nginx 源码
|
|
||
|
Shrine 14:02
图片1(可在附件中查看) Shrine 14:02
图片2(可在附件中查看) Shrine 14:02
图片3(可在附件中查看) Shrine 14:02
图片4(可在附件中查看) Shrine 14:03
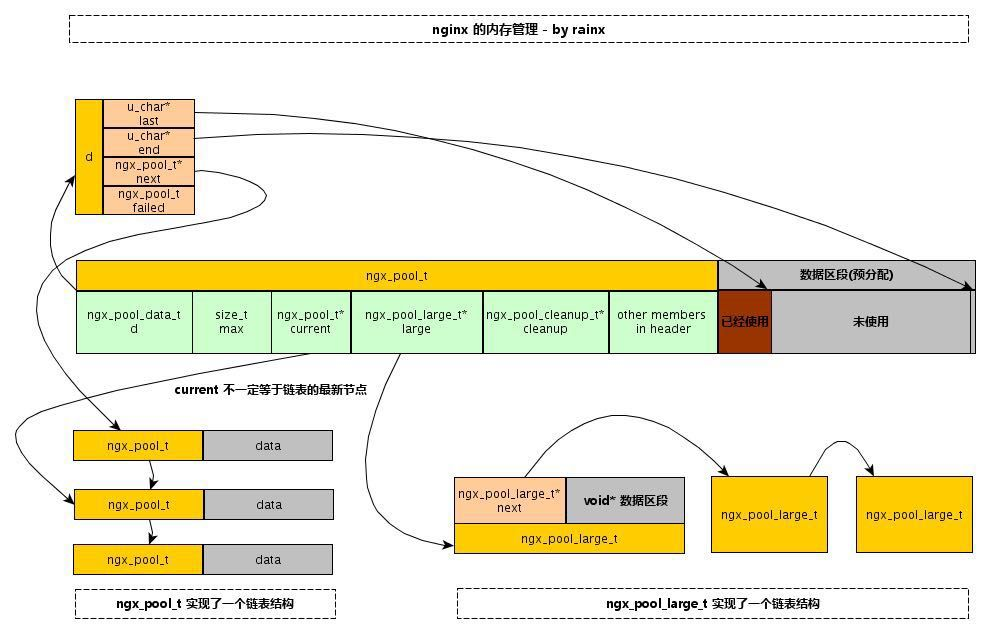
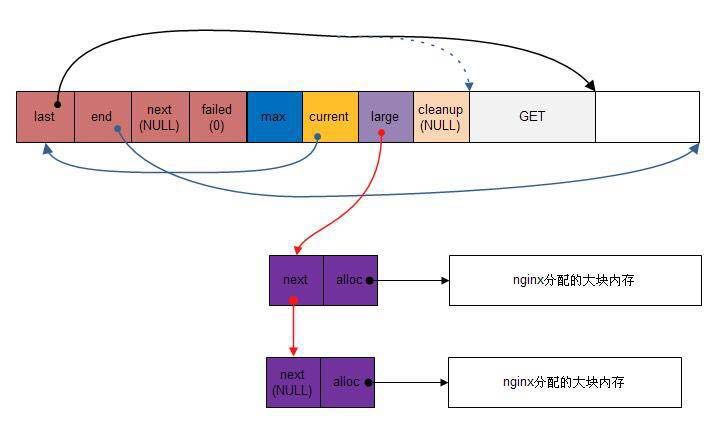
Nginx 把内存分配归结为大内存分配和小内存分配。若申请的内存大小比同页的内存池最大值 max 还大,则是大内存分配,否则为小内存分配。 大块内存的分配请求不会直接在内存池上分配内存来满足请求,而是直接向系统申请一块内存(就像直接使用 malloc 分配内存一样),然后将这块内存挂到内存池头部的 large 字段下。 小块内存分配,则是从已有的内存池数据区中分配出一部分内存。 Shrine 14:08
配置 内存管理 数据结构(基本、数组、链表、队列双向链表、哈希表、红黑树) 模块开发、源码结构 启动初始化 -> 配置解析 -> 事件模块(epoll、定时器、事件驱动模块连接处理)..HTTP模块初始化、HTTP请求处理、upstream 机制、subrequest.. 负载均衡 Shrine 14:09
图片5(可在附件中查看) 
Shrine 14:09
动态字符串 链表 字典 跳跃表 整数集合 压缩列表 Shrine 14:14
图片6(可在附件中查看) 
Shrine 14:21
Nginx 对基本数据的一种封装,包括 基本整型数据类型、字符串数据类型、缓冲区类型以及 chain 数据类型。 Shrine 14:23
图片7(可在附件中查看) 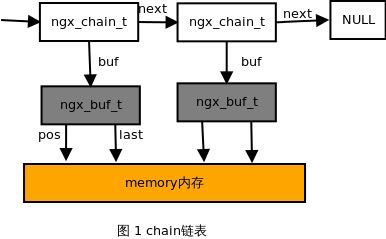
Shrine 14:24
Nginx 数组结构 ngx_array_t 概述 源码来自 src/core/ngx_array.h/.c。Nginx 源码的数组类似于《STL源码剖析——序列容器之 vector》,在 Nginx 数组中,内存分配是基于内存池的,并不是固定不变的,也不是需要多少内存就申请多少,若当前内存不足以存储所需元素时,按照当前数组的两倍内存大小进行申请,这样做减少内存分配的次数,提高效率。 Shrine 14:24
图片8(可在附件中查看) 
Shrine 14:25
创建新的动态数组: 首先分配数组头,然后分配数组数据区,两次分配均在传入的内存池(pool指向的内存池)中进行。然后简单初始化数组头并返回数组头的起始位置。 Shrine 14:25
销毁动态数组 包括销毁数组数据区和数组头。销毁动作实际上就是修改内存池的 last 指针,即数组的内存被内存池回收,并没有调用 free 等释放内存的操作。 Shrine 14:26
