20145326 《Java程序设计》第8周学习总结
教材学习内容总结
第十四章
一、认识NIO
1.NIO叙述
对于高级输入/输出处理,Java从JDK1.4开始提供了NIO(New IO),而Java SE7中又提供了NIO2,认识与善用这些高级输入/输出处理API,对于输入/输出的处理效率会有很大的帮助。InputStream、OutputStream的输入/输出,基本上是以字节为单位进行低层次处理,虽然你得直接面对字节数组,但实际上多半是对字节数组中整个区块进行处理。虽然java.io套件中也有一些装饰类,不过,若只要对字节或字符串中感兴趣的区块进行处理,这些类就不见得合适,必须自行撰写API或寻找相关的链接库来处理索引、标记等细节。相对于串流输入/输出使用InputStream、OutputStream来衔接数据源与目的地,NIO使用频道来衔接数据节点,在处理数据时,NIO可以让你设定缓冲区容量,在缓冲区中对感兴趣的数据区块进行标记,对于这些区块标记,提供了clear(),rewind(),flip(),compact()等高级操作。
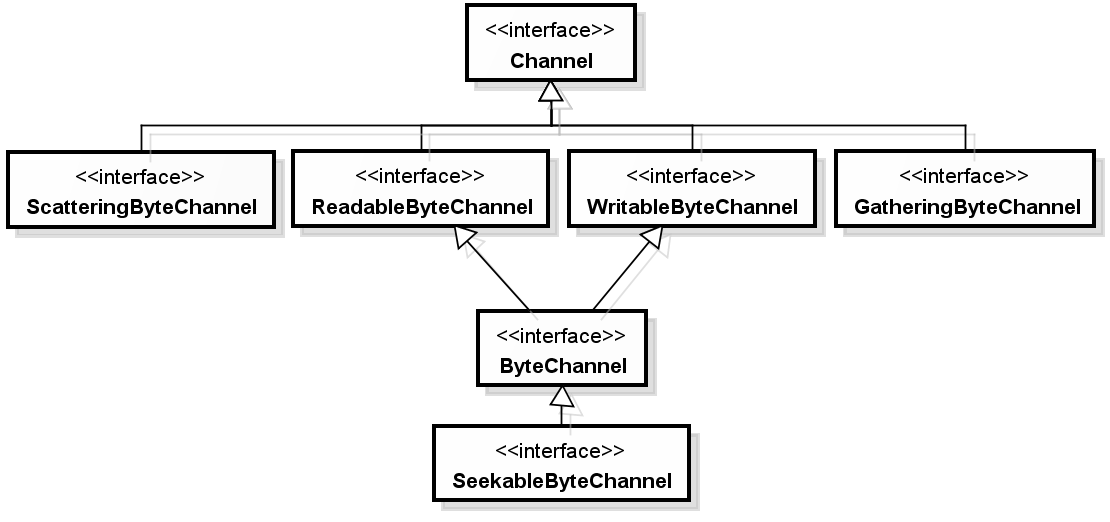
2.Channel架构与操作
NIO中Channel相关接口与类,是位于java.nio.channels套件之中,Channel接口是AutoClosable的子接口,因此都可以使用JDK7之后的尝试关闭资源语法,Channel接口上新增了isOpen()方法,用来确认Channel是否开启。ByteChannel没有定义任何方法,单纯继承了ReadableByteChannel与WritableByteChannel的行为,ByteChannel的子接口SeekableByteChannel可以读取与改变下一个要存取数据的位置。
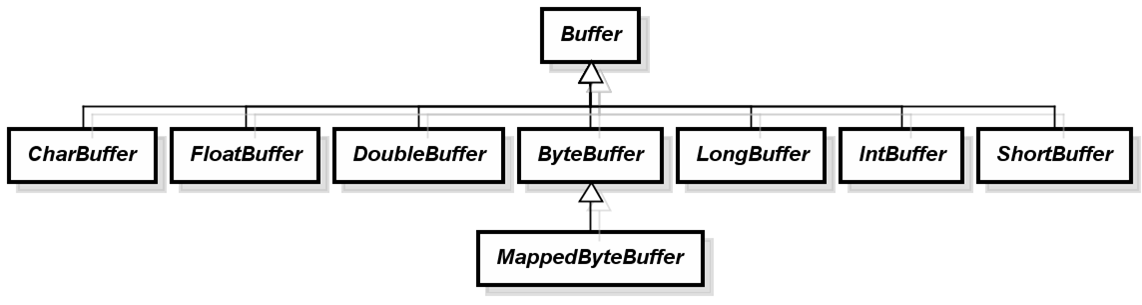
3.Buffer架构与操作
在NIO设计中,数据都是在java.nio.Buffer中处理,Buffer是个抽象类,定义了clear(),rewind(),flip(),compact()等对数据区块的高级操作,这类操作返回类型都是Buffer,实际上返回this。Buffer的容量大小可以用capacity()方法取得,Buffer的数据界限索引值可以用limit()方法取得,Buffer的下一个可读取数据的位置索引值可以由position()方法取得。当一个缓冲区刚被配置或调用clear()方法后,limit()等于capacity(),position()会是0.
