----------------------------------------hbase的 安装----------------------------------------
本地安装:
1 解压文件夹。
2 修改 conf/hbase-site.xml ,配置 数据文件夹
<property>
<name>hbase.rootdir</name>
<value>file:///DIRECTORY/hbase</value>
</property>
3 然后就可以启动了:./bin/start-hbase.sh
4 进入客户端:./bin/hbase shell
分布式安装:
1 修改 数据文件目录( habse-site.xml)
hbase.rootdir
2 开启分布式( habse-site.xml)
hbase.cluster.distributed
3 配置regionserver (regionservers)
4 停用 自带的 zk ( hbase-en.sh)
HBASE_MANAGES_ZK=false
5 配置 zk 集群地址,和 配置 只看数据文件地址( habse-site.xml)
hbase.zookeeper.quorum
hbase.zookeeper.property.dataDir
6 复制 hdfs-site.xml 到hbase的 配置文件目录。
7 启动 hbase
./bin/start-hbase.sh
备注:默认 只会在启动 hbase 的机器上启动一个 hmaster 。但是我们可以在别的 任意节点再次启动其他 hmaster。
8 启动别的 hmaster
./hbase-daemon.sh start master
----------------------------------------hbase的常见语法----------------------------------------
1 创建表 :
create 'test', 'cf'
2 插入一行: (一次只能插入一列,如果有多列 反复用这个rowkey 插入)
put 'test', 'row1', 'cf:a', 'value1'
3 查询:
scan 'test'
4 查询一行
get 'test', 'row1'
5 禁用一张表
disable 'test'
6 删除一张表:(只有禁用了的才能删除)
drop 'test'
7 停止 hbase:
./bin/stop-hbase.sh
8 查看表结构:
desc 'test'
----------------------------------------hbase的理论知识点----------------------------------------
1 hbase 是一个nosql 数据库。
2 hbase 是一个 列存数类型nosql据库
3 hbase 数据存放的 没一行必须有 rowkey 。并且查询几乎都需要使用到 rowkey,所以 rowkey 生成规则非常重要。
4 hbase 需要预定义列族( column fmaliy ),在定义表的时候5 hbase 官方建议 列族不超过3 个,因为为超过三个带来的性能消耗问题目前还没有太好的解决方
6 hbase 的 真正列叫做 colunm。 可以在 put 数据的时候任意指定。
7 hbase 决定一个数据cell的因数 , rowkey( 行号) ,cf(列族) ,column(列)和 timestamp( 时间)。