添加元素操作 数组添加元素的操作有两个,ngx_array_push 和ngx_array_push_n,分别添加一个和多个元素。实际的添加操作并不在这两个函数中完成,只是在这两个函数中申请元素所需的内存空间,并返回指向该内存空间的首地址,在利用指针赋值的形式添加元素。 Shrine 14:27
Nginx 链表结构 ngx_list_t 链表结构 ngx_list_t 是 Nginx 封装的链表容器,链表容器内存分配是基于内存池进行的,操作方便,效率高。Nginx 链表容器和普通链表类似,均有链表表头和链表节点,通过节点指针组成链表。 Shrine 14:27
图片9(可在附件中查看) 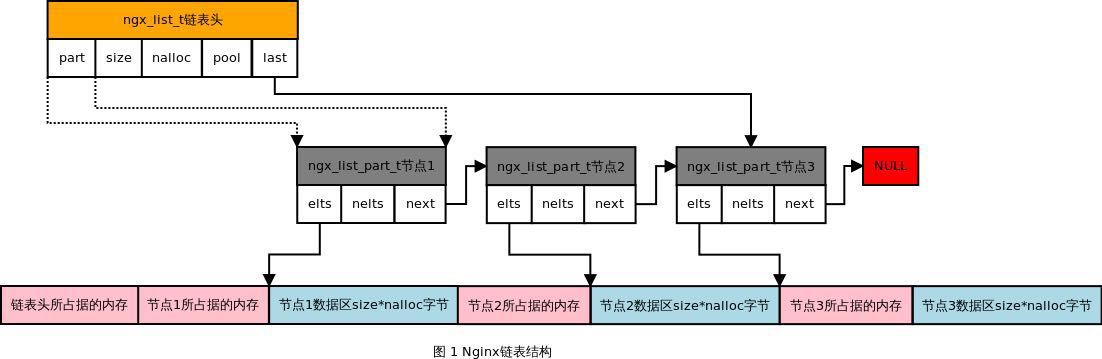 Shrine 14:30
Nginx 队列双向链表结构 ngx_queue_t 队列链表结构 队列双向循环链表实现文件:文件:src/core/ngx_queue.h/.c。在 Nginx 的队列实现中,实质就是具有头节点的双向循环链表,这里的双向链表中的节点是没有数据区的,只有两个指向节点的指针。需注意的是队列链表的内存分配不是直接从内存池分配的,即没有进行内存池管理,而是需要我们自己管理内存,所有我们可以指定它在内存池管理或者直接在堆里面进行管理,最好使用内存池进行管理。 Shrine 14:31
Nginx 哈希表结构 ngx_hash_t 哈希表结合了数组和链表的特点,使其寻址、插入以及删除操作更加方便。哈希表的过程是将关键字通过某种哈希函数映射到相应的哈希表位置,即对应的哈希值所在哈希表的位置。但是会出现多个关键字映射相同位置的情况导致冲突问题,为了解决这种情况,哈希表使用两个可选择的方法:拉链法和 开放寻址法。 Nginx 的哈希表中使用开放寻址来解决冲突问题,为了处理字符串,Nginx 还实现了支持通配符操作的相关函数,下面对 Nginx 中哈希表的源码进行分析。源码文件:src/core/ngx_hash.h/.c。 Shrine 14:33
哈希算法有多种,最常用的就是开放定址法和开链法(哈希桶),之后又有公共溢出区等等算法。 Shrine 14:33
图片10(可在附件中查看) 
Shrine 14:34
图片11(可在附件中查看) Shrine 14:37
红黑树和AVL树类似,都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。 它虽然是复杂的,但它的最坏情况运行时间也是非常良好的,并且在实践中是高效的: 它可以在O(log n)时间内做查找,插入和删除,这里的n 是树中元素的数目。 Shrine 15:16
图片12(可在附件中查看) 
Shrine 15:16
图片13(可在附件中查看) 