调用rewind()方法的话,会将position设为0,而limit不变,这个方法通常用在想要重复读取Buffer中某段数据时使用,作用相当于单独调用Buffer的position(0)方法。
二、NIO2文件系统
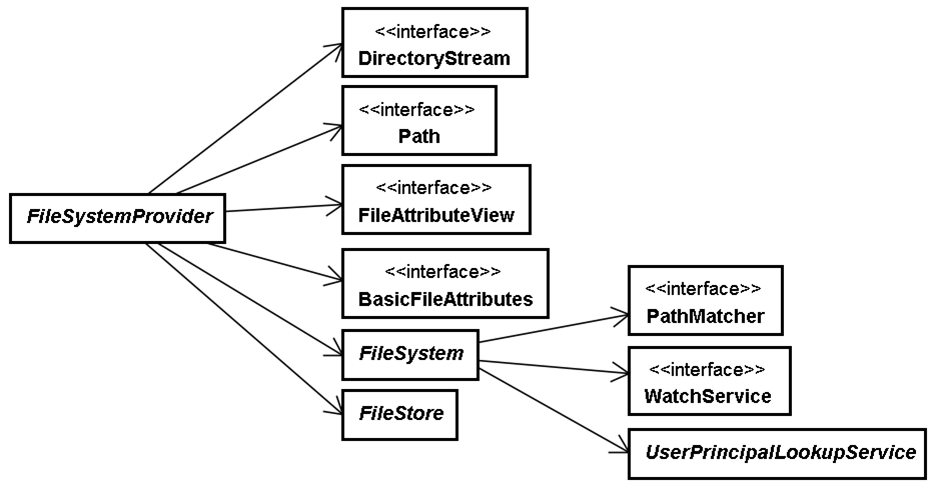
1.NIO2架构
NIO2文件系统API提供一组标准接口与类,应用程序开发者只要基于这些标准接口与类进行文件系统操作就好。应用程序开发者主要使用java.nio.file与java.nio.file.attribute,包中必须操作的抽象类或接口,由文件系统提供者操作。NIO2文件系统的中心是java.nio.file.spi.FileSystemProvider,本身为抽象类。是文件系统提供者操作的类。作用是产生java.nio.file与java.nio.file.attribute中各种抽象类或接口的操作对象。
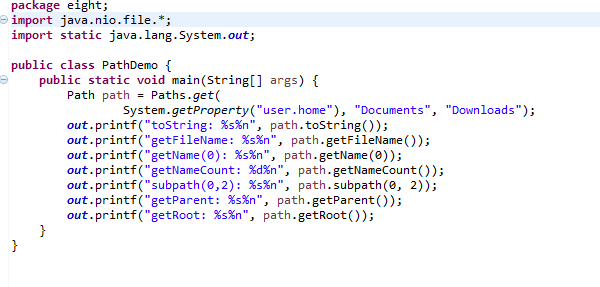
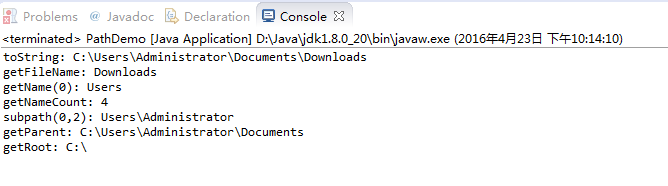
2.操作路径
想要取得Path实例,可以使用Paths.get()方法,最基本的使用方式,就是使用字符串路径,可以使用相对路径与绝对路径。Path实例仅代表路径信息,该路径实际对应的文档或文件夹不一定存在。
运行结果:
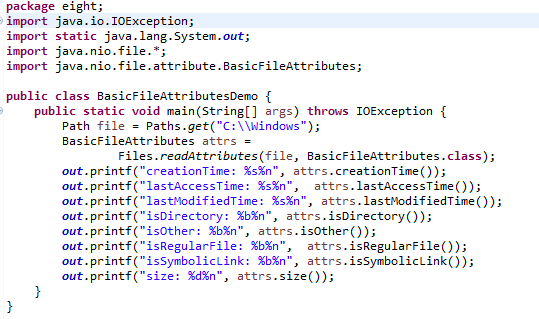
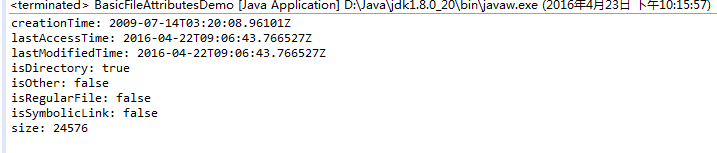
3.属性读取与设定
在过去并无标准方式取得不同文件系统支持的不同属性,在JDK7中,可以针对不同文件系统取得支持的属性信息。
运行结果:
运行结果:
4.操作文档与目录
如果想要删除Path代表的文档或目录,可以使用Files.delete()方法,如果不存在,会抛出NoSuchFileException,如果因目录不为空而无法删除文档,会抛出DirectoryNotEmptyException。