要把大象装冰箱,只需要三步。但想打开百度确需要n多步,本文讨论一下详细的步骤和其中牵扯的技术。
1、突破内网
PC在开机时就通过DHCP获取到了IP地址和DNS地址,并通过ARP获取到网关的MAC地址,以太网的二层网络中通信需要对端的MAC地址。
通过NAT将内网地址转换为公网地址。
路由器通过PPPoE拨号认证。
1.1 DHCP详细流程:
查看/释放/重获取ip地址
ipconfig /all
ipconfig /release
ipconfig /renew

DHCP是应用层协议,客户端使用UDP68端口,服务端使用67端口。
1.1.1 DHCP discover
PC发出DHCP Discover广播报文
向整个广播域内广播请求DHCP服务器(這里就是家庭路由器)的地址回复

1.1.2 DHCP Offer单播报文
DHCP服务器收到Discover数据包时,从地址池中获取一个地址,给客户端单播回复一个包含此地址的回复

1.1.3 DHCP Request广播报文
客户端接收到此地址后,向整个内网广播,告诉所有DHCP服务器自己已经做出选择,接受了某个DHCP服务器的租约。但目前还无法使用。

1.1.4 DHCP ACK单播报文
服务器接收到ACK时,向客户端回复确认,此时客户端就可以快乐的上网了。

1.2 ARP 的作用
在内网的二层环境下,需要使用MAC地址进行转发,所以需要PC和路由器都需要使用ARP将对端设备的MAC地址记录在本地的ARP表
查看/清空arp缓存
arp -a
arp –d
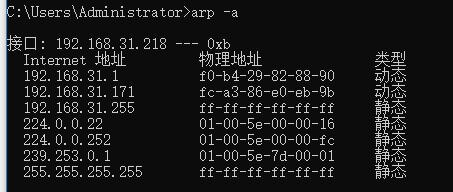