8 cell 中的数据是 以 key value 的形式存储的。key 的组成:key = {rowkey + column + version}, cell 里面的 value 是 数据的字数组。和 基于内存的 key-value nosql 数据库不同的是 这个 value 主要是放在 硬盘。
9 cell 是 hbase存储数据的基本单元。
10 每次向 hbase 使用的 hdfs 存储数据,不利于修改,hbase的修改 是一时间毫秒数最为 version 另外存了一份,如果 最大当前 rowkey 对应的 column 对应的数据版本超过表允许的版本,那么会自动删除当前数据块最旧一个的版本。
11 HLog ( WAL log ) 类似数据库 的 tranlog , 具体里面有什么 有空查询一下。
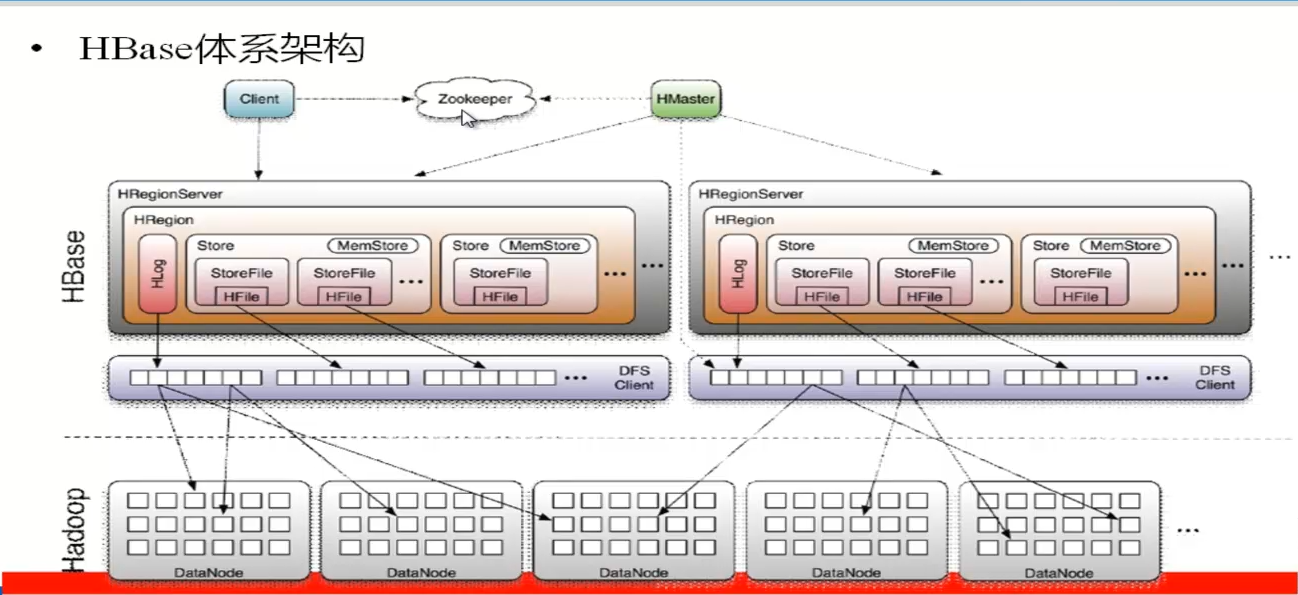
12 hbase 体系架构图
13 hbase 的 主节点叫做 HMaster,从节点叫做 HRegionserver。
14 一个 HRegionServer 有 多个 Hregion, 但是 只有一个Hlog 。
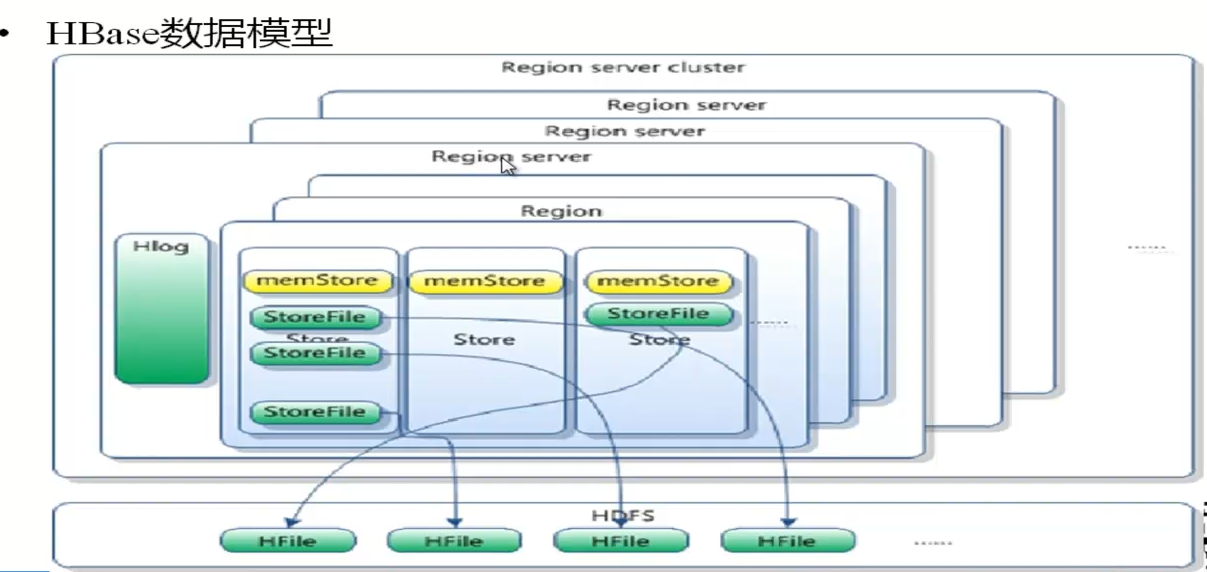
15 HRegion 把表中的数据进行横向切分(按照rowkey ,rowkey 连续的一部分放在一起的,有序的)。
16 HRegion 下面有多个 Store ,每一个 Store 代表一个 列族。如果这个表只有一个 cf 那么 就只有一个 store。(并且每一个 cf 的数据都存在同一个目录下)
17 store 分 2 种 ,一种叫做 memStore ,一种叫做 storeFile。
18 memStore 是数据刚 写入的时候在内存中。这时候就是在 memstore 里面。
19 当 memstore 触发溢写的时候 ,产生 storeFile ,每次溢写都产生一个新的 storeFile。
20 当系统的 storeFile 多到一定数量,就会触发合并压缩,产生更大的 单个 storeFile。
21 合并压缩分2 中,一种 辅助压缩( minor compaction),一种是主要压缩( major compaction )
22 只有 major compaction 才能版本合并和删除老版本数据。
23 当某个 region 的所有的 storeFile 大于 一定值的时候会吧自己分成2 个region,这个过程叫做裂变,并且 hmaster 会把其中一个region 分到合适的regionserver 上。
24 master 做的事情
1 为 region server 分配region。
2 负责 region server 的负载均衡(吧 region 分给 region 少的region server)
3 如果有 region server下线。那么在别的region server 上找到 这个 region server 上的 region ,并且重新复制这些region,并且分配各合适的 region server。
4 管理用户的 table的 增删改操作。
region server 做的事情
1 维护自己管理的region,处理这些region的io 请求
2 负责切片 运行过程中变得 过大的 region,这个过程叫做 region的 裂变。
25 HRegion 是hbase 中分布式存储和负载均衡的最小单元。 一个表的多个 region 可以在不同region server 上。
26 storeFile 是 以 Hfile 的格式存在hdfs 上的。
27 如果没有溢写 过,那么这时候 store 没有storeFile, 在 hdfs 上 就没有 数据。
28 hbase 数据模型