RDD
WordCount处理流程
- sc.textFile("/root/temp/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

调用任务过程
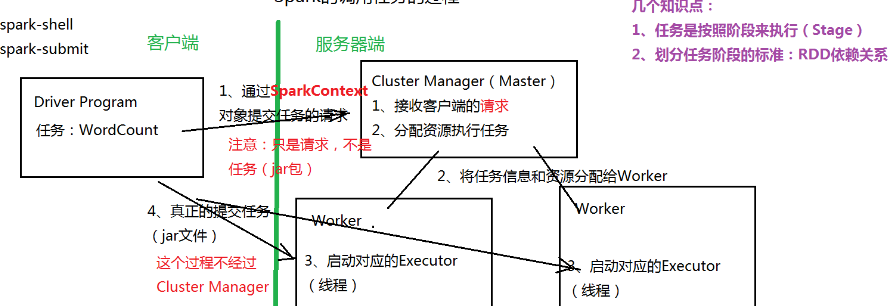
- 客户端将任务通过SparkContext对象提交给Manager
- Manager将任务分配给Worker
- 客户端将任务提交给Worker
特性
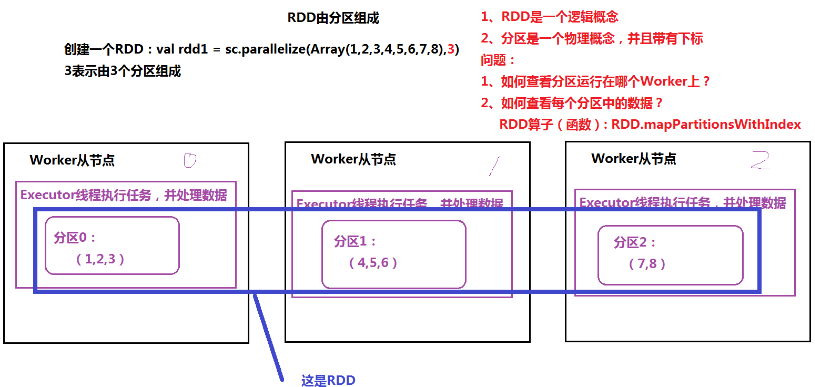
- 由分区组成,每个分区运行在不同的worker上
- 通过算子(函数)处理每个分区中的数据
- RDD之间存在依赖关系(宽依赖、窄依赖),根据依赖关系,划分任务的Stage(阶段)
创建
- 通过集合创建:SparkContext.parallelize
- 通过读取外部数据源:HDFS,本地目录
算子(函数)
- Transformation:由一个RDD生成一个新的RDD。延时加载(计算)
- map(func):对原来的RDD进行某种操作,返回一个新的RDD
- filter(func):过滤
- flatMap(func):压平,类似Map
- mapPartitions(func):对RDD中的每个分区进行操作
- sample(withReplacement, fraction, seed)
- union(otherDataset):集合操作
- distinct([numTasks]):去重
- groupByKey([numTasks]):聚合操作(分组)
- sortByKey([ascending],[numTasks]):排序(针对<key,value>)
- sortBy()
- Action:对RDD计算出一个结果
- reduce(func)
- collect():
- foreach(func):类似map,但没有返回值
缓存
- 默认将RDD的数据缓存在内存中
- 提高性能
- 表示RDD可以被缓存,函数:persist 或 cache
容错
- 检查点(Checkpoint)
- 复习:HDFS中,由SecondaryNameNode进行日志的合并
- 一种容错机制,Lineage(血统)表示任务执行的声明周期(整个任务的执行过程)
- 血统越长,出错概率越大,出错时不需要从头计算,从最近检查点的位置往后计算即可
- 命令(本地模式和集群模式操作一样):
- sc.setCheckpointDir("/root/temp/spark"):指定检查点文件保存目录
- rdd1.checkpoint:标识RDD可以生成检查点
依赖
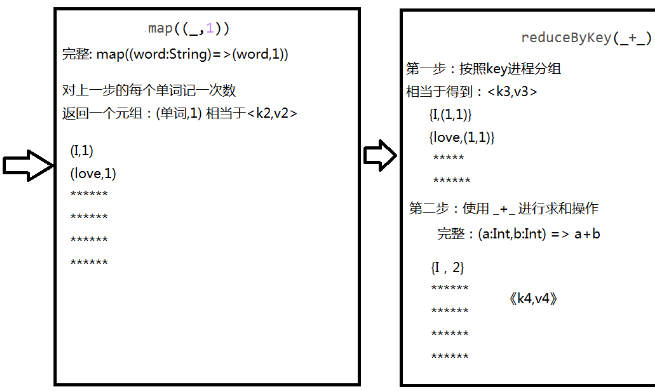
- 单步WordCount程序:
- val rdd1 = sc.textFile("/root/temp/input/data.txt")
- val rdd2 = rdd1.flatMap(_.split(" "))
- val rdd3 = rdd2.map((_,1)) 完整: val rdd3 = rdd2.map((word:String)=>(word,1) )
- val rdd4 = rdd3.reduceByKey(_+_)
- rdd4.collect
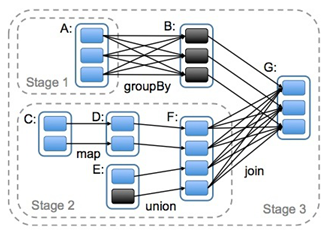
- 根据依赖关系划分任务执行的Stage(阶段)
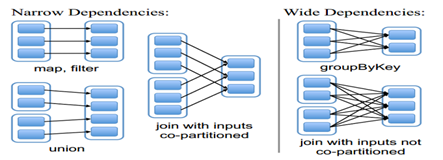
- 宽依赖(类似“超生”):多个RDD的分区依赖了同一个父RDD分区(左父右子),如groupBy
- 窄依赖(类似“独生子女”):每个父RDD分区,最多被一个RDD的分区使用,如map
- 宽依赖是划分stage的依据
参考
官方API
http://spark.apache.org/docs/2.1.0/api/scala/index.html#org.apache.spark.package