1.2.1 PC广播ARP广播报文查询网关的MAC

1.2.2 网关单播ARP报文回复

1.3 NAT地址转换
访问公网需要使用公网地址,但由于IPV4地址数量紧张,运营商只会给每户分配一个地址,想要内网中复数台终端上网就需要通过NAT技术将私网地址转换为公网地址。
这里使用的是端口复用模式。私网地址通过NAT转换为公网地址加上端口号的模式。
2、公网遨游
通过路由器后进入接入网的范围,这里数据包封装为PPPoE+QinQ模式。在BAS设备处终结。
进入传输网后,通过各种路由协议路由到百度的数据中心。
获取了百度的IP地址后,数据包就可以路由到百度的数据中心了。
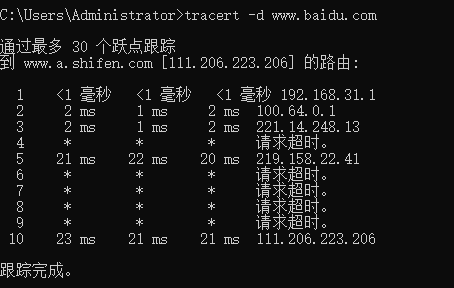
查询经过访问路径
tracert -d www.baidu.com
3、找到百度真身
虽然我们有了到达百度数据中心的能力,但是不知道百度的IP地址也没用,通过DNS获取到百度的IP地址。
DNS是应用层协议,同时使用TCP和UDP的53端口传输数据。
3.1 DNS的详细过程:
由于我们的DNS服务器地址是网关地址,所以DNS的迭代查询由路由器和其余DNS服务器交流。
3.1.1 获取百度的权威服务器地址
查看dns查询过程,查询到权威dns
dig www.baidu.com +trace
其实这些都是路由器帮我们完成的工作,但使用此命令也可以看到
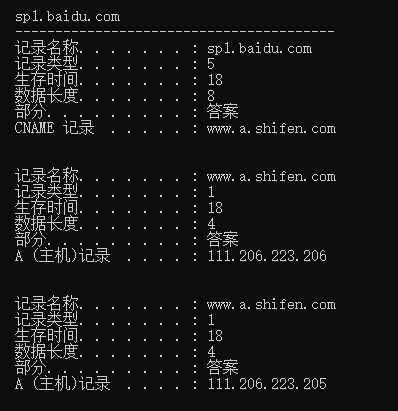
这里按照.,com.,baidu.com.的顺序查找DNS服务器,这里的回复结果全部都是各种NS记录,每个选择最快的NS记录来查找。
回复www.baidu.com的CNAME记录www.a.shifen.com,再通过这个www.a.shifen.com查找A记录,得到百度的IP
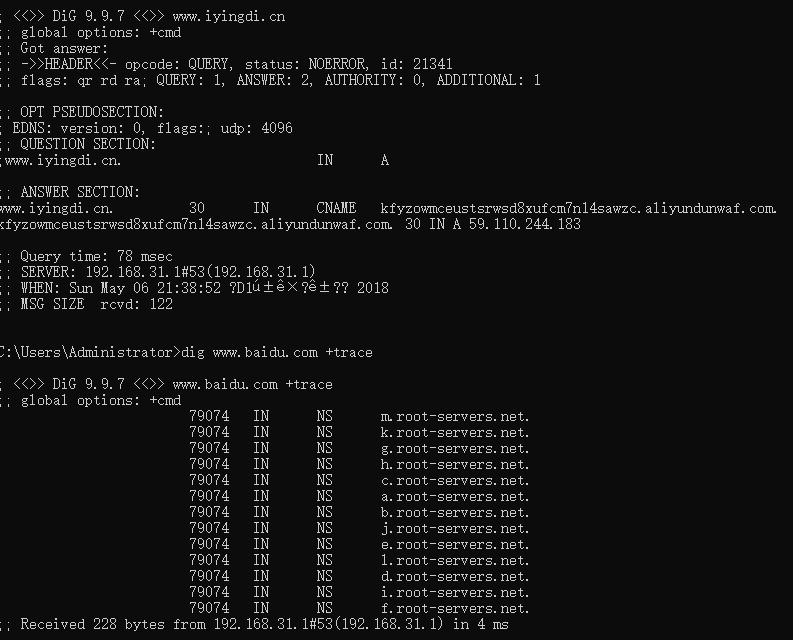
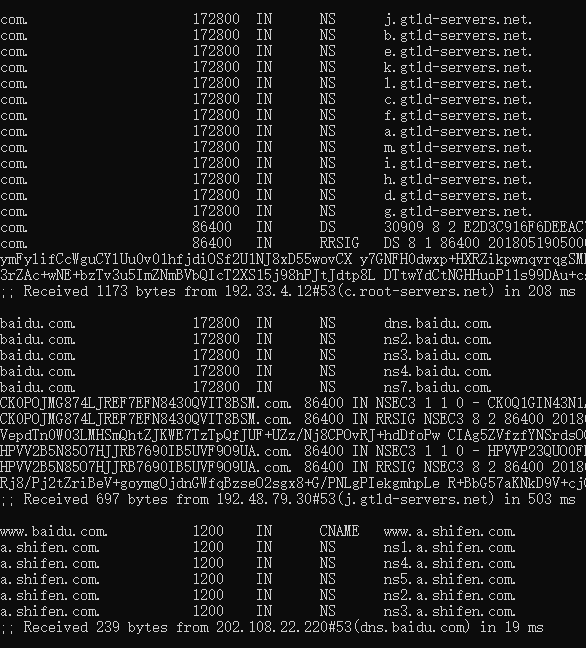
3.2 查询百度的权威服务器
获取百度的IP地址,也就是A记录,这个由PC来完成,并记录到本地的DNS缓存中。
查看/清空dns缓存
ipconfig /displaydns
ipconfig /flushdns
这里可以看到百度的CNAME,也就是别名。还有a记录,也就IP地址了
4、打开网站
通过各种设备,anti-DDOS,链路负载,防火墙,服务器负载,WAF,服务器
Web服务器:Nginx,Apache,IIS
后端:各种中间件,后端程序
和web服务器进行TCP连接TCP三次握手
http get请求
http response (HTML,CSS,JS)
和web服务器TCP四次挥手
浏览器渲染
4.1 HTTP交互数据的详细流程
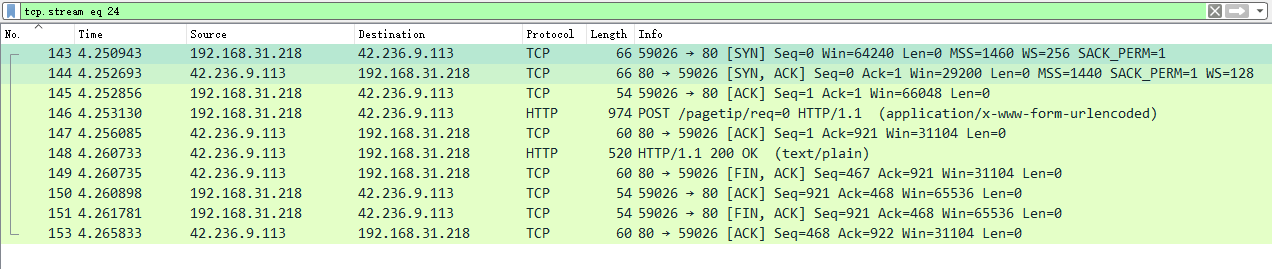
这里是POST方法获取目标站点资源的流程(由于百度现在都是HTTPS链接了,就用个别的吧,原理是一样的)。