Shrine 15:33
图片14(可在附件中查看) 
Shrine 15:35
图片15(可在附件中查看) 
Shrine 15:36
Nginx 源码的模块化结构 根据各模块的功能,可把 Nginx 源码划分为以下几种功能,如下图所示: 核心模块功能:为其他模块提供一些基本功能:字符串处理、时间管理、文件读写等功能; 配置解析:主要包括文件语法检查、配置参数解析、参数初始化等功能; 内存管理:内存池管理、共享内存的分配、缓冲区管理等功能; 事件驱动:进程创建与管理、信号接收与处理、所有事件驱动模型的实现、高级 IO 等功能; 日志管理:错误日志的生成与管理、任务日志的生成与管理等功能; HTTP 服务:提供 Web 服务,包括客户度连接管理、客户端请求处理、虚拟主机管理、服务器组管理等功能; Mail 服务:与 HTTP 服务类似,但是增加了邮件协议的实现; Shrine 15:40
ngx_radix_tree_t基数树与ngx_rbtree_t红黑树一样都是二叉查找树,ngx_rbtree_t红黑树具备的优点,ngx_radix_tree_t基数树同样也有,但ngx_radix_tree_t基数树的应用范围要比ngx_rbtree_t红黑树小,因为ngx_radix_tree_t要求元素必须以整型数据作为关键字,所以大大减少了它的应用场景。然而,由于ngx_radix_tree_t基数树在插入、删除元素时不需要做旋转操作,因此它的插入、删除效率一般要比ngx_rbtree_t红黑树高。选择使用哪种二叉查找树取决于实际的应用场景。不过,ngx_radix_tree_t基数树的用法要比ngx_rbtree_t红黑树简单许多。 Shrine 15:40
基数树也是一种二叉查找树,然而它却不像红黑树一样应用广泛(目前官方模块中仅geo模块使用了基数树)。这是因为ngx_radix_tree_t基数树要求存储的每个节点都必须以32位整型作为区别任意两个节点的唯一标识,而红黑树则没有此要求。ngx_radix_tree_t基数树与红黑树不同的另一个地方:ngx_radix_tree_t基数树会负责分配每个节点占用的内存。因此,每个基数树节点也不再像红黑树中那么灵活——可以是任意包含ngx_rbtree_node_t成员的结构体。基数树的每个节点中可以存储的值只是1个指针,它指向实际的数据。 ngx_radix_tree.c Shrine 16:10
