓存的不足
思考:一级缓存怎么命中?CacheKey 怎么构成?
详细请参考:https://blog.csdn.net/u012621115/article/details/50998619
9.3二级缓存
9.3.1开启二级缓存的方法
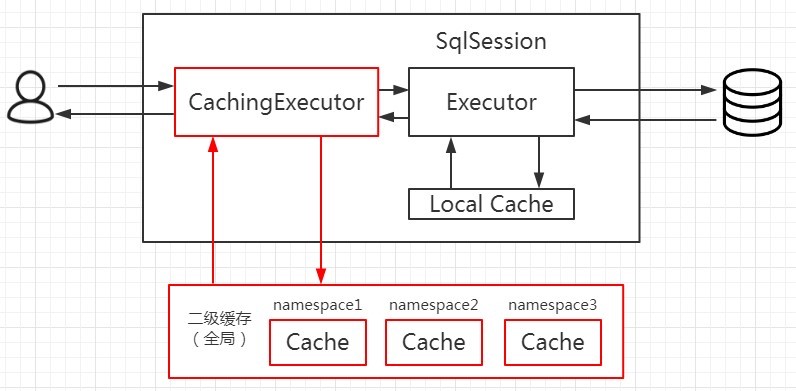
9.3.2开启二级缓存
<setting name="cacheEnabled" value="true"/>
只要没有显式地设置 cacheEnabled=false,都会用 CachingExecutor 装饰基本的执行器。
<!-- 声明这个 namespace 使用二级缓存 -->
<cache type="org.apache.ibatis.cache.impl.PerpetualCache" size="1024"
<!—最多缓存对象个数,默认 1024--> eviction="LRU" <!—回收策略-->
flushInterval="120000" <!—自动刷新时间 ms,未配置时只有调用时刷新-->
readOnly="false"/> <!—默认是 false(安全),改为 true 可读写时,对象必须支持序列 化 -->
Mapper.xml 配置了<cache>之后,select()会被缓存。update()、delete()、insert()会刷新缓存。
<select id="selectBlog" resultMap="BaseResultMap" useCache="false">
<select id="selectBlog" resultMap="BaseResultMap" useCache="false">
9.3.3二级缓存验证
(验证二级缓存需要先开启二级缓存)
BlogMapper mapper1 = session1.getMapper(BlogMapper.class);
System.out.println(mapper1.selectBlogById(1)); // 事务不提交的情况下,二级缓存不会写入
// session1.commit(); BlogMapper mapper2 = session2.getMapper(BlogMapper.class);
System.out.println(mapper2.selectBlogById(1));
思考:为什么事务不提交,二级缓存不生效?
Blog blog = new Blog();
blog.setBid(1); blog.setName("357");
mapper3.updateByPrimaryKey(blog);
session3.commit(); // 执行了更新操作,二级缓存失效,再次发送 SQL 查询 System.out.println(mapper2.selectBlogById(1));
思考:为什么增删改操作会清空缓存?
一级缓存默认是打开的,二级缓存需要配置才可以开启。那么我们必须思考一个问题,在什么情况下才有必要去开启二级缓存?
<cache-ref namespace="com.gupaoedu.crud.dao.DepartmentMapper" />
9.3.3第三方缓存做二级缓存
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-redis</artifactId>
<version>1.0.0-beta2</version>
</dependency>
<cache type="org.mybatis.caches.redis.RedisCache" eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
redis.properties 配置:
host=localhost
port=6379
connectionTimeout=5000
soTimeout=5000
database=0
代码:
package com.yehui.cache;
import com.yehui.utils.SerializeUtil;
import org.apache.ibatis.cache.Cache;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* mybatis二级缓存整合Redis
*/
public class MybatisRedisCache implements Cache {
private static Logger logger = LoggerFactory.getLogger(MybatisRedisCache.class);
private Jedis redisClient = createReids();
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private String id;
public MybatisRedisCache(final String id) {
if (id == null) {
throw new IllegalArgumentException("Cache instances require an ID");
}
logger.debug(">>>>>>>>>>>>>>>>>>>>>>>>MybatisRedisCache:id=" + id);
this.id = id;
}
@Override
public String getId() {
return this.id;
}
@Override
public int getSize() {
return Integer.valueOf(redisClient.dbSize().toString());
}
@Override
public void putObject(Object key, Object value) {
logger.debug(">>>>>>>>>>>>>>>>>>>>>>>>putObject:" + key + "=" + value);
redisClient.set(SerializeUtil.serialize(key.toString()), SerializeUtil.serialize(value));
}
@Override
public Object getObject(Object key) {
Object value = SerializeUtil.unserialize(redisClient.get(SerializeUtil.serialize(key.toString())));
logger.debug(">>>>>>>>>>>>>>>>>>>>>>>>getObject:" + key + "=" + value);
return value;
}
@Override
public Object removeObject(Object key) {
return redisClient.expire(SerializeUtil.serialize(key.toString()), 0);
}
@Override
public void clear() {
redisClient.flushDB();
}
@Override
public ReadWriteLock getReadWriteLock() {
return readWriteLock;
}
protected static Jedis createReids() {
JedisPool pool = new JedisPool("127.0.0.1", 6379);
return pool.getResource();
}
}
package com.yehui.utils;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class SerializeUtil {
public static byte[] serialize(Object object) {
ObjectOutputStream oos = null;
ByteArrayOutputStream baos = null;
try {
// 序列化
baos = new ByteArrayOutputStream();
oos = new ObjectOutputStream(baos);
oos.writeObject(object);
byte[] bytes = baos.toByteArray();
return bytes;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public static Object unserialize(byte[] bytes) {
ByteArrayInputStream bais = null;
try {
// 反序列化
bais = new ByteArrayInputStream(bytes);
ObjectInputStream ois = new ObjectInputStream(bais);
return ois.readObject();
} catch (Exception e) {
}
return null;
}
}