143-145号包是TCP三次握手的包,三次握手用来建立TCP连接
146是浏览器发送HTTP POST请求的包
147是Web服务器收到146号包回复的确认包,在TCP数据传输中,收到数据包就会回复对方一个ACK包表示确认收到
148是Web服务器回复POST请求的回复包,HTTP状态码为200,表示正常回复
149-153号包是TCP四次挥手的包,四次挥手用来结束TCP连接,其中149包含了对148的ACK
至此完成了一次完成的请求过程
4.2 数据中心里的乱七八糟的设备
数据包在进入百度的数据中心后还要经过N多设备的洗礼,经过各种拆包封包后才会给到Web服务器
简单的拓扑是这样,实际中比这个还要复杂些
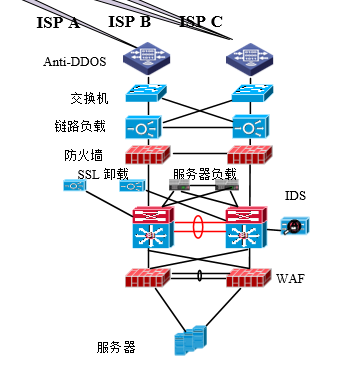
一般第一个设备就是anti-DDos设备,专门用来防御DDos攻击,当发现数据流的攻击特征后采用路由注入的方式将DDos的数据引入黑洞路由中
链路负载,负责依据客户端的源地址从相应的运营商链路中送回去
防火墙,五元组,会话的方式保护内部,主要监测下四层,限制不受欢迎的IP进入,同时做目的NAT,将内部的真实地址隐藏起来
SSL卸载,将HTTPS包解密为普通的HTTP数据包
服务器负载,引据各种算法,将数据包引流到最健壮的服务器上
IDS,即入侵检测,旁路在交换机上,检查数据包的特征指纹,判断其是否是攻击包,主要监测上三层
交换机,纯转发
WAF,在应用层面上保护web应用,防御针对web应用的攻击,防止SQL注入,框架攻击等等
4.3 服务器里面发生了什么
总算进到了服务器里面,外面硬件设备的工作暂告一段落,各种软件的工作才刚刚开始
4.3.1 Web服务器
Web服务器为每一个到来的HTTP请求开一个新的线程,来进行并发的处理
Web服务器只负责处理HTTP协议,只能发送静态页面的内容。而JSP,ASP,
PHP等动态内容需要通过CGI、FastCGI、ISAPI等接口交给各种后端程序去处理。
4.3.2 后端程序
后端程序负责处理各种逻辑,然后生成HTML文件,然后交还给Web服务器,最后再由Web服务器带上静态内容(如图片,css,js等)返回给客户端,有些数据还需要去数据库中进行操作
4.3.3 数据库
需要长期保存的数据都要保存在数据库中,在需要时由后端程序向数据库进行各种增删改查的操作,数据库将结果返回给后端程序
4.4.4 缓存
对于某些经常被访问的资源,每次都查询数据库,后端处理就很麻烦了,可以将其存入缓存中,下次再请求相同的资源就可以由Web服务器直接调用缓存中的静态资源返回给客户端
4.5 浏览器渲染
其实Web服务器返回给我们的是一堆代码和地址
是由HTML,JS,CSS和文字图片之类的构成的
右键查看源代码,这个才是我们实际收到的东西,最后由浏览器渲染成了我们看到的样子
5、总结
可以看出来简单的访问一个百度,中间经历了这么多的步骤,算上中间的每一跳转发设备,几百步总是有了,然而这么多的步骤(由于本人的水平有限,中间应该还省略了很多步骤),最终经历不过1秒钟