函数定义 ngx_int_t ngx_output_chain(ngx_output_chain_ctx_t *ctx, ngx_chain_t *in) 函数目的是发送 in 中的数据,ctx 用来保存发送的上下文,因为发送通常情况下,不能一次完成。nginx 因为使用了 ET 模式,在网络编程事件管理上简单了,但是编程中处理事件复杂了,需要不停的循环做处理;事件的函数回调,次数也不确定,因此需要使用 context 上下文对象来保存发送到什么环节了。 http proxy 模块,依赖 http upstream 模块,ngx_http_upstream_send_request 函数会调用 ngx_output_chain 函数发送 client 请求的数据给后端的 server,调用如下: rc = ngx_output_chain(&u->output, u->request_sent ? NULL : u->request_bufs); u->request_bufs 是 client 请求的数据 Shrine 16:14
共享内存是Linux下提供的最主要的进程通信方法。它通过mmap或者shmget系统调用在内存中创建了一块连续的线性地址空间。而通过munmap或者shmdt系统调用释放这块内存,使用共享内存的优点是多个进程使用同一块内存时,在不论什么一个进程改动了共享内存中的内容后,其他进程通过訪问这段内存就行得到内存变化。 头文件:http://trac.nginx.org/nginx/browser/nginx/src/core/ngx_shmtx.h 源文件:http://trac.nginx.org/nginx/browser/nginx/src/core/ngx_shmtx.c Shrine 16:14
[菜鸟nginx源代码剖析数据结构篇(十一) 共享内存ngx_shm_t - wgwyanfs - 博客园 : https://www.cnblogs.com/wgwyanfs/p/6871713.html] Shrine 16:17
nginx中slab的亮点: 1.使用pre的后两位,用于标记page页面的类型 2.充分利用计算机的2进制特点,代码中充斥着位移,效率非常高. 3.构造小的内存块用于存储对象,这样就不会产生内存碎片.我对内存碎片的理解:内存碎片是指由于频繁的分配和回收内存,使得可用的单个内存块的大小总体上总是逐渐减小,无法合并相邻两块处于free状态的内存块,这样就产生了碎片.而slab算法不会产生内存碎片,即不会将整块内存逐渐分割,他总是可以直接定位内存块,直接使用,使用完成后将内存块设置为未使用状态即可,并不是使用完成后将该块内存放入链表中,等待下次分割或者直接使用. --------------------- Shrine 16:17
[nginx slab 机制 - simply the best - CSDN博客 : https://blog.csdn.net/u013009575/article/details/17743261] Shrine 16:19