使用Files.deleteIfExists()方法也可以删除文档,这个方法在文档不存在时调用,并不会抛出异常。Files.copy()还有两个重载版本,一个是接受InputStream作为来源,可直接读取数据,并将结果复制至指定的Path中;另一个Files.copy()版本是将来源Path复制至指定的OutputStream。若要进行文档或目录移动,可以使用Files.move()方法,使用方式与Files.copy()方法类似,可指定来源Path、目的地Path与CopyOption。
5.读取、访问目录
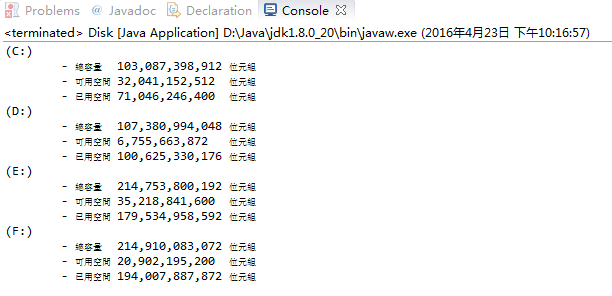
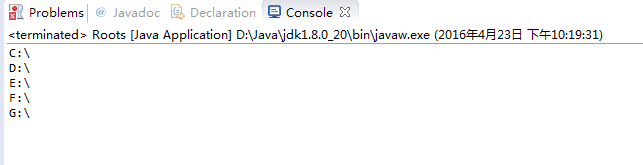
如果想要取得文件系统根目录路径信息,可以使用FileSystem的getRootDirectory()方法。
运行结果:
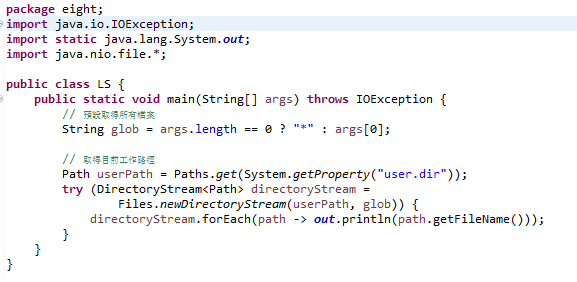
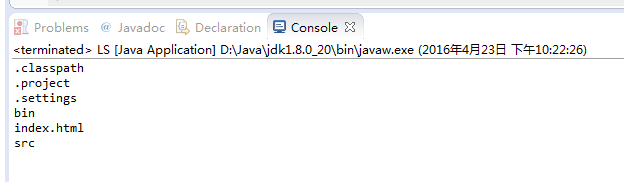
6.过滤、搜索文档
如果想在列出目录内容时过滤想显示的文档,例如只想显示.class与.jar文档,可以在使用Files.newDirectoryStream()时,将第二个参数指定过滤条件为*.{class,jar}。Files.newDirectoryStream()的另一版本接受DirectoryStream.Filter接口操作对象,如果Glob语法无法满足条件过滤需求,可以自行操作DirectoryStream.Filter的accept()方法自定义过滤条件。
运行结果:
第十五章
一、日志
1.日志API简介
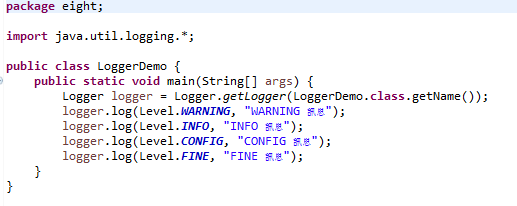
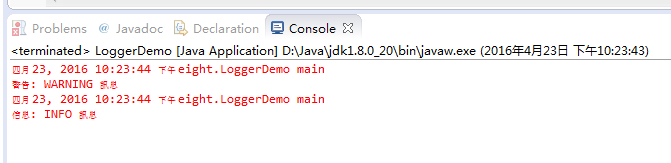
