
Zookeeper和Chubby的异同点相同点:
不同点:
|
|
|
Chubby旗帜鲜明的表示自己是为分布式锁服务的,而Zookeeper则倾向于构造一个“Kernel”,而利用这个“Kernel”客户端可以自己实现众多更复杂的分布式协调机制。自然的,Chubby倾向于提供更精准明确的操作来免除使用者的负担,Zookeeper则需要提供更通用,更原子的原材料,留更多的空白和自由给Client。也正是因此,为了更适配到更广的场景范围,Zookeeper对性能的提出了更高的要求。 chubby提供分布式锁服务,对一致性有更高的要求,为强一致。 zookeeper提供分布式协调服务,为了适配更广的场景,对性能有更高的要求,牺牲了一定的一致性。 chubby:线性一致性 chubby的一致性是分布式系统中所能实现的最高的一致性,即每次操作时都可以看到其之前的所有操作按顺序完成 ZooKeeper:写操作线性(Linearizable writes) + 客户端有序(FIFO client order) 写操作线性:所有修改集群状态的操作按顺序完成 客户端有序:对任意一个client来说,它所有的读写操作按顺序完成 |
Chubby 没有开源,所以。。。

HyperTable 一个 C++ 的 BigTable 实现
Hypertable是一个开源、高性能、可伸缩的数据库,采用与Google的BigTable相似的模型。BigTable让用户可以通过一些主键来组织海量数据,并实现高效的查询。Hypertable和HBase分别是BigTable的两个开源实现:HBase主要使用Java语言开发,而Hypertable使用Boost C++,另外在一些细节的设计理念上也有所不同。
应该是已经死掉了


第5章 ZK 使用,见:《白话讲解paxos&raft算法原理及实战》
第6章:典型应用场景

我们必须寻求一种更为分布式化的解决方案







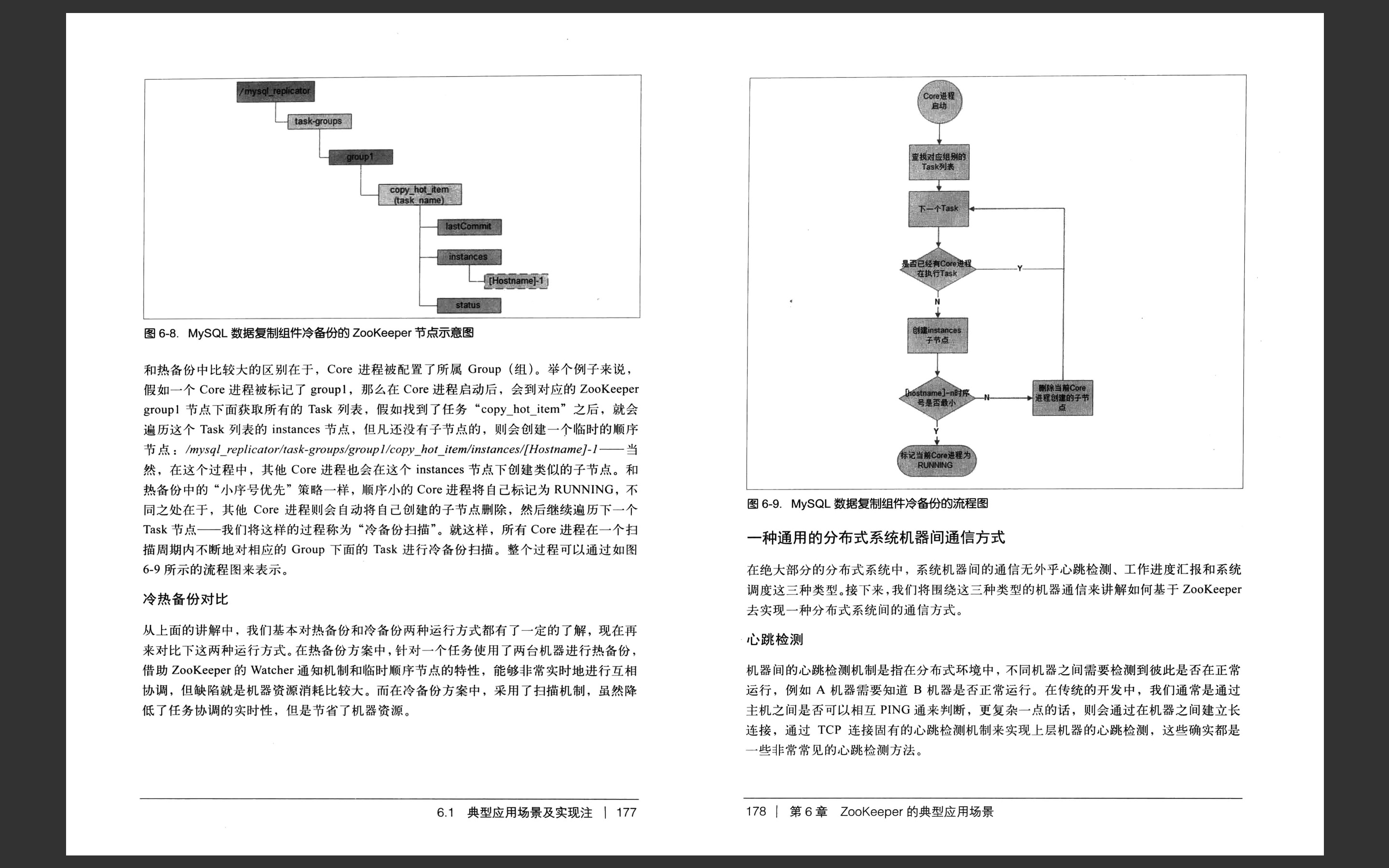




























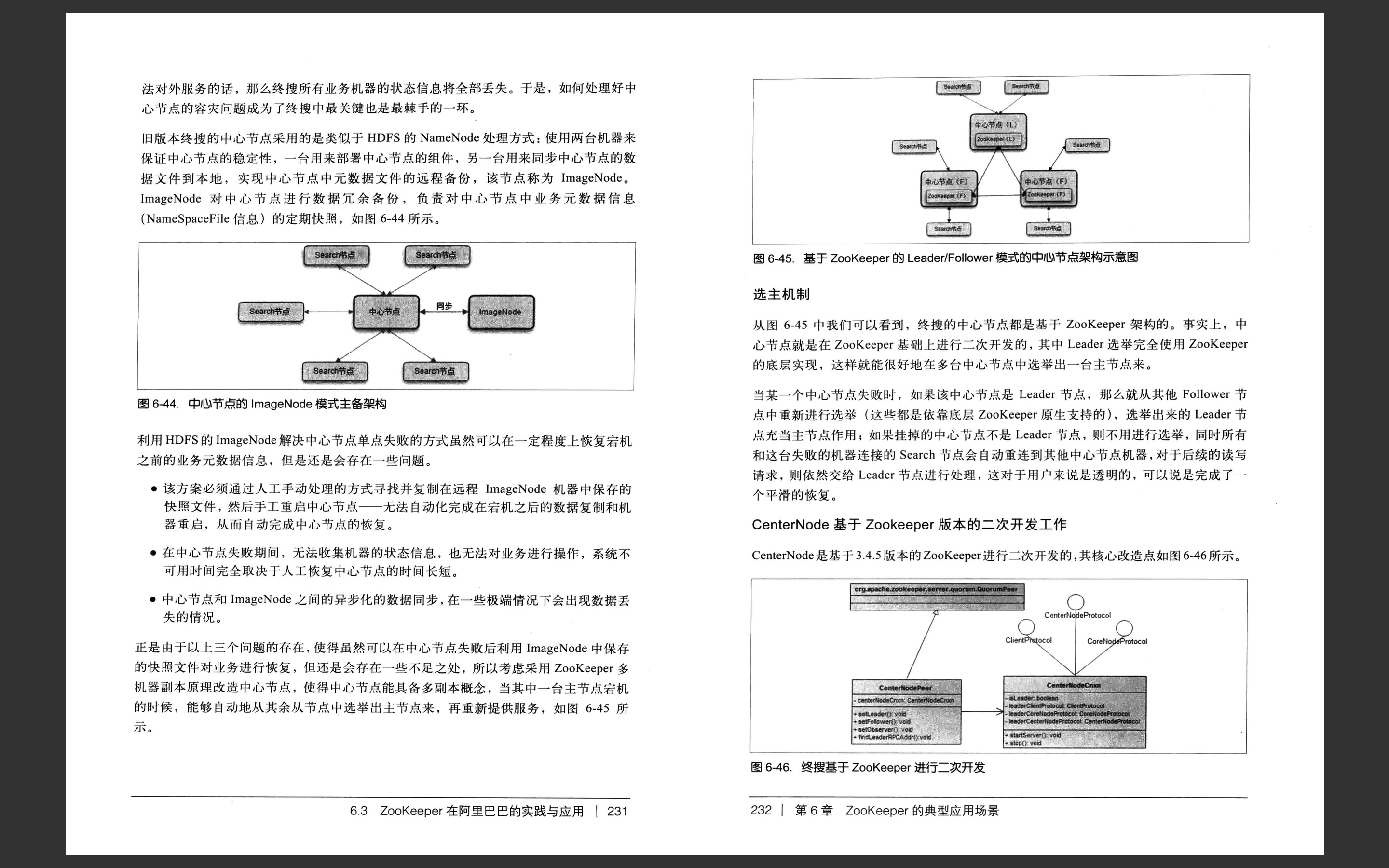





第七章:ZooKeeper 技术内幕,源码解读
第八章:ZooKeeper 运维,option 详解