slab是Linux操作系统的一种内存分配机制。其工作是针对一些经常分配并释放的对象,如进程描述符等,这些对象的大小一般比较小,如果直接采用伙伴系统来进行分配和释放,不仅会造成大量的内存碎片,而且处理速度也太慢。而slab分配器是基于对象进行管理的,相同类型的对象归为一类(如进程描述符就是一类),每当要申请这样一个对象,slab分配器就从一个slab列表中分配一个这样大小的单元出去,而当要释放时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免这些内碎片。slab分配器并不丢弃已分配的对象,而是释放并把它们保存在内存中。当以后又要请求新的对象时,就可以从内存直接获取而不用重复初始化。 slab分配算法采用cache 存储内核对象。当创建cache 时,起初包括若干标记为空闲的对象。对象的数量与slab的大小有关。开始,所有对象都标记为空闲。当需要内核数据结构的对象时,可以直接从cache 上直接获取,并将对象初始化为使用。 Shrine 16:20
内存池和SLAB分配器有什么区别呀,在用法上 最近看到这两个内存分配方式,有点迷惑 内核中经常需要申请大量的相同类型的较小数据结构的内存,例如skb、urb 这样容易出现内存碎片 使用SLAB预先分配一片空间专门用来给这类数据结构使用,能够提高申请和回收速度,减少内存碎片 SLAB适合于大量的、细小的数据结构的内存申请的情况 内存池,大多用于块设备,如文件系统 在处理大量的数据时,可能内核可用的内存不足,使用内存池预先申请一块内存 这样使用内存池api mempool_alloc,首先尝试alloc_fn ,如果失败就从内存池中获取预分配的内存,能够保证 mempool_alloc一定申请成功,不会陷入睡眠(当然预分配的内存没有了,也会睡眠)。 Shrine 16:24
[Linux入门之extext2ext3ext4的介绍与区别 : https://blog.csdn.net/weixin_39212776/article/details/81016007?from=singlemessage&isappinstalled=0] Shrine 16:25
[Ext2 v.s. Ext3 v.s. Ext4 性能比拼 : https://blog.csdn.net/onlyonename/article/details/8078956] Shrine 16:25
[Ext2 v.s. Ext3 v.s. Ext4 性能比拼_Linux社区_酷勤网 : http://www.kuqin.com/linux/20090202/33777.html] Shrine 16:26
图片16(可在附件中查看) 
Shrine 16:26
所有事件模块的配置项管理 Nginx 服务器在结构体 ngx_cycle_t 中定义了一个四级指针成员 conf_ctx,整个Nginx 模块都是使用该四级指针成员管理模块的配置项结构 Shrine 16:28
