一, hadoop 的 安装:
修改 namenode 地址
修改 datanode 地址
修改JAVA_HOME
二 hdfs
hdfs 分布式文件 系统。 namenode 存放在数据的元文件(文件名相关的信息)。datanode 存放着数据真实的内内容。 hadoop 启动 以后 。namenode 先启动,然后 datanode 启动,并且 datanode 上报自己管理的文件数据块 给 namenode。datanode 上报的是数据编号。 namanode 里面存的 文件名和文件 由那些编号的数据库块 组成。当 nama node 控制着 datanode的 数据库 副本关系。
datanode 数据块 block 默认大小是 64M (2.0 默认 128M),,也就是说一个数据最小占用 64M 硬盘。每次有数据修改的时候那么node先追加操作 到edits 文件,然后等到一定时间以后 由 secondary namenode 吧edits 的变化 持久化到 fsimge 文件。这时候 name node 的新修改。是写到一个新的edits 文件。( name node 吧 edits 传输给 secondary namenode ,然后 由 secondary namenode 合并 edits 修改到 fsimage ,然后把这个新的 fs image 回传给 namenode )
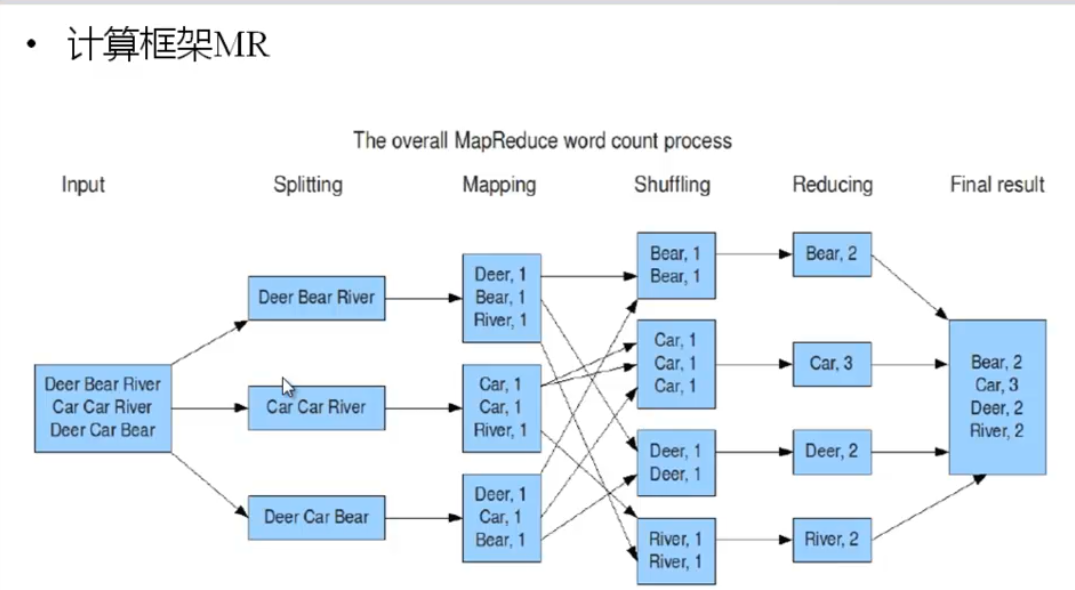
三 mapReduce
map 是分
reduce 是合
mapReduce 是一种离线的大数据计算方案。
spark 是一种基于内存的大数据计算方案。
storm 是一种 流式 的 大数据计算方案。
四 namenode 的 高可用
2.0 以后 hadoop 加入了 namenode 的 高可用。namenode(active) 分为 主 和 从(standby) ,主的 对外提供服务,如果过主挂了,那么 剩下的 从 节点中会通过 zookeeper 的 投票选举出一个新的主。