java.util.logging包提供了日志功能相关类与接口。不必额外配置日志组件,就可在标准Java平台使用是其好处,使用日志的起点是Logger类,Logger类的构造函数标示为protected,不是java.util.logging同包的类不能直接以new创建,要取得Logger实例,必须使用Logger的静态方法getLogger()。调用getLogger()时,必须指定Logger实例所属名称空间。名称空间以“.”作为层级区分。名称空间层级相同的Logger,其父Logger组态相同。通常在哪个类中取得的Logger,名称空间就会命名为哪个类全名。简单来说,Logger是记录信息的起点,要输出的信息,必须先通过Logger的Level与Filter过滤,再通过Handler的Level与Filter过滤,格式化信息的动作交给Formatter,输出信息的动作实际上是Handler负责。
运行结果:
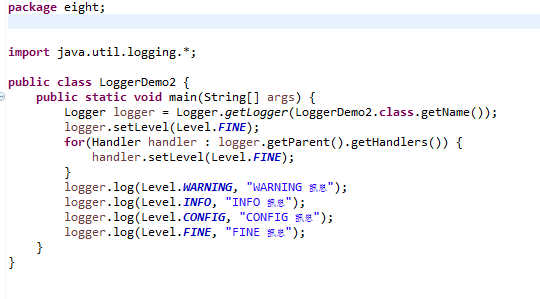
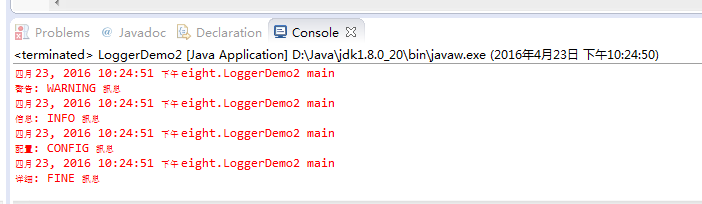
2.指定日志层级
Logger与Handler默认都会先依据Level过滤信息,如果没有做任何修改,取得的Logger实例之父Logger组态,就是Logger.GLOBALLOGGERNAME名称空间Logger实例的组态,这个实例的组态设定为INFO,可以通过Logger实例的getParent()取得父Logger实例,可通过getLevel()取得设定的Level实例。Logger的信息处理会往父Logger传播,也就是说,在没有做任何组态设定的情况下,默认取得的Logger实例,层级必须大于或等于Logger.GLOBALLOGGERNAME名称空间Logger实例设定的Level.INFO,才有可能输出信息。
运行结果:
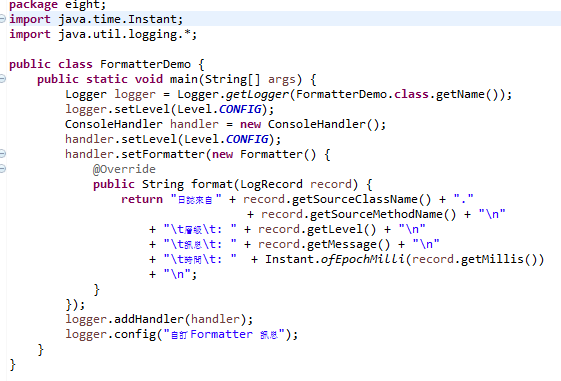
3.使用Handler与Formatter
MemoryHandler不会格式化日志信息,信息会暂存于内存缓冲区,直到超过缓冲区大小,才将信息输出至指定的目标Handler。StreamHandler可自行指定信息输出时使用的OutputStream实例,它与子类都会使用指定的Formatter格式化信息,ConsoleHandler创建时,会自动指定OutputStream为System.err,所以日志信息会显示在控制台上。FileHandler创建时会建立日志输出时使用的FileOutputStream,文档位置与名称可以使用模式(Pattern)字符串指定。
4.自定义Handler、Formatter、Filter
如果java.util.logging包中提供的Handler成果都不符合需求,可以继承Handler类,操作抽象方法publish(),flush(),close()来自定义Handler,建议操作时考虑信息过滤与格式化。
运行结果:
5.使用logging.properties
之前讲的都是使用程序撰写方式,改变Logger对象的组态,实际上,可以通过logging.properties来设定Logger组态,这很方便。
二、国际化基础
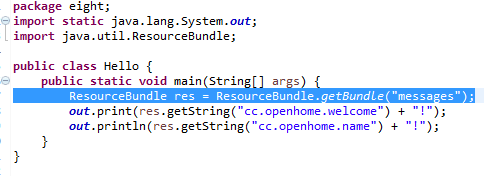
1.使用ResourceBundle
ResourceBundle的静态getBundle()方法会取得一个ResourceBundle的实例,所给定的自变量名称是信息文档的主文件名,getBundle()会自动找到对应的.properties文档。
2.使用Locale
国际化的三个重要概念:地区信息、资源包与基础名称。
三、规则表示式
1.规则表示式简介
规则表示式主要用于字符、字符串格式比较,后来在信息领域广为应用。规则表示式基本上包括两种字符:字面意义字符和元字符。
运行结果:
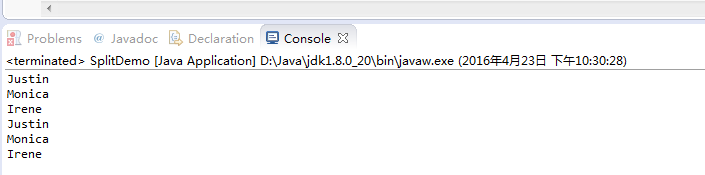
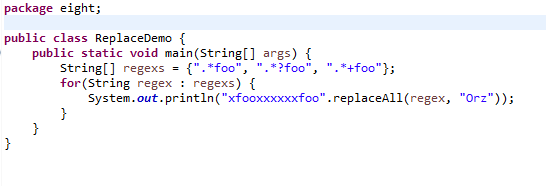
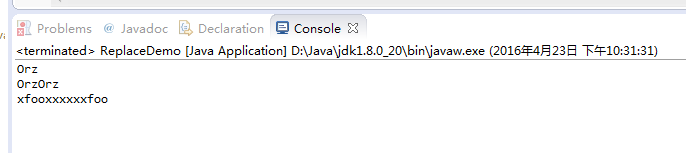
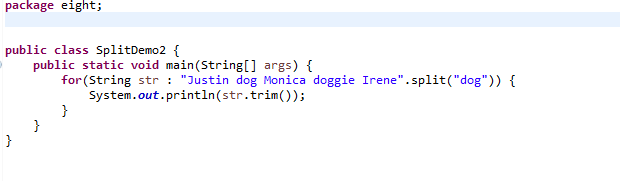
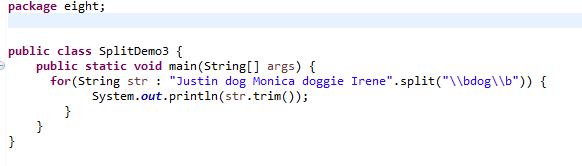
下面这个范例使用String的replaceAll()来示范3个量词的差别。