图片17(可在附件中查看) 
Shrine 16:29
Nginx 定时器事件 概述 在 Nginx 中定时器事件的实现与内核无关。在事件模块中,当等待的事件不能在指定的时间内到达,则会触发Nginx 的超时机制,超时机制会对发生超时的事件进行管理,并对这些超时事件作出处理。对于定时事件的管理包括两方面:定时事件对象的组织形式 和 定时事件对象的超时检测。 定时事件的组织 Nginx 的定时器由红黑树实现的。在保存事件的结构体ngx_event_t 中有三个关于时间管理的成员 Shrine 16:32
Nginx 事件驱动模块连接处理 概述 由于 Nginx 工作在 master-worker 多进程模式,若所有 worker 进程在同一时间监听同一个端口,当该端口有新的连接事件出现时,每个worker 进程都会调用函数ngx_event_accept 试图与新的连接建立通信,即所有worker 进程都会被唤醒,这就是所谓的“惊群”问题,这样会导致系统性能下降。幸好在Nginx 采用了ngx_accept_mutex 同步锁机制,即只有获得该锁的worker 进程才能去处理新的连接事件,也就在同一时间只能有一个worker 进程监听某个端口。虽然这样做解决了“惊群”问题,但是随之会出现另一个问题,若每次出现的新连接事件都被同一个worker 进程获得锁的权利并处理该连接事件,这样会导致进程之间不均衡的状态,即在所有worker 进程中,某些进程处理的连接事件数量很庞大,而某些进程基本上不用处理连接事件,一直处于空闲状态。因此,这样会导致worker 进程之间的负载不均衡,会影响Nginx 的整体性能。为了解决负载失衡的问题,Nginx 在已经实现同步锁的基础上定义了负载阈值ngx_accept_disabled,当某个worker 进程的负载阈值大于 0 时,表示该进程处于负载超重的状态,则Nginx 会控制该进程,使其没机会试图与新的连接事件进行通信,这样就会为其他没有负载超重的进程创造了处理新连接事件的机会,以此达到进程间的负载均衡。 Shrine 16:33
图片18(可在附件中查看) 
Shrine 16:35
ngx_http_[module-name]_[main|srv|loc]_conf_t。 main,srv,loc表示这个模块的作用范围是配置文件中的main/server/location三种范围 Shrine 16:39
event 事件驱动模型结构 event 目录里面包含一种子目录 module 以及一些文件,除了 module 子目录,其他文件提供了事件 驱动模型相关数据结构的定义、初始化、事件接收、传递、管理功能以及事件驱动模型调用功能。module 子目录里面的源码实现了Nginx 支持的事件驱动模型:AIO、epoll、kqueue、select、/dev/poll、poll 等事件驱动模型; 选择事件模型 # 语法格式:use [kqueue | rtisg | epoll | /dev/poll | select | poll | eventport]; Nginx 的核心是选择事件模型 数据结构、配置、处理流程啥的都只是实现 把几个IO多路复用的事件处理模型搞清楚才是正儿八经 Shrine 16:49
图片19(可在附件中查看) 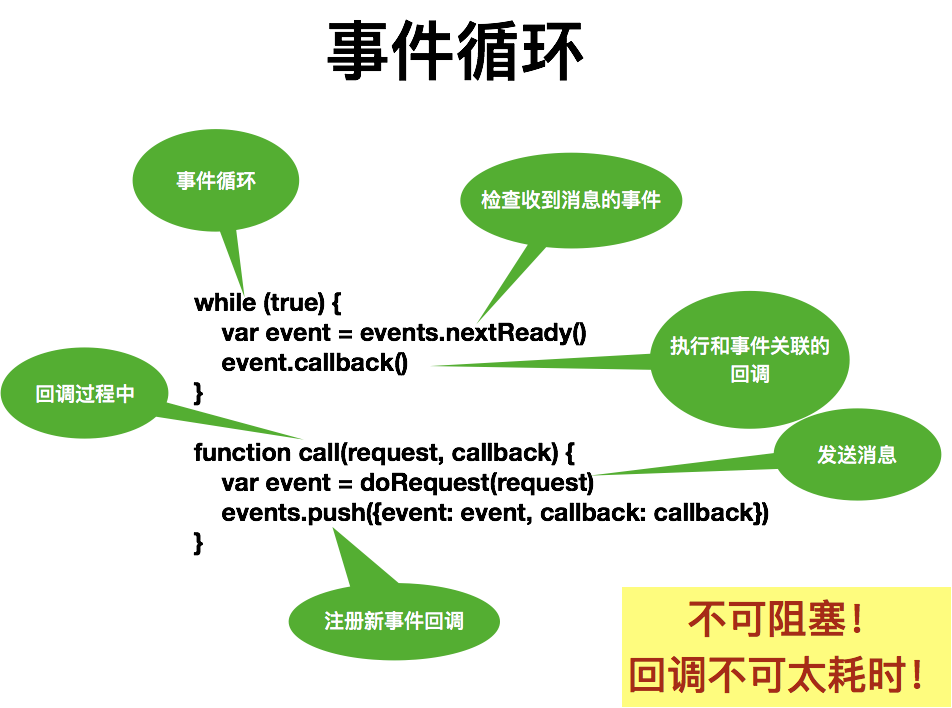
Shrine 16:51
图片20(可在附件中查看) 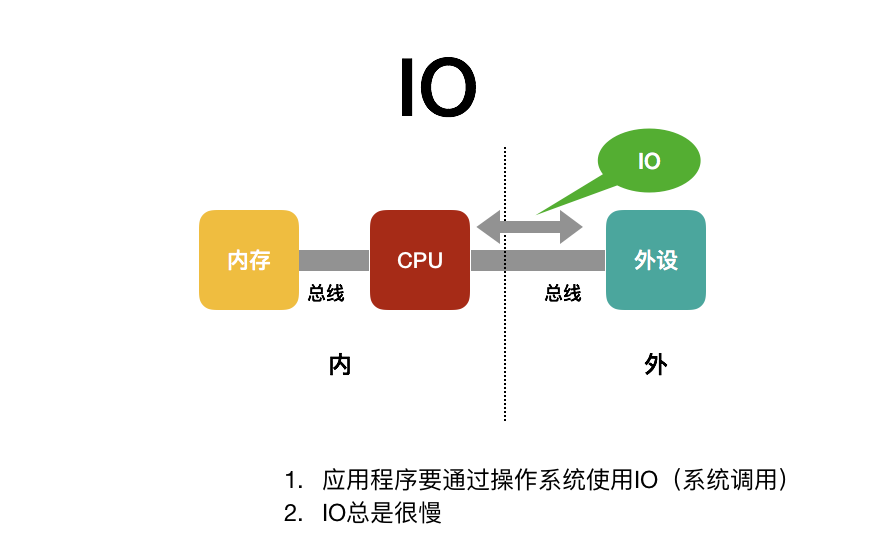
Shrine 16:51
图片21(可在附件中查看) 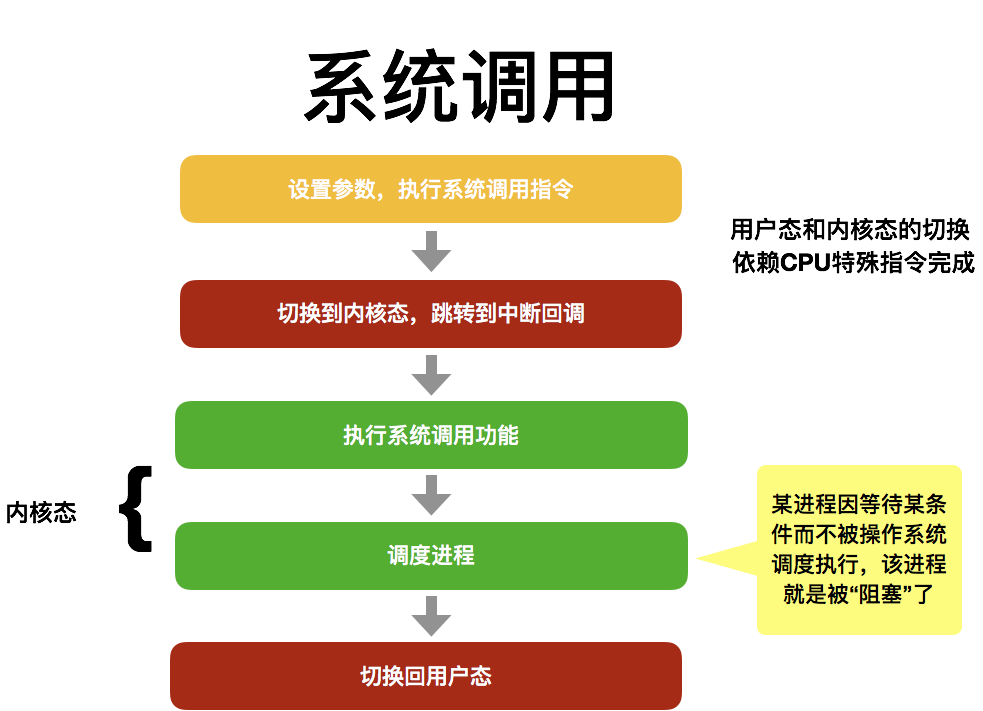
Shrine 16:51
图片22(可在附件中查看) 
Shrine 16:52
图片23(可在附件中查看) 
Shrine 16:52
图片24(可在附件中查看) 
Shrine 16:52
图片25(可在附件中查看) 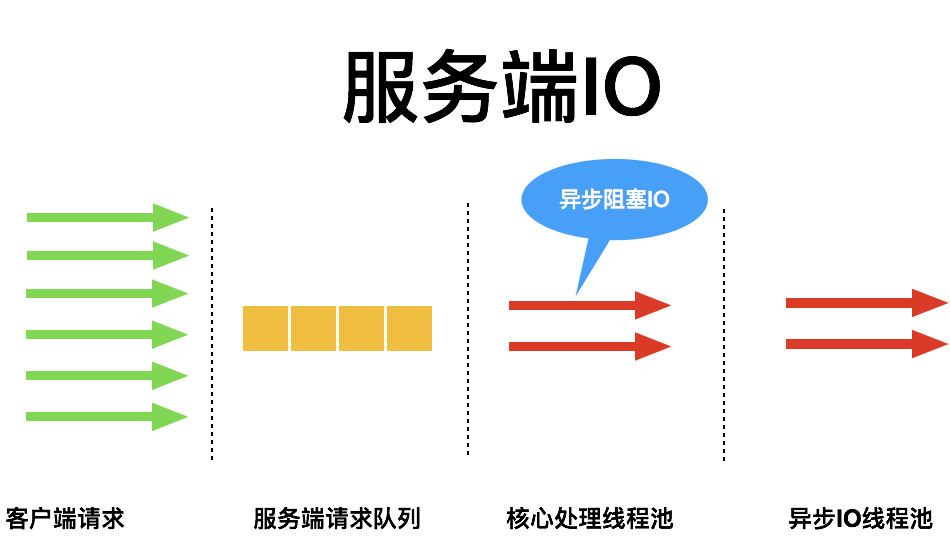
Shrine 16:53
图片26(可在附件中查看) 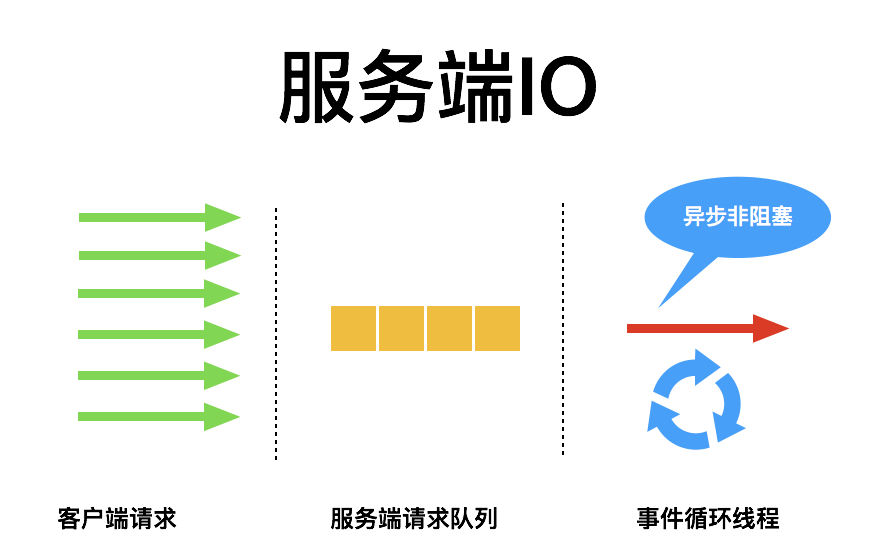
Shrine 16:53
图片27(可在附件中查看) 
Shrine 16:53
图片28(可在附件中查看) 
Shrine 16:54
图片29(可在附件中查看) 
Shrine 16:54
图片30(可在附件中查看) 
Shrine 16:54
图片31(可在附件中查看) 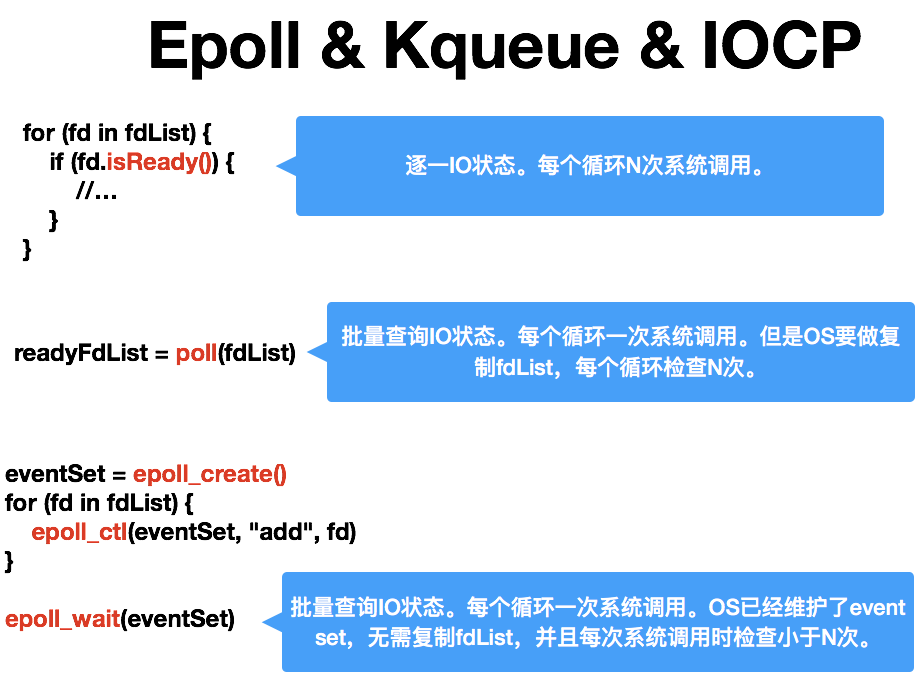
Shrine 16:55
Epoll使nginx打败了apache Java NIO底层也采用epoll Epoll + v8 = nodejs Epoll使事件循环得以真正大规模采用 Shrine 16:55
Epoll使nginx打败了apache nginx 的核心是 epoll —— 这是本质 Shrine 16:56
select,poll,epoll都是IO多路复用的机制。I/O多路复用就通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。 Shrine 16:57
[select、poll、epoll之间的区别(搜狗面试) - aspirant - 博客园 : https://www.cnblogs.com/aspirant/p/9166944.html] |