zookeeper 通过心跳机制(ZKFC) 检测着 每一个 namaname 的状态。 namenode 不在把 源数据 存在 本地磁盘,而是存在 journal node 上面, 多个journal node 是一个集群。并且是高可用的。主 从 name node 共享着这些 journal node。journal node 代替了 secend marster node。
五 namenode 的单机 解决方案 , federation
多个 namenode 同时 对外提供服务。每个节点 保存着一部分的 元数据。 并且他们共享着 相同的 datanode 。客户端选着一个文件的 元数据 是放到哪个 namenode 上面去。
六 资源调度 yarn
yarn 分成2 部分
ResourceManger:负责 这个集群的资源调度和管理 只有一个
AplicationMater(nodeManger);负责任务相关的事务 有多个
yarn 使得多个计算框架可以在同一个集群上运行
在 MRv2 上面 mr 运行在 yarn 上。废除了 jobtracker 和 tasktracker
七 hadoop 2.0 高可用集群 配置步骤
1 配置 javaHOME hadoop-env.sh
2 指定 集群名称 cpre-site.xml
3 配置 集群有哪些 namenode cpre-site.xml
4 配置 namenode 的 rpc 和http 访问地址和 端口
5 配置 journal node edits 目录和地址
6 配置 客户端 ha 提供类
7 配置 ssh fencing
8 配置 journal 工作目录 hdfs-site.xml
9 配置 开启自动切换 hdfs-site.xml
10 配置zk 集群 cpre-site.xml
11 配置 data node 数据 目录
12 配置 slaver
启动顺序
1 journal node
2 格式化 namenode 数据目录
3 启动那个 格式化了的 namenode
4 在没有 没有格式化的 namenode 机子上 拉取 格式化的namenode 的 数据文件。(检查是否有数据文件生成)
5 停止所有服务
6 初始化 zkfc
7 在启动一个节点注册zkfc
8 启动所有服务。
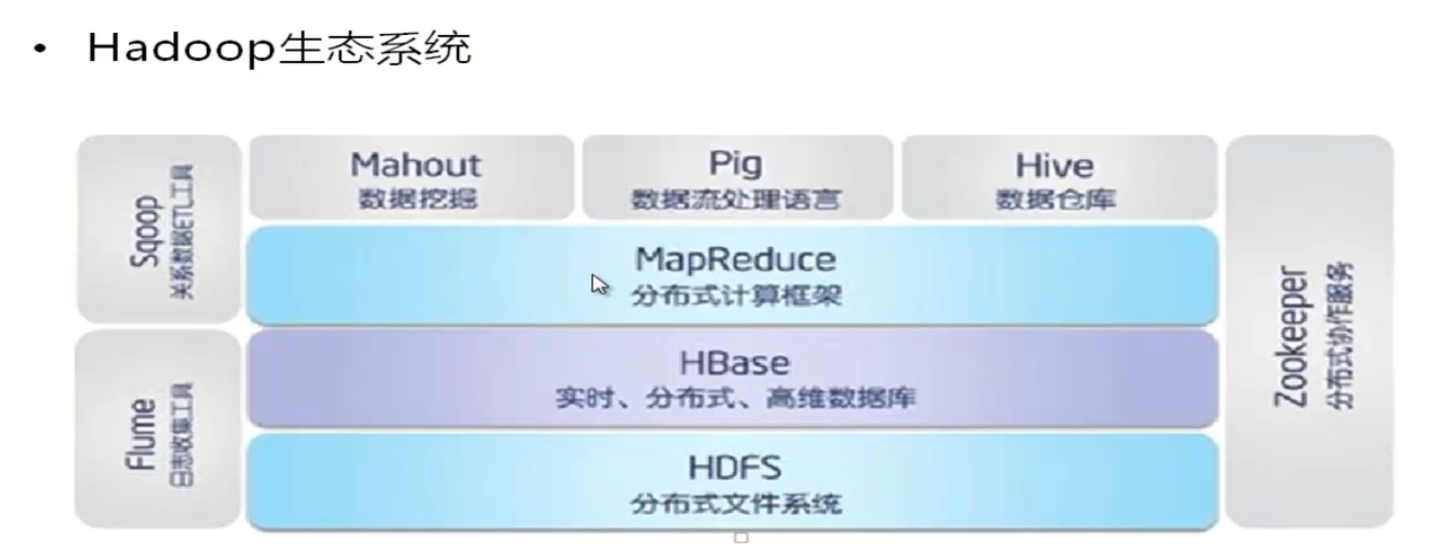
hadoop 包含的东西: