一丶大数据分析和人工智能已经成为整个社会发展最主要的基础推动力,两者的基础都是机器学习。
大数据分析火热的深刻原因:
数据源:非结构化数据(语音,视频,文本,网络数据) 一般都是表格数据。
模型和计算能力:深度学习(模型显示),GPU(加快深度学习的训练),分布式系统(提高训练的能力,水平)。
广泛的应用场景:营销,广告,金融,交通,医疗等。
二丶Data -------> Y=F(X)
Data:数据
X:表示,特征,指标
F:模型
Y:智慧,也即预测任务或目标
三丶大数据:数据采集,数据清洗,数据分析和数据应用的整个流程中的理论,技术和方法
机器学习:大数据分析的核心内容。机器学习解决的是找到将X和Y关联的模型F,从Data到X的步骤通常是人工完成的(特征工程)
四丶机器学习方法的分类
有监督的学习:
数据集中的样本带有标签,有明确的目标(数学题,有标准答案)
回归和分类
目标:找到样本到标签的最佳映射(找到确切的f)( Y=F(X))
应用场景:垃圾邮件分类,病理切片,客户流失预警,客户风险评估,房价预测等。
典型方法:
回归模型:线性回归,岭回归,LASSO和回归样条等。
分类模型:逻辑回归,K近邻,决策树,支持向量机等。
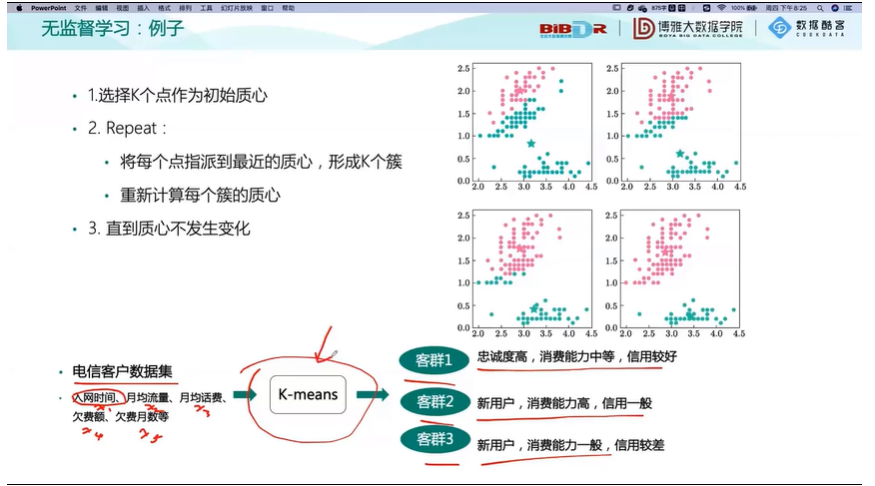
无监督的学习:
数据集中的样本没有标签,没有明确的目标( Y=F(X), Y 未知)
聚类,降维,排序,密度估计,关联规则挖掘
聚类:将数据集中相似的样本进行分组,使得:
同一组对象之间尽可能相似;
不同组对象之间尽可能不相似。
医用场景:
基因表达水平聚类:根据不同基因表达的时序特征进行聚类,得到基因表达处于信号通路上游还是下游的信息。
篮球运动员划分:根据球员相关数据,将其划分不同等级的运动员阵营当中。
客户分析:把客户细分成不同客户群,每个客户群都有相似行为,做到准确营销
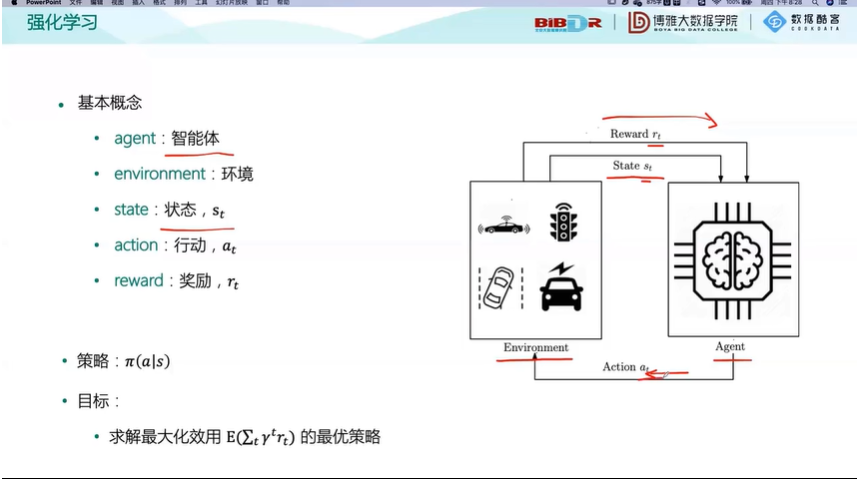
强化学习:
智慧决策的过程,通过过程模拟和观察来不断学习,提高决策能力
例如:AlphaGo(类似于人 自我学习 )
数据集:一组样本
样本:数据集的一行。一个样本包含一个或者多个特征,此外还可能有一个标签。
特征:在进行预测是使用的输入变量。
样本示例: 标签为y 特征为x
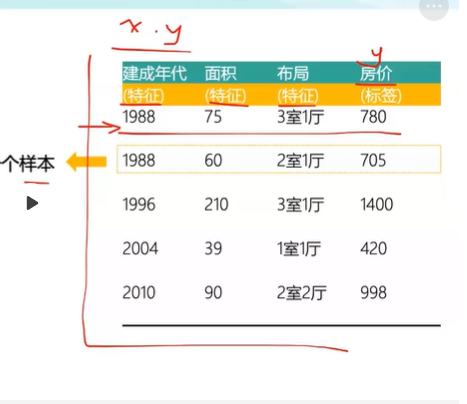
训练集:用于训练模型的数据集
测试集:用于测试模型的数据集合
模型:建立数据的输入x和输出y之间的映射关系 y=f(x)
损失函数: l(yi,f(xi))

过度拟合:
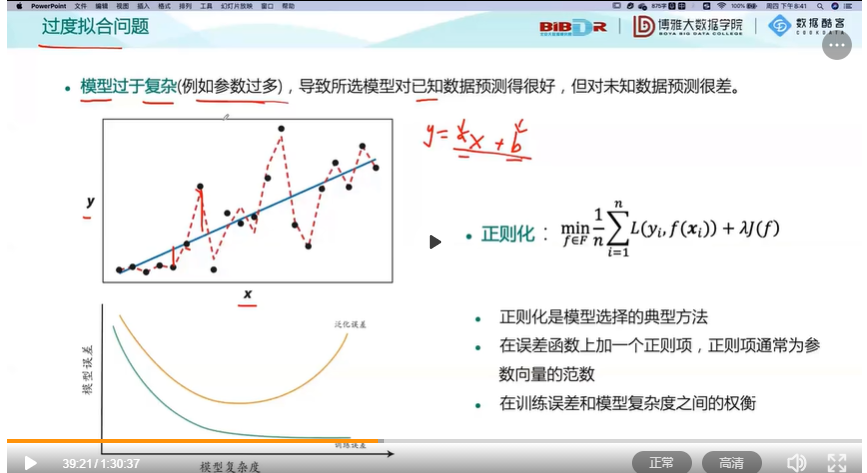
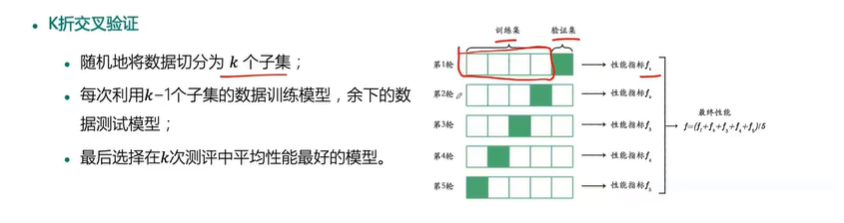
交叉验证:重复的使用数据。将数据集随机切分,将切分的数据集组合为训练集和测试集,在此基础上反复进行训练,测试和模型选择。
K折交叉验证:(数据集不是特别大 )