1/17
- P202-nginx的简介
- P303-nginx相关概念(正向和反向代理)
- P404-nginx相关概念(负载均衡和动静分离)
- P505-nginx在linux系统安装
- P606-nginx常用的命令
- P707-nginx的配置文件
- P808-nginx配置实例(反向代理准备工作)
- P909-nginx配置实例(反向代理实例一)
- P1010-nginx配置实例(反向代理实例二)
- P1111-nginx配置实例(负载均衡)
- P1212-nginx配置实例(动静分离准备工作)
- P1313-nginx配置实例(动静分离)
- P1414-nginx配置实例(高可用准备工作)
- P1515-nginx配置实例(高可用主备模式)
- P1616-nginx配置实例(高可用配置文件详解)
- P1717-nginx的原理解析
1/23
- P202-nginx信号量
- P303-nginx虚拟主机配置
- P404-nginx日志管理
- P505-nginx定时任务完成日志切割
- P606-Location详解之精准匹配
- P707-Location之正则匹配
- P808-Location总结图解
- P909-nginx Rewrite语法详解
- P1010-编译PHP并与nginx整合
- P1111-安装ecshop
- P1212-商城url重写实战
- P1313-nginx gzip压缩提升网站速度
- P1414-expires缓存提升网站负载
- P1515-反向代理实现nginx+apache动静分离
- P1616-nginx实现负载均衡
- P1717-nginx连接memcached
- P1818-第3方模块编译及一致性哈希应用
- P1919-大访问量优化整体思路
- P2020-ab压力测试及nginx性能统计模块
- P2121-nginx单机1W并发优化
- P2222-服务器集群搭建
- P2323-集群性能测试
-
04:02:25
 这么多人啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊的2020-5-28阳哥SpringCloud的过来的后端正在看2020 6.3 运维路过还dubbo?我还feign呢有没有学php的大牛我只想用nginx解决一个前端跨域问题30人正在看2020-06-09hello ,大家好呀2倍速的有没有16个人?24 人2020-06-12第二个要发布项目了,过来学习下
这么多人啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊的2020-5-28阳哥SpringCloud的过来的后端正在看2020 6.3 运维路过还dubbo?我还feign呢有没有学php的大牛我只想用nginx解决一个前端跨域问题30人正在看2020-06-09hello ,大家好呀2倍速的有没有16个人?24 人2020-06-12第二个要发布项目了,过来学习下 -
13:31:58
 2013年的視頻?走了
2013年的視頻?走了 -
03:25:22
 tomcat前端路过这么多人吗2050年了这个视频用来学习可以么这打字水平 看的人难受172020-4-15有个屁好奇大哥哪里人啊,莫名同步了ffff15:53贾老师哈哈7777俄罗斯网络环境问题哈哈哈哈17年年末的内存条谁借我个耳机啊月薪过万,别做梦了。。
tomcat前端路过这么多人吗2050年了这个视频用来学习可以么这打字水平 看的人难受172020-4-15有个屁好奇大哥哪里人啊,莫名同步了ffff15:53贾老师哈哈7777俄罗斯网络环境问题哈哈哈哈17年年末的内存条谁借我个耳机啊月薪过万,别做梦了。。 -
18:37:15
 怎么缓存好尴尬啊bat这种带公司肯定会被一些信息隐藏不想给你知道啥哇!!!Server:BWS/1.1bws啊哈哈哈,找半天没看到bwsNG正向代理——梯子1.5倍速1.5倍速刚刚好
怎么缓存好尴尬啊bat这种带公司肯定会被一些信息隐藏不想给你知道啥哇!!!Server:BWS/1.1bws啊哈哈哈,找半天没看到bwsNG正向代理——梯子1.5倍速1.5倍速刚刚好 -
03:00:21

-
13:31:58

-
25:21

-
19:10

-
03:36:50

-
06:28:09

-
10:03:31

-
03:51:52
-
04:03:06

-
04:03:06

-
13:31:58

-
05:33:40

-
46:55

-
16:04:49

-
39:53

-
05:08
-
...