运行结果:
以下是边界比较的范例:
运行结果:
运行结果:
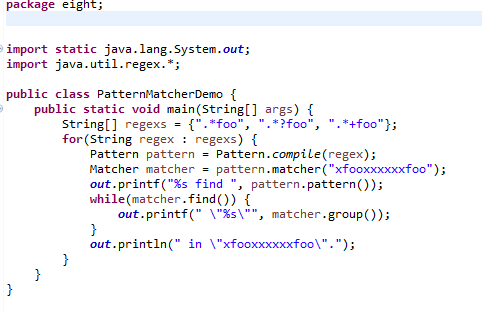
2.Pattern与Matcher
java.util.regex.Pattern实例是规则表示式在JVM中的代表对象,Pattern的构造函数被标示为private,所以你无法用new创建Pattern实例,而必须通过Pattern的静态方法compile()来取得。
运行结果:
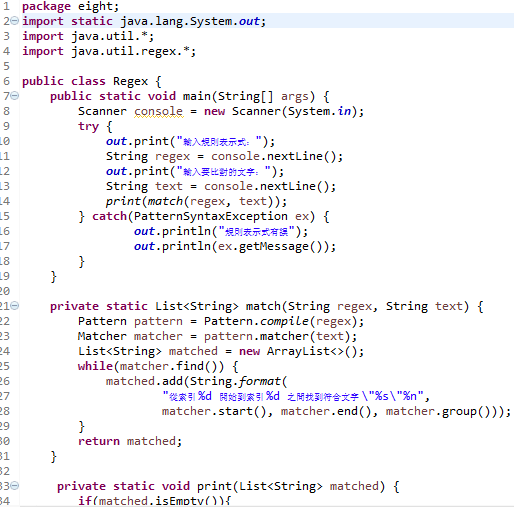
下面这个范例可以让你输入规则表示式与想比较的字符串:
运行结果:
四、JDK8 API增强功能
1.StringJoiner、Arrays新增API
如果你有一组字符串,想要指定每个字符串间以逗号分隔进行连结,String新增了join()静态方法可以直接使用,不仅List,这个版本的join()实际上可以接受Iterable操作对象。在Arrays上新增了parallePrefix()、paralleSetAll()与paralleSort()方法。
2.Stream相关API
如果想对数组进行管道化操作,方法之一是使用Arrays的asList()方法返回List,而后调用stream()方法取得Stream实例。另一个方式是使用Arrays的stream()方法,它可以指定数组后返回Stream实例。


教材学习中的问题和解决过程
娄老师说本周任务是重点学习15章,14章如果没有时间可以不看。大部分同学第一反应就是“肯定没时间”。其实感觉还好,我就按着自己的节奏走,没想到一下子就顺利的将14章与15章内容都学了(不过重点还是放在15章的)。之前娄老师说过,java的核心内容是封装、继承、多态那部分知识,确实比较抽象难懂。之后的内容都是介绍各种API的应用,都是活生生的例子,比较具体,如果觉得难那是因为对这部分知识感到陌生,不熟悉。自己首先理清头绪,不懂的基础知识多看几遍书,然后再多敲几遍代码,仔细思考总结,将代码与知识点结合,感觉立马就上来了!要讲究科学的学习方法~不要盲目!!!
