
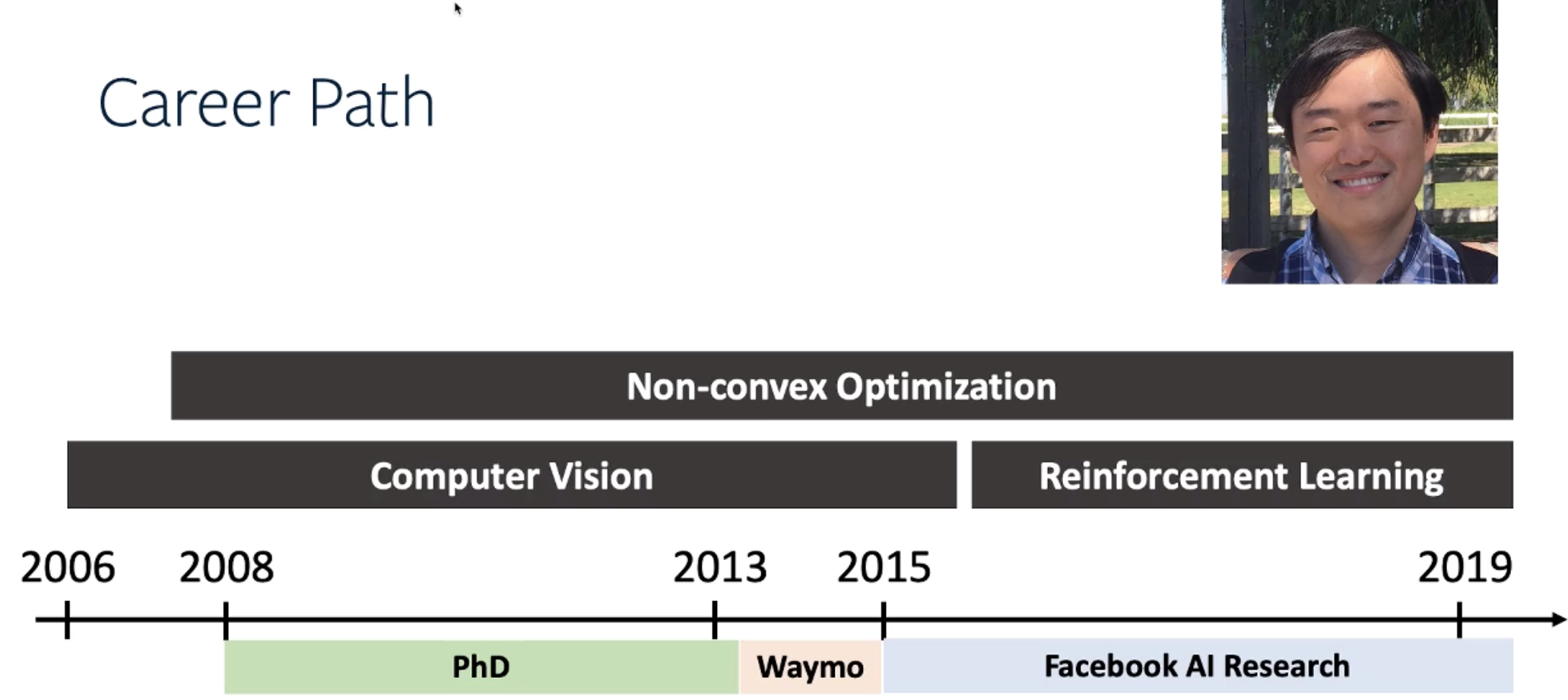
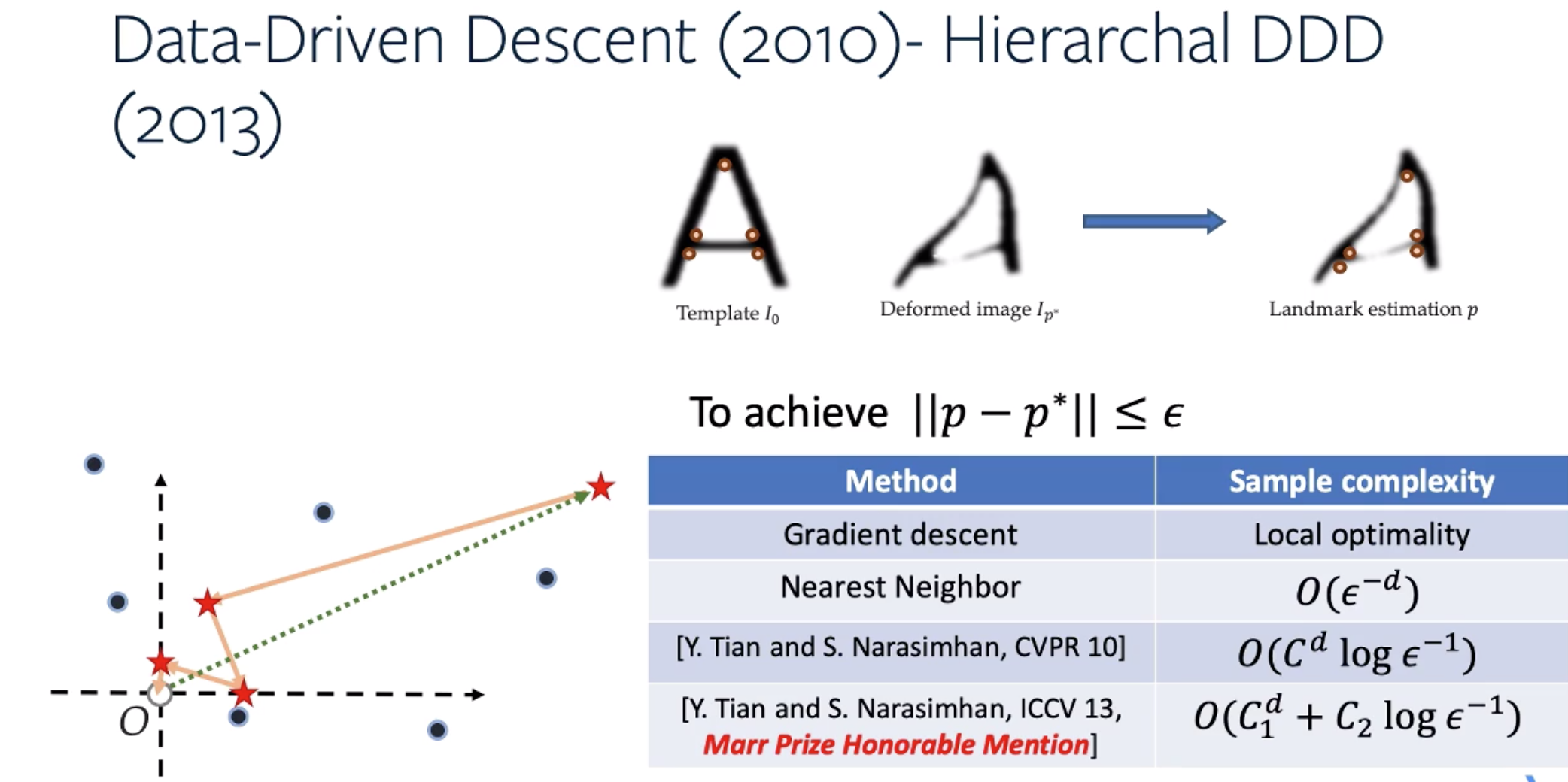
在近一小时的展示过后,田老师花了25分钟时间回答了观众提出的以下一些问题:
1. 带有复杂约束的优化问题,比如多阶段资源分配问题,数学模型约束往往比较复杂,训练过程中输出的 action 如果不满足约束,应该怎么进行处理?
2. 对于多阶段优化问题,各阶段的决策会导致决策空间在每个阶段发生变化,这部分在强化学习中要如何处理?
3. 关于决策是连续变量的优化问题,有什么好的强化学习文献和方法可以推荐?
4. 有没有可行域很稀疏的 RL 做组合优化的工作?
5. 请问用了哪些备用 heuristic?
6. 能否讲下约束不满足的处理细节?
7. VRP 可以支持约束,像时间窗吗?
8. 请问在多智体路径规划上 RL与优化如何结合?
9. 深度强化学习解决 VRP 优势体现在哪?
10. DRL 在 facebook 有落地产品么?
11. 请问怎么对每个回合得出来的网络结果进行快速评价?
12. 请问工业级的优化器怎么应对维度灾难的?
13. 现在单智能体和多智能体的算法相比效果如何?
14. 目前组合优化问题能解决多大规模的问题?
15. 请问如何处理随机参数下的组合优化问题?
16. 强化学习怎么用在设计 search 的算法中的呢?
17. RL 解组合问题的鲁棒性如何,如参数敏感性?
18. 多目标优化问题如何求解比较好呢?
19. 这个方向除了你还有那些人和组值得关注呢?
20. RL 如何应对时变环境,快速做出反应?
21. 如何看待目前 RL 理论和应用研究的 gap?