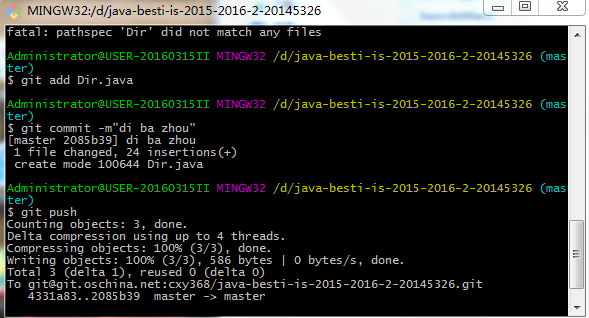
git托管:
托管截图:
代码统计行数:

其他(感悟、思考等,可选)
虽说我这周又是自学两章,知识点比较多,但还好,没什么难点,就像娄老师之前说的,java的核心知识与难点之前都已经学完了,后面的章节全都是介绍一些类的应用。看第一遍教材的时候肯定觉得陌生,难以接受。这是个过程,很正常。在不断的学习中,我也在不断的寻找适合自己的好的学习方法。看第一遍教材先有个大概的了解,头脑里勾画出一个轮廓。然后看第二遍才是逐渐理解与体会,往轮廓里填内容,这时不能只看书,还要结合书上的代码,自己还要主动敲代码,主动发现问题。 第三遍是梳理知识点也是回忆,将大脑与知识相融合。这样下来对知识绝对会有进一步的掌握!自身也会有质的飞跃!要学会抓住重点,把力量用在刀刃上,寻找乐趣,保持激情,提高学习效率!现在的我是带着目的去看教材的,不是像以前那样盲目的。我后来发现这点尤其重要!我知道第14章和第15章跟之前一样,还是介绍一些类的应用,于是我采取和之前一样的办法,一边看书,一边总结,看书上总共介绍了多少种API,每一种API的架构是什么,每一种API的作用与注意事项是什么。就这样有系统的去学习,感觉效率十分高!而且头脑思绪清晰。其实这些知识不是难,我们只是感到陌生而已。同学们有了畏难情绪和厌学情绪,当然就学不进去了,还谈什么效率!这两章的知识不像之前的对象、封装、继承、多态那些概念那么抽象难懂,都是活生生的具体的例子,接受起来其实也挺快的。娄老师说的很对,重要的不是要你学多少java知识,而是通过不断的学习过程,来总结出一套适合自己的良好的学习方法,这将受用一生。当然不同的人肯定情况不一样,适合自己的才是最好的。我这周最大的收获就是学会了用git托管代码,用wc统计代码行数,并且真正体会到学习也要讲科学,不要盲目。时间用得多,不一定就学得好。找到属于自己的学习方法,提高效率!这比一切都重要!调整一下自己的心态吧,任何事情不要有畏难情绪,万事开头难,只要是对的,就坚持!最终一定会受益匪浅!!我找周正一同学从头到尾给我演示了一遍git的使用后,才发现git并没有我们之前想象的那么难。其实很简单,逻辑也很清晰,自己练习几遍就上手了。以后对于新生事物不要一来就排斥,不要嫌麻烦,要接受它,然后通过不断的练习,最终掌握并活用它!
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
| 目标 | 3500行 | 20篇 | 300小时 | |
| 第一周 | 120/120 | 1/1 | 14/14 | |
| 第二周 | 340/460 | 1/2 | 14/28 | |
| 第三周 | 200/660 | 1/3 | 14/42 | |
| 第四周 | 320/980 | 1/4 | 14/56 | |
| 第五周 | 280/1260 | 1/5 | 14/70 | |
| 第六周 | 478/1738 | 2/7 | 16/86 | |
| 第七周 | 425/2163 | 2/9 | 16/102 | |
| 第八周 | 859/3022 | 2/11 | 16/118 | 学会了使用git托管代码,学会了用wc统计